

April 24, 2018
Google’s BigQuery Gaining Steam As Cloud Warehouse Wars Heat Up

(sdecoret/Shutterstock)
Amazon Redshift may dominate the nascent cloud data warehouse category, but anecdotal evidence suggests Google BigQuery is catching on quickly – and offerings from Microsoft, SnowFlake, and others aren’t far behind.
Apache Hadoop stormed the IT scene in 2012 with promises of dirt cheap storage and a powerful new way to process data with MapReduce, jumpstarting a sea change in the way we use and consume data. Hadoop itself may have lost some steam as the primary change agent, but the data revolution continues today largely in public clouds, where object storage systems and hyper-scale clusters promise (though don’t always deliver) better terms for data storage and processing.
Amid all this change, we’ve witnessed the rise of cloud data warehouses, which have gobbled up SQL analytic workloads from many on-premise Hadoop setups and emerged as the favored storage and processing paradigm for Web data that never touches the ground. Amazon Web Services arguably was first on the scene with Redshift, a columnar cloud warehouse based on the ParAccel database.
But RedShift now a number of competitors sporting cloud-based analytical databases, including Snowflake Computing, Microsoft Azure SQL Data Warehouse, as well as offerings from Teradata, Oracle, SAP, IBM, and Micro Focus, which owns Hewlett-Packard’s old Vertica product.
In this emerging cloud data warehouse scene, the most compelling alternative to Redshift may come from Google Cloud and its BigQuery offering.
BigQuery Roots
BigQuery traces its roots back to 2010, when Google released beta access to a new SQL processing system based on its distributed query engine technology, called Dremel, which was described in an influential paper released the same year. The service was released to general availability in 2011.
BigQuery is a fully-managed data service that lets users run queries against data stored on the Google Cloud Storage. Before running queries, the data must be transformed into a read-only nested JSON schema (CSV, Avro, Parquet, and Cloud Datastore formats will also work). Once the data is loaded, BigQuery users are ready to submit SQL queries via the UI or a REST API. At runtime, the SQL queries are translated into low-level instructions that lets BigQuery execute the query and then gather the results across the Dremel “tree architecture” in a massively parallel manner.
This is where the service’s server-less architecture can demonstrates its raw, unadulterated processing power. Billion-row queries that would bring modest on-premise clusters to their knees are processed in a handful of seconds, making BigQuery an ideal solution for ad hoc queries.
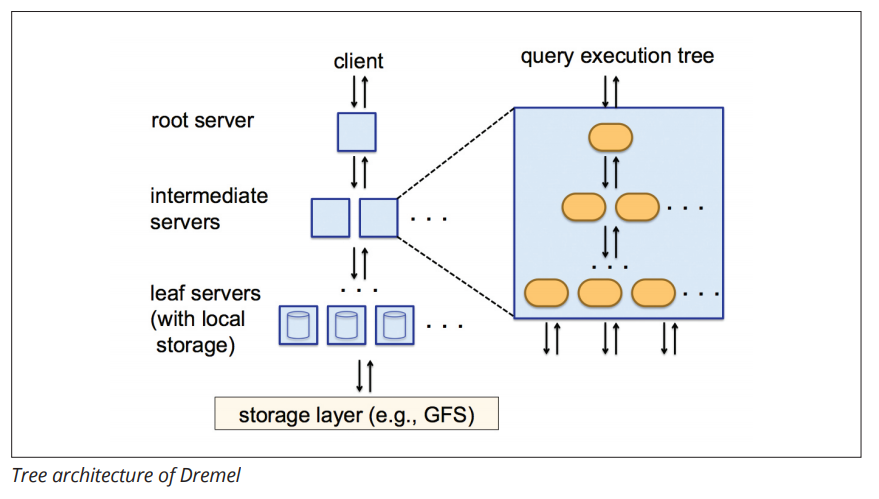
Dremel’s Tree Architecture (Source: Google’s 2012 paper An Inside Look at Google BigQuery)
In naming Google BigQuery the leader in insight platforms as a service (PaaS) (which perhaps is a less elegant name than “cloud data warehouse”), Forrester marveled that “BigQuery lets developers query petabytes in milliseconds.”
Needless to say, it can be quite handy to rent a full-on hyperscale setup, if only for a few minutes or hours at a time. “BigQuery is powered by multiple data centers, each with hundreds of thousands of cores, dozens of petabytes in storage capacity, and terabytes in networking bandwidth,” the Web giant writes in a blog post from 2016. “BigQuery’s vast size gives users great query performance.”
BigQuery Growth
Google doesn’t often share figures about the number of users of its products and services, so it’s hard to gauge the success that BigQuery has had. However, anecdotal evidence and surveys by independent software vendors point to solid growth, particularly in the last year.
AtScale, which sells an OLAP-style optimizer for big data clusters running on Hadoop and the cloud, recently surveyed its customers about their analytic investments, including use of on-premise and cloud-based systems. The results show strong adoption of cloud data warehouses, including an astounding 11% of respondents who said they are planning to adopt BigQuery, and another 60% who say they are investigating BigQuery.

