

February 7, 2019
Lentiq Launches EdgeLake With Some Fanfare

Dr. Kirk Borne doesn’t pitch for products very often. He tipped Datanami off to the work Ayasdi was doing some years ago in the field of topological data analysis. Now there’s another vendor product the senior data scientist is speaking well about: the new EdgeLake product from Lentiq that launched today.
Lentiq has a new take on data lakes. Instead of building a centralized data lake, the vendor’s EdgeLake offering provides users with a distributed architecture that’s composed of multiple interconnected “micro data lakes,” or data pools.
These data pools physically live across multiple clouds – AWS, Azure, and GCP – and store data in a publish/subscribe manner. EdgeLake is pre-loaded with “everything a data scientist or data engineer needs,” the company claims, including data management capabilities and notebook environments, as well as Apache Spark, Apache Kafka, and Streamsets software.
The data pools exist independently across different clouds, and governance rules are only enforced when the data moves. “This design allows data teams to leverage the best tools and skillsets available for the job, mitigate local infrastructure requirements and apply governance policies without hindering innovation and adaptability,” the vendor says.
The new service caught the eye of Kirk Borne, the principal data scientist and executive advisor for Booz Allen Hamilton, who previously taught astrophysics and computational science at George Mason University and has spoken at Tabor Communications‘ Leverage Big Data events, among others.
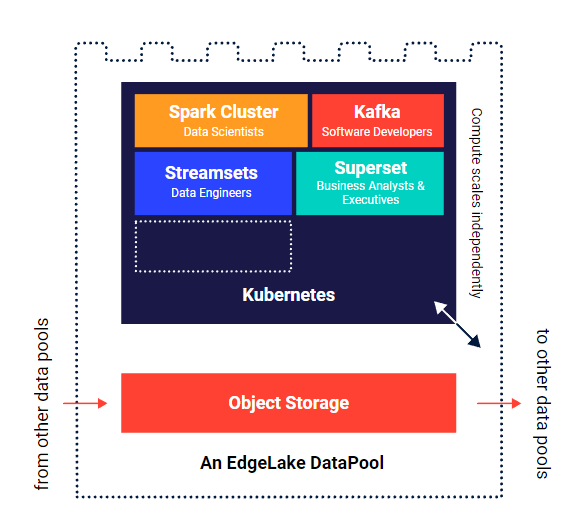
The Lentiq EdgeLake stack
“Lentiq’s new Data Pools and EdgeLake architecture have changed the data analytics landscape in one comprehensive strike,” Borne wrote. “The data lake has come of age in Lentiq’s new Data Pool and EdgeLake by converging the best of data architecture, data curation, data sharing, data science modeling, analytics delivery, and production-level capabilities into a single user-driven, use case-configurable, flexible, agile platform for innovation.”
Lentiq was spun out of Bigstep, a bare-metal cloud provider based in Chicago and London. The company has been involved in running big data, machine learning, and analytics projects for years. In 2016, Bigstep launched a bare-metal Spark service that also featured a Jupyter notebook interface for rapidly prototyping data application in Python, Scala, and R. Lentiq is based in Chicago and is a subsidiary of Bigstep.
“At Lentiq, we believe companies can achieve transformative innovation by taking a human-centric machine learning approach to data projects,” said Lucas Roh, CEO of Lentiq. “Our data pools allow organizations to unify departments through data and knowledge sharing mechanisms.”
Related Items:
Is it Time to Drain the Data Lake?
Bigstep Adds Spark Service to Bare-Metal Cloud
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States