

June 5, 2018
Project Hydrogen Unites Apache Spark with DL Frameworks

(Pro500/Shutterstock)
The folks behind Apache Spark today unveiled Project Hydrogen, a new endeavor that aims to eliminate barriers preventing organizations from using Spark with deep learning frameworks like TensorFlow and MXnet.
It’s tough to overstate the impact that Apache Spark has had in the emergent big data field. The software not only replaced MapReduce in the Apache Hadoop stack, but it also presented a unified framework for running data transformation, machine learning, SQL query, and streaming analytic workloads.
However, the elegance of Spark’s “single framework” approach breaks down when one tries to plug other distributed machine learning frameworks into the loop. While Spark MLlib provides solid machine learning functionality, the data science field is moving extraordinary fast and many data scientist want to explore the capabilities of emerging deep learning frameworks, such as TensorFlow, Keras, Caffe2, MXnet, and others.
The problem is, Spark and deep learning frameworks don’t play well together. Reynold Xin, a co-founder and chief architect of Databricks, explained the problem – and how Project Hydrogen presents a possible solution — during a keynote today at Spark AI Summit, which is being held in San Francisco.
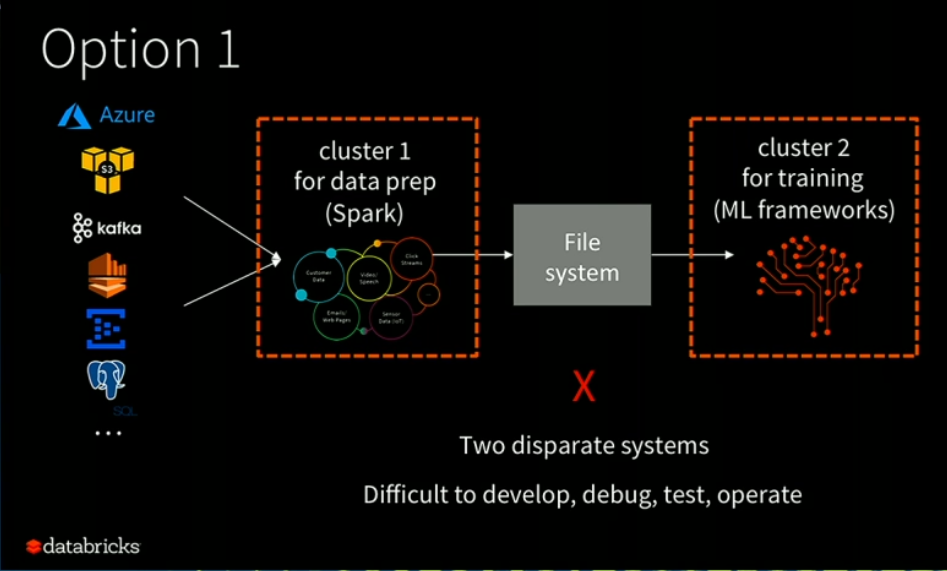
This works but introduces complexity and room for failure
“We’re increasingly seeing Spark users wanting to combine Spark together with those frameworks,” Xin said. However, “there’s actually a fundamental incompatibility between the way the Spark scheduler works and all of these distributed machine learning frameworks.”
There are two options for combining Spark with deep learning framework. Option one calls for using two different clusters. After prepping and cleansing the data with the Spark cluster, the data is then written the data to a shared storage repository, such as HDFS or S3, where a second cluster running the distributed machine learning frameworks can read it.
“The big problem is you created two disparate systems and it actually breaks down the unified nature, which means now, even just to debug, you have to understand exactly how the different systems work,” Xin said. “They might have very different debugging schemes, different log files… Just to write a single test case in Scala or Python becomes very difficult. It’s also very difficult to operate.”
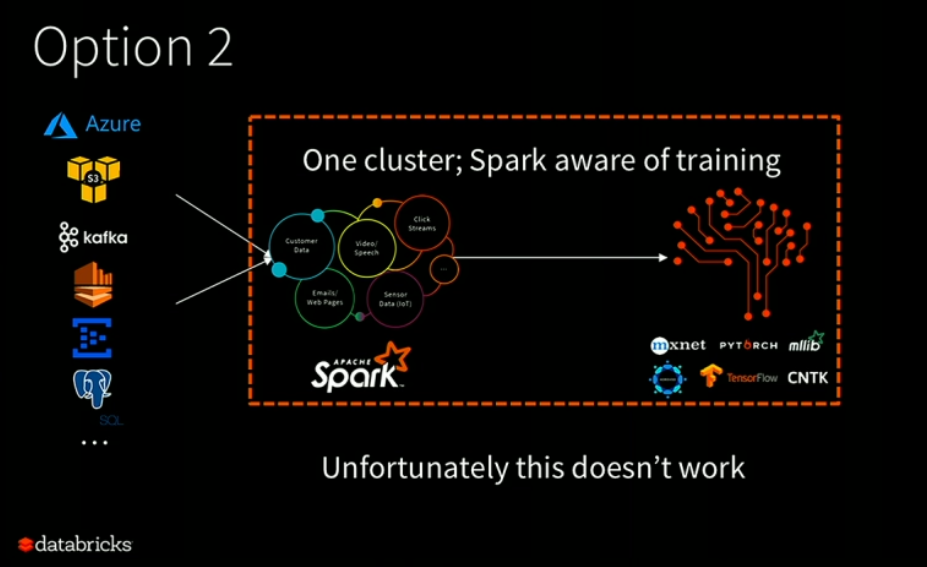
This doesn’t work, unfortunately
Some users have attempted to work around those debugging, testing, and operational difficulties by selecting option two: building single clusters that runs Spark and the distributed ML frameworks. “Unfortunately this doesn’t quite work today,” Xin said. “Some of you might actually be doing it, but let me show you why it doesn’t work.”
The problem with this approach, Xin said, is a disparity between how Spark jobs are scheduled and how deep learning jobs are scheduled. On Spark, each job is divided into a number of individual tasks that are independent of each other. “This is what we call embarrassingly parallel,” Xin said. “This is a massively scalable way of doing data processing that can sale up to petabytes of data.”
However, the deep learning frameworks use different scheduling schemes. “Sometimes they use MPI and sometimes they use own custom RPCs for doing communication,” Xin said. “But one of the things they have in common is they assume complete coordination and dependency among the tasks. What that means is this pattern is optimized for constant communication, rather than large-scale data processing to scale to petabytes of data.”

