

November 15, 2017
First Look at Scio, a Scala API for Apache Beam
Apache Beam has emerged as a powerful new framework for building and running batch and streaming applications in a unified manner. In its first iteration, it offered APIs for Java and Python. Thanks to the new Scio API from Spotify, Scala developers can play with Beam too.
Scio was developed by the Swedish company Spotify to address issues relating to the migration of much of Spotfiy’s big data processing environment from on-premise to Google‘s cloud. Spotify engineer Neville Li shared the story behind Scio in a pair of posts on the Spotify Labs blog last month.
According to Li’s blog posts, Spotify had invested in many open source big data projects: Hadoop, Spark, Hive, Kafka, Storm, Cassandra, and ElasticSearch, and PostgreSQL too. The streaming music company boasts that its 2,500 node Hadoop cluster was one of the largest deployments in Europe, running 20,000 jobs per day.
However, the need to have dedicated staff to manage the separate clusters was a concern. So was getting all the animals in the big data zoo to play well together. For example, Spotify liked Hive for SQL-style processing on huge data sets, but the overhead of MapReduce could be painful. When it moved from row-oriented Avro files to column-oriented Parquet format, it discovered that Parquet didn’t work as well with Hive and Scalding as it would have liked.
Scalding and Scala are important tools to Spotfiy. The Scala syntax is quite similar to Java, and compatible with the JVM, but offers additional benefits to developers, such as being type-safe, which helps to minimize coding errors. It’s also a big user of Scalding, a Twitter product that provides a Scala API for Cascading, a high-level Java library for MapReduce.
To the Cloud!
In 2015, Spotify started a major project to migrate much its big data infrastructure to the Google Cloud Platform.![]()
The $2-billion company wanted to get out of the business of caring for and feeding individual clusters for various big data jobs. Plus, it appreciated the built-in integration of Google’s cloud offerings, like Dataflow, BigQuery, Bigtable, and Pub/Sub brought. As Google’s equivalents of products like MapReduce, Hive, Cassandra, and Kafka, respectively, Spotify foresaw a major simplification of its big data workflows.
The emergence of Google’s Cloud Dataflow software figured prominently in Spotify’s math. As a unified framework, Dataflow serves as a simple but powerful abstraction for developers to combine batch and real-time workloads, with pre-built connectors to Google’s BigQuery, Bigtable, and Pub/Sub products.
Also in 2015, Google contributed Dataflow to the Apache Software Foundation as Apache Beam, and subsequently we’ve seen open source “runners” that extend Beam out to Apache Spark, Apache Flink, Apache Apex, and Google’s own Cloud Dataflow runtime. While Beam is still relative immature, many in the industry consider it a potentially powerful force to cut into the creeping complexity in modern data processing methods.
However, there was a thorn in Beam’s rose – namely, there were only two APIs available for Beam: Java and Python. Spotfiy, as previously mentioned, was a dedicated Scala shop. In addition to the type-safe protections, Scala code is about 4x more compact than Java, and more performant than Python, which was previously Spotfiy’s language of choice, Li says.
Enter the Scio
Instead of moving back to Python or shifting development to Java, Spotfiy decided to develop its own Scala API for Beam. The company called it Scio. Development on Scio started in early 2016, and today the code is in widespread production, as well as being available under an open source license.
Li describes Scio as a “thin wrapper” on top of Beam’s Java SDK that offers an easy way to build powerful Dataflow pipelines in Scala. “We drew most of our inspiration for the API from Scalding and Spark, two libraries that we already use heavily at Spotfiy,” he says.
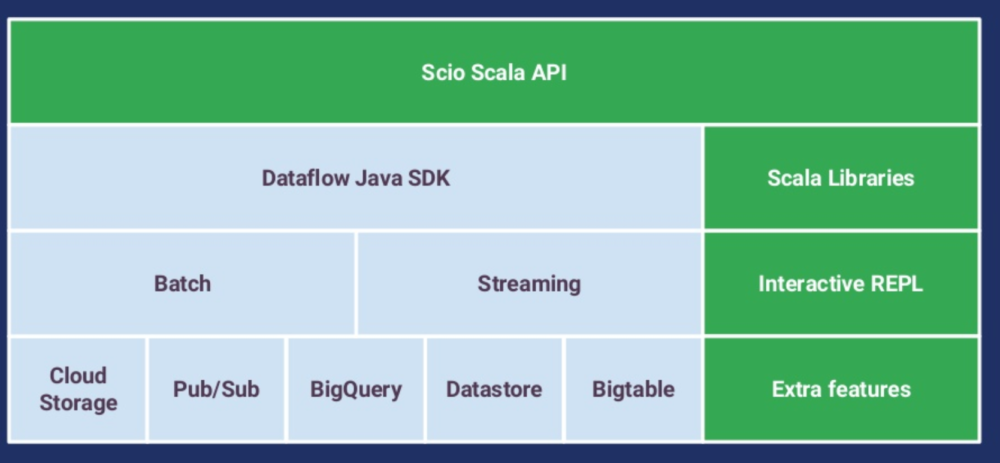
According to Li, the core abstract data type in Scio is the SCollection. The SCollection “wraps the Beam PCollection type and mimics Spark’s RDD (resilient distributed dataset) by providing parallel operations,” he says. There is also an SCollection of key-value tuples to provide grouping operations, similar to Spark’s PairRDDFunctions.
“By translating Beam Java boilerplate into idiomatic Scala functions, many of which are one-liners, Scio allows users to focus on business logic and makes it easier to evolve and refactor code,” Li says.
In addition to extending Java functions in Beam to Scala, it also provides “syntactic sugar” to simplify complex operations. So there’s not just inner, left-outer- and full-outer joins in Scio, Li says, but also side-input based hash joins and sparse-outer joins.
Spotify borrowed from other open source projects to solve additional tasks within Scio. It uses Twitter’s Algebird for parallel and approximate statistical computations. Twitter’s Chill and Scala reflection handle serialization, while the Beam project Coder is used for de-serializing data during shuffles with Java types and libraries like Avro.
Scio In Action
Spotify adopted Scio about 12 months ago, and since then it’s been used by more than 200 internal users, according to Li. The library has been used to develop more than 1,300 production pipelines, over that time, about 10% of which are streaming, he says.
“In total Scio powers 80,000 Dataflow jobs per month,” he says in the blog. “It is now the first choice tool for building data pipelines, and we use it for everything, [including] music recommendation, ads targeting, AB testing, behavioral analysis, and business metrics.”
Scio’s integration with BigQuery is a big plus. According to Li, BