

June 27, 2019
Inside Jeff Jonas’ Big Plan to Democratize Entity Resolution

(FastMotion/Shutterstock)
Jeff Jonas is no stranger to entity resolution. The data scientist has implemented hundreds of ER systems over the decades – starting with banks and casinos in the 1980s and 1990s and for intelligence agencies and charitable institutions in the 2000s and 2010s. Since being spun out of IBM three years ago, Jonas has cooked up some big plans to bring industrial-strength, AI-powered ER to the developer masses with his new software firm, Senzing.
Entity resolution – or the process of positively or negatively linking records or observations about entities (people or things) – isn’t the sexiest topic when it comes to big data and AI, or even programming in general. To many, ER is the relatively unexciting task of removing duplicates in a database. In data science, it may be viewed as part of the “data janitorial” work that has to be done before the data scientist can get to the fun stuff: playing with algorithms and building models!
But that perspective does a disservice to ER as a discipline in its own right, and neglects the real value that ER can bring to those who get it right. As companies, organizations, and governments continue to collect and process big data and connect that data to customers, employees, and citizens, ER will continue to pose technical challenges to those who struggle, and benefits to those who master it.
Jonas understands this dynamic, and is confident that Senzing’s offering can help simplify ER and remove some of the mystery that surrounds the practice.
Resolving Jeff Jonas

Senzing founder and CEO Jeff Jonas (Photo courtesy Jeff Jonas)
Jonas saw his first computer, a Tandy TRS-80, when he was 14 and growing up in Healdsburg, California, and he has been hooked by the bug ever since.
After his first computer company went bankrupt in the early 1980s, he headed south to Las Vegas, where he was hired to write a program to optimize fish living in the giant aquarium being built in The Mirage casino. These early years were chronicled by National Geographic magazine, which labeled Jonas the “Wizard of Big Data” in a 2014 story.
Eventually, Jonas founded his own company, called Systems Research and Development, which was based in Las Vegas. Jonas and his SRD team developed Non-Obvious Relationship Awareness (NORA), which matches identities and finds relationships among different people.
The NORA system would be instrumental in identifying the individuals involved in the notorious card-counting ring from MIT that won millions of dollars at Vegas blackjack tables. (Card-counting isn’t strictly illegal, but it’s strongly discouraged by Vegas casinos.)
After two rounds of funding from In-Q-Tel, the CIA’s venture capital arm, IBM acquired SRD in 2005 for an undisclosed sum. Jonas, who would be named an IBM Fellow and Chief Scientist of Context Computing, helped integrate NORA into IBM’s Identity Insight, a suite of products used for entity resolution and finding relationships among people and things.
In 2009, Jonas had an idea. He noted that implementing an ER system had become a heavy lift, with a minimum investment of $1 million for a company to get going with hardware, software, and services. Many companies had spent several million dollars on ER systems. ER systems were just for the elite, outside the reach of average organizations.
That idea gave rise to G2, which Jonas developed at IBM. “I told IBM it might take $50 million to build something, but it would self-correcting,” he told Datanami in a recent interview. “It would be an AI. We didn’t use AI to build it. We invented an AI just to do entity resolution.”
G2, as the new AI-based ER engine was called, started shipping it in 2012. It’s been used in a variety of ways since then, including for a project last year to identify eligible voters who haven’t registered, which earned him a New York Times profile last November. The Singaporean government also used G2 to build a maritime domain awareness system that identifies vessels in the Malacca Strait.
Senzing Spin Out
In August 2016, IBM spun out Jonas and his team and created Senzing, which has a license with IBM to distribute the G2 engine within its Senzing ER offering.![]()
According to Jonas, the company is 100% focused on making ER a much simpler — and less expensive — task than it has been.
“We realized that our specialty wasn’t a graph thing, not case management, not ETL,” he said. “Our specialty is just the entity resolution. We just made a library so people can download it and try it. It’s turning this complicated task of entity resolution into a mundane function. You just call a function and drop in a name and address and email and date of birth and have entity resolution. No training, no tuning, no experts.”
Senzing’s mission is to democratize ER, he said. “There are 50 companies out there doing entity resolution,” he said. “For the most part, they’re trying to make a lot of money from a few companies. They’re for the elite. We’re trying to make it available for everybody.”