Spark and DL frameworks have fundamentally incompatible execution models
The ramifications of this approach become clear when tasks fail. In the Spark model, when a task fails, the Spark scheduler simply restarts that single task, and the entire job is fully recovered. “But in the case of distributed machine learning frameworks, if one of the tasks fails, because there’s complete dependency, all the tasks need to be launched,” Xin said. “And if only…one of the tasks gets launched, that task will actually wait for all the others tasks to be launched, and actually hang.”
Project Hydrogen is positioned as potential solution to this dilemma. Project Hydrogen institutes a new scheduling primitive called Gang Scheduler that addresses the dependencies introduced by the deep learning schedulers.
“In this gang scheduling role, as evident from the name, it has to schedule all or nothing, which means either all the tasks are scheduled in one shot or none of the tasks get scheduled at all,” Xin said. “This acutely reconciles the fundamental incapability between how Spark works and what distributed machine learning frameworks need.”

Project Hydrogen unifies the execution models for Spark and DL frameworks
The new Project Hydrogen API isn’t final, Xin said. But it’s expected to be added to the core Apache Spark project soon.
“The goal of Project Hydrogen is really to embrace all the distributed machine learning frameworks as first-class citizens on Spark,” Xin said. “We want to make every other framework as easy to run as MLlib directly on Spark.”
That’s not all that’s cooking in Spark when it comes to deep learning, Xin said. “There’s going to be a lot more work that we do to actually embrace other machine learning frameworks as first-class citizens, including speeding up data exchanges. These data exchanges can often become a bottleneck…We also want to make Spark aware of accelerators so you can actually comfortably use FPGA or GPUs in your latest clusters.”
Related Items:
Top 3 New Features in Apache Spark 2.3
How Spark Illuminates Deep Learning
Spark’s New Deep Learning Tricks
Applications:
Data Mining
Vendors:
Databricks
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States