

February 22, 2018
The Hybrid Database Capturing Perishable Insights at Yiguo

Yiguo.com is the largest B2C fresh produce online marketplace in China, serving close to 5 million users and more than 1,000 enterprise customers. We have long devoted ourselves to providing fresh food for ordinary consumers and have gained popularity since our founding in 2005. With a rapidly growing user base and data, we needed a highly performant, horizontally scalable real-time database system that can support both online transaction processing (OLTP) and online analytical processing (OLAP) workloads, in order to make timely and accurate business decisions to provide quality service for our users.
Combining TiDB and TiSpark, we found the solution we needed–a scalable, strongly consistent, and highly available data processing platform that supports both OLTP and OLAP. Our applications now have a new competitive edge to deliver better services faster than ever before.
Our Pain Points
Previously, the data analytics system at Yiguo.com was built on top of the Hadoop ecosystem and Microsoft’s SQL Server. We ran a near real-time system on SQL Server in the beginning, implemented by our engineers through writing and maintaining corresponding stored procedures. Because the data size was not that large back then, SQL Server was enough to meet our demand. As our business and user base grew, the amount of data has also grown to a point beyond what SQL Server could handle. Our system became a bottleneck, and we had to look for a new solution.
We had three criteria for this new solution:
- Meet both OLTP and OLAP workload requirements;
- Integrate seamlessly with our existing applications, so data migration overhead is low and the learning curve isn’t steep;
- Interface well with our existing Hadoop-based system.
Our Evaluation Process
We evaluated three options — Greenplum, Apache Kudu, and TiDB/TiSpark. We decided to go with TiDB/TiSpark because of the following reasons:![]()
- Greenplum is a MPP (Massively Parallel Processing) platform based on PostgreSQL. It is usually used in offline analysis scenarios where the number of concurrent transactions is not very high. However, for OLTP scenarios, our preliminary test showed that it had poor concurrent write performance compared to TiDB.
- Apache Kudu is a columnar storage manager developed for the Hadoop platform that is widely adopted for real-time analytics. However, secondary indexes, which are not supported by Kudu, are very important for us to efficiently access data with attributes other than the primary key.
- As a Hybrid Transactional/Analytical Processing (HTAP) database, TiDB eliminates the necessity to constantly move data between different data warehouses to support either transactional or analytical workloads. Thus, it enables real-time business analysis based on “live” transactional data instead of after-the-fact analysis, and helps our team instantly transform raw data into insights for timely decision-making.
- TiSpark takes advantage of both the Apache Spark platform and TiDB to provide HTAP capabilities, making the entire package a one-stop solution for online transactions and analysis.
- The TiDB/TiSpark open source community is thriving, which boosted our confidence in the future health and strength of this solution.
TiDB Project Overview
As I previously mentioned, TiDB is an open source distributed HTAP database that was originally inspired by the designs in Google’s Spanner and F1 papers. It has the following core features:
- Compatibility with the MySQL protocol;
- Horizontal scalability;
- Distributed ACID transactions across multiple data centers;
- Strong consistency guarantees;
- Automatic failover and high availability.
TiSpark is a thin layer built for running Apache Spark on top of TiDB and TiKV (the Key-Value storage layer, see further explanation below) to accelerate complex OLAP queries. It takes the performance boost of Spark and marries it with the rest of the TiDB cluster components to deliver a HTAP architecture.
TiDB also has a suite of other useful tools in its ecosystem, such as Ansible scripts for quick deployment, Syncer for seamless migration from MySQL, Wormhole for migrating heterogeneous data, and TiDB-Binlog, which is a tool to collect binlog files.
Implementation Overview
In mid-October 2017, after careful design and rigorous testing, we migrated our real-time analysis system to TiDB/TiSpark in production.
The architecture of our new system is as follows:
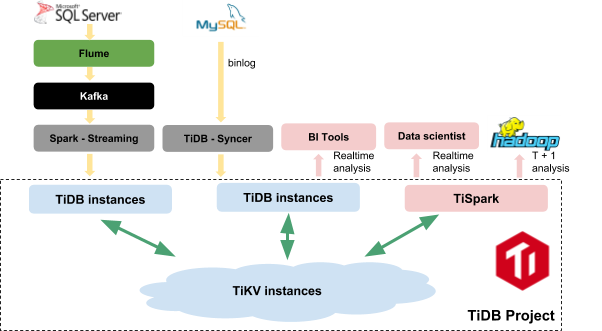
TiDB/TiSpark real-time data warehouse platform
This data platform works in the following way:
Transactional data in our existing SQL Servers is ingested to TiDB through Flume, Kafka, and Spark Streaming in real time, while the data from MySQL is written to TiDB via binlog and Syncer.
Inside the TiDB project, we have several components:
- The TiDB cluster consists of stateless TiDB instances that serve as a SQL layer that processes users’ SQL queries, accesses data in the storage layer (TiKV), and returns the corresponding results. In our case, the TiDB cluster is used to power our business intelligence tools for real-time analysis computing on datasets with several million rows, and these analytical tasks execute every 5-10 minutes.