Jonas is so adamant about the “available for everybody” part that he allows the Senzing ER product to be freely downloaded and used to resolve entities on datasets of 10,000 records or fewer. Customers with bigger production needs can buy a subscription according to how many records they need to resolve. For 50,000 records, the cost is just $5 per month.
The Senzing ER software supports all major databases. Running on a single commodity server, the software can handle up to 400 million records and resolve millions of entities every day in real time with sub-second response rates, according to a company white paper. For larger needs, the software scales vertically on big SMP boxes or scales horizontally on clustered or sharded configurations.
AI Built In
Besides the fact that it’s free to start, there are a few other features that make Senzing unique among ER offerings.

Senzing ER’s “sequence neutrality” enables it to correct past decisions when better data arrives later in time
First, it’s self-learning, in an unsupervised manner. With most ER systems, the software requires lots of labeled data, and the algorithms run in a supervised manner, Jonas said. But Senzing ER is capable of looking at data and automatically finding correlations. It can even pick out nicknames and spot common typographical errors, according to the company.
“We’re definitely the first real-time AI for entity resolution,” Jonas said. “It is self-training and self-correcting. You don’t have to train it and tune it. You don’t need millions and millions of records. It will work on two records. Get to hundreds of billions of records, it just gets smarter and smarter.”
The software also has anomaly detection built in. So if it runs into “garbage values,” such as a Social Security Number 121212121, it can identify it as such and has automated routines for giving it a lower weight.
Second, Senzing ER is flexible enough to be used in a variety of use cases and languages. It can be used to resolve identities of individuals using American passport numbers and phone numbers, or to identify Chinese manufactures using addresses. It’s natural language processing (NLP) capabilites allow it to “read” Roman, Mandarin, and Cyrillic scripts.
“You can pivot from people to companies to vessels and different languages without any tuning,” Jonas said. “It’s easy to explain. It’s totally real time.”
Third, Senzing ER is able to apply new information to past ER determinations. This feature, which the company calls “sequence neutrality,” could be one of the most crucial aspects of the software, according to Jonas, because it directly impacts the overall accuracy and timeliness of the ER process.
Jonas explained:
“Imagine you’ve loaded a billion records, and now you get record nine,” he said. “You not only have to figure out where to put record nine, but you have to ask yourself the question: Had I known record nine first, over the billions of decision I’ve made, should I have made any of them differently? And then fix them in real time.”
It’s a non-trivial problem, especially at scale, Jonas said. No other ER engine is able to revisit past decisions in this manner at scale and in real time, he said.
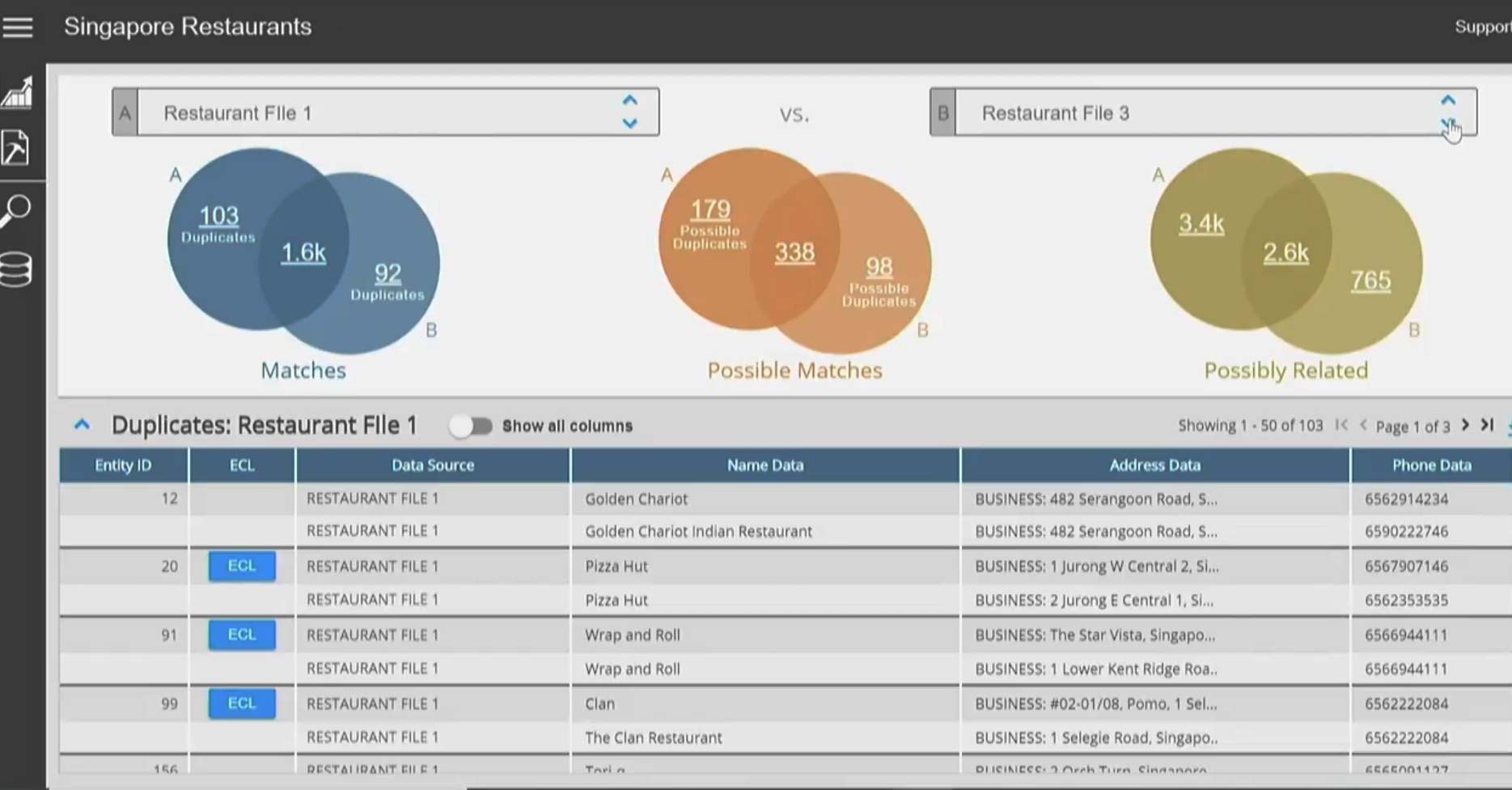
Senzing provides users with a GUI for working with entities and supporting records
“We update the records when they arrive, but you can’t be assured that the data shows up in the right order,” he said. “If data always showed up in the perfect order, you’d never have to reload. If record nine always showed up before record three, then you’re fine. But that doesn’t happen. It’s rare.”
The sequence neutrality feature gives users the ability to correct misinformation more quickly and to make better decisions when those decisions are based on correctly identifying people or other entities. Other ER systems will often run correction routines every three months or so, Jonas said, but some clients don’t have the luxury of time.
“That means for 90 days, you had the right data, you could have known the right answer, but you produced the wrong answer,” he said. “That’s bad for healthcare, fraud, national security.”
Wider Use Cases
Big corporations and governments who must keep track millions or billions of people have obvious needs for ER. But according to Jonas, even small and midsized businesses have a need for ER, even if they haven’t expressly identified the need.
“It’s a problem everybody is having,” he said. “Every company with more than a few hundred records in their CRM systems is struggling with duplicates in there. It’s just everywhere.”
Fraud also demands ER. Any organization that is trying to detect fraudulent transactions will need to run some sort of ER process to be sure they’re working with legitimate entities and not being tricked into doing business with criminals.
“As soon as you’re dealing with fraud, you have people trying to obscure their identity, so you absolutely have to have entity-centric learning, or you can’t find them,” Jonas said.
Jonas takes it one step further: “If you don’t do entity resolution and understand common entities, you can’t really exhibit intelligence,” he said. “It’s actually the underpinning of context computing. If you can’t do this well, you can’t build context, and you can’t learn your own relationships with somebody.”
Related Items:
Finding a Single Version of Truth Within Big Data
The Graph That Knows the World
Machine Learning’s Big Role in the Future of Cybersecurity
Applications:
Data Mining
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States