

April 24, 2019
Databricks Donates Delta Code to Open Source
Databricks today announced that it’s open sourcing the code behind Databricks Delta, the Apache Spark-based product it designed to help keep data neat and clean as it flows from sources into its cloud-based analytics environment. Delta Lake, as the new offering is called, will be freely available under a permissive Apache 2.0 license.
Databricks originally launched Delta back in 2017 to help provide greater order to its cloud customers’ data management issues. The San Francisco, California company positioned Databricks Delta as a hybrid solution of sorts that combined elements of data lakes, MPP-style data warehouses, and streaming analytics in a managed data paradigm.
Now the proprietary, cloud-only service that used to be tied to Databricks Unified Analytics Platform is becoming an open source software product/project that anybody can run — even organizations struggling to manage large data sets stored in on-prem or cloud-based Hadoop and Spark clusters, according to Ali Ghodsi, CEO and co-founder of Databricks and one of the creators Apache Spark.
“As the original creators of Apache Spark, we firmly believe in open source and open APIs,” Ghodsi tells Datanami. “We want the entire open source community–both on-prem and cloud–to benefit from Delta’s transactional storage layer.”
Ghodsi — who is one of Datanami’s People to Watch for 2019 — says Delta Lake has been “battle tested in production” with hundreds of organizations in the Databricks cloud. By open sourcing the software, Databricks hopes to spur adoption of the software, which could turbocharge development of new features, not to mention accelerate the eradication of bugs.
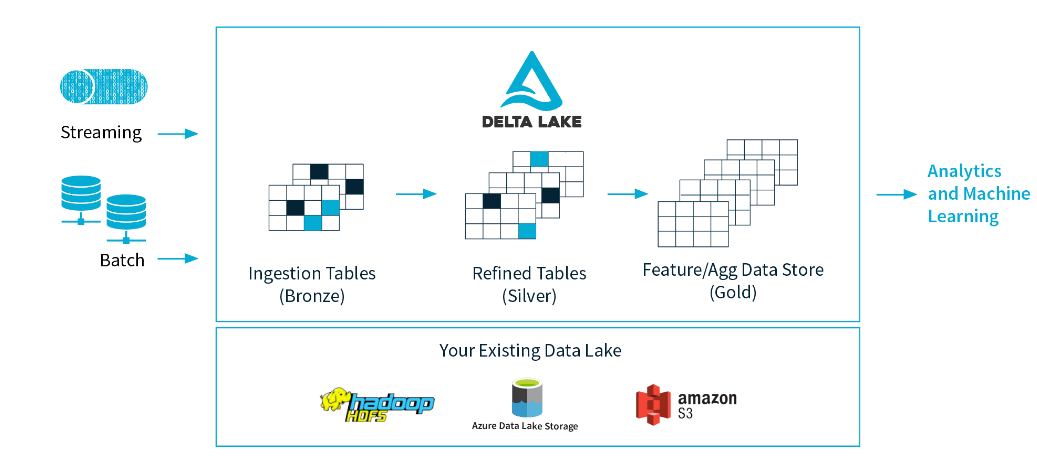
Delta Lake enforces minimum data quality levels for data flowing into lakes (image courtesy Delta.io)
“We hope Delta Lake open source technology gets adopted by the community and it becomes a standard for bringing reliability to data lakes,” Ghodsi says. “We want Delta Lake to be the standard for storing big data–both on-prem and cloud. Hence we have decided to open source it with Apache License 2.0.”
Some of the challenges that Databricks customers have faced stem from events like failed writes, schema mismatches, and data inconsistencies when mixing batch and streaming data, Databricks says. Supporting multiple writers and readers simultaneously is another source of potential error when operating data lakes at scale.
Delta Lake addresses these challenges through several mechanisms, including by automatically enforcing minimum data quality standards through schema management, and taking a transactional approach to data updates, among others, Ghodsi says.
“What Delta does is it looks at data coming in and it makes sure it has high quality,” Ghodsi tells Datanami in a recent interview. “So if it doesn’t have high quality, it will not let it into Delta. It will put it back into the data lake and quarantine it so you can go and look at it to see if you can fix it.”

Databricks says hundreds of its customers use Delta Lake to process exabytes of data every month
Delta Lake gives users the capability to enforce “bronze-silver-gold” data quality levels. The software supports multiple data flows, including batch and streaming sources and sinks. “Streaming data ingest, batch historic backfill, and interactive queries all just work out of the box,” it claims on the Delta Lake website (http://delta.io).
Delta Lake also brings the notion of ACID-compliant transactions to data updates. So when you’re updating data in Delta, “you’re guaranteed that everything either completely succeeds or completely fails,” Ghodsi says. “You cannot end up with an in-between situation.”
Delta Lake complements Apache Spark, which is used in just about every Hadoop implementation these days. The software is compatible with Parquet, a compressed data format commonly found in Hadoop clusters, so customers can easily adopt Delta Lake without rewriting all of their data from HDFS into Delta Lake, Databricks says.
The company says Delta Lake will assist developers in developing and debugging data pipelines from the comfort of their laptop. The software will also enable developers to access earlier versions of their data for audits, rollbacks or reproducing machine learning experiments, the company says.
The Delta Lake project will be managed on GitHub. A Slack channel and a Google Group hve been set up to allow contributors to collaborate. For more info, see the project’s website at https://delta.io.
Related Items:
How Databricks Keeps Data Quality High with Delta
Databricks Puts ‘Delta’ at the Confluence of Lakes, Streams, and Warehouses
Vendors:
Databricks
Tags:
big data, data lake, data pipeline, data quality, databricks, Databricks Delta, Delta Lake, Hadoop, HDFS, s3
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States