- The TiKV cluster, composed of TiKV instances, is the distributed transactional Key-Value storage layer where the data resides. Regardless of whether the data comes from SQL Server or MySQL, it is stored in TiKV eventually. It uses the Raft protocol for replication to ensure data consistency and disaster recovery.
- TiSpark sits on top of TiKV to support both our data scientists’ needs for real-time analysis or offline daily analysis in our existing Hadoop system.
In the architecture, TiDB/TiSpark serves as a hybrid database that provides the following benefits:
A real-time data warehouse, where the upstream OLTP data write in real-time using TiDB, and the downstream OLAP applications perform real-time analysis using TiDB/TiSpark. This enables our data scientists to make quicker decisions based on more current and transactionally consistent data.
A single data warehouse that accelerates `T+1` (this means dumping data per day to the analytical system, where `T` refers to the Transaction date, and `+1` refers to one day after the Transaction date) asynchronously and handles ETL (Extract, Transform and Load) processing.
The data for `T+1` analysis can be extracted directly from TiDB using TiSpark, which is much faster than using Datax and Sqoop to read data from a traditional relational database.
Before TiDB/TiSpark, we had to maintain separate data warehouses, and the ETL process was time-consuming. Now, the ETL process becomes simple. The extraction tool just needs to support TiDB, instead of multiple data sources, which provides better support for business applications and reduces maintenance cost.![]()
Compatibility of TiDB with MySQL significantly reduced our migration cost. The transactional data from MySQL can flow to TiDB via Syncer (a tool in the TiDB ecosystem). In addition, we can reuse many of the existing tools from the MySQL community without making too many changes to our existing applications, which increased our productivity and while reducing the learning curve.
The auto-failover and high availability features of TiDB help to guarantee the stability and availability of the entire system.
The design of TiDB enables even and dynamically balanced data distribution. We can use TiDB as a backup database for hot data, or directly migrate hot data to TiDB in the future.
Results
We used TiSpark for complex data analysis on the entire dataset of Singles’ Day, China’s largest online shopping day. We saw a nearly 4-times performance improvement using TiSpark compared to SQL Server. For example, we have one complex SQL query that joins 12 tables with several tables having over 1 million rows. This query took only 8 minutes to run on TiSpark whereas it would have taken more than 30 minutes on SQL Server.
Our current success with using TiDB/TiSpark gives us confidence that more of our services will migrate to TiDB in the future. This unified and real-time hybrid database enables us to harness the power of “fresh” data immediately to create value for our users.
Lessons Learned
Our migration to TiDB/TiSpark was not without challenges. Here are some lessons learned:
- It is highly recommended that you use TiDB Ansible for deployment, upgrade, and operations. In the test environment, we manually deployed TiDB using the binary package. It was easy, but the upgrade became troublesome after TiDB released its 1.0 version in October 2017. After consulting the TiDB support team, we re-deployed the 1.0 version using the TiDB Ansible scripts, and the upgrade became much easier. Meanwhile, TiDB’s Ansible scripts install Prometheus and Grafana monitoring components by default. TiDB provides a lot of excellent Grafana templates, which made monitoring and configuration simple.
- To achieve the best performance, using machines with SSDs is highly recommended. Initially, we were using mechanical hard disks in our cluster. Later on, we realized the latency caused by the unstable write workload significantly impacted the performance. We contacted the TiDB support team and confirmed that the TiDB architecture is mainly designed for the storage performance of SSD, so we changed the hard disks to SSD/NVMe, and the write performance significantly improved.
- For complex queries with many millions of rows, the performance of TiSpark is much better than TiDB. In the beginning, we were using TiDB for complex queries, but the performance of some complex scripts did not show any advantage over SQL Server. After tuning some parameters for parallel computing, such as `tidb_distsql_scan_concurrency`, `tidb_index_serial_scan_concurrency`, and `tidb_index_join_batch_size`, analytical tasks that used to take 15 minutes took only half that time. But this still could not fully meet our needs. So we turned to TiSpark, which turns out to be a perfect match for our scenarios.
- The online scheduling of the cluster cannot work together with offline scheduling. Each time the ETL script initiates some Spark parameters, it’s quite time-consuming. We plan to use Spark Streaming as a scheduling tool in the future. Spark Streaming records the timestamp after each execution and we only need to monitor the timestamp changes, thus avoiding the time consumed by multiple initializations. With Spark monitoring, we can clearly see the delay and states of the tasks.
Conclusion
TiDB and TiSpark together provide a scalable solution for both OLTP and OLAP workload for us. This combination has been adopted by other companies and proved to work well in many applications and business scenarios. Besides its performance, TiDB/TiSpark also reduces operational overhead and maintenance cost for our engineering team. The TiDB project has tremendous potential, and we hope it gains more adoption globally and serve as a critical piece of more companies’ infrastructure.
About the author: Ruixing Luo is the Big Data Architect at Yiguo Group, responsible for the design and implementation of Yiguo.com’s big data architecture. Previously, he was in charge of building the real-time analytics system at 51job.
Related Items:
9 Ways Retailers Are Using Big Data and Hadoop
Unlocking Retail’s Big Data Opportunity
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States