BigQuery’s simplistic interface belies its enormous power
AtScale is working with a large American retailer that is shifting analytic workloads from on-premise Hadoop clusters into BigQuery. And there are still others who never migrated from first-generation massively parallel processing (MPP) databases into Hadoop who are now making the leap directly to the cloud, where they can get extreme-scale processing without investing in any hardware at all.
That flexibility to scale-up and scale-down compute needs is among the top reasons why organizations adopt cloud data warehouse movement. CFOs like having the ability to only pay for what their organizations store and what they process on Google, Microsoft, AWS, or any other cloud data warehouse (Databricks and Qubole are others worth mentioning).
BigQuery Planning
But Google says its flexibility goes even further, including the capability to run streaming analytics and deep learning workloads using its Cloud Dataflow and TensorFlow processing paradigms. Those are all good options to have for public cloud customers, but when it comes to the analytic engine, the flexibility to ask any question without first massaging the data could be equally as important.
Lloyd Tabb, the founder, chairman, and CTO of data analytics and platform firm Looker, has seen momentum build behind cloud warehouses like BigQuery over the past several years. Tapping into a fully-managed MPP warehouse has that effect, he says.

Google leads the Forrester Wave for Insights PaaS in Q3 2017
“That makes it so you can actually think about data problems rather than thinking about how to manage your cluster,” Tabb told Datanami last fall. “If you have to hire a big team of people to install machines, install the software, keep the software up to date, figure out which pieces don’t interact properly. When it’s all a managed service, the time to value is so much better”
Instead of trying to scale one’s own big data cluster, with BigQuery, Google handles the scalability for you. “What’s nice about the cloud is it scales to meet your needs,” Tabb says. “So if you’re running a query in BigQuery for example, that goes against a couple of gigabytes a petabyte of data, the query returns in constant time.”
Big corporations are taking advantage of those benefits, and the loser in these migrations is often Hadoop. “We’ve seen really big companies who have big Hadoop clusters move their data to the cloud because they’re much more agile,” Tabb says. “We keep seeing this over and over. Big time companies who I can’t name…spent all this money building these big Hadoop infrastructures, and then they say, we can spend that engineering on figuring out answers to things instead of managing the cluster.”
As Google builds out its BigQuery product, the reasons for not using it will continue to dwindle. With Google Next ’18 just around the corner, we’ll soon get to see what the future of this product holds. Despite its ferocious processing speed, BigQuery isn’t guaranteed to be a winner, as it faces tough competition that is continually getting better too.
Related Items:
Room to Grow on the Big Data Maturity Curve
Cloud In, Hadoop Out as Hot Repository for Big Data
Editor’s note. This article has been corrected. Google BigQuery is not read-only. Datanami regrets the error.
Applications:
Data Mining
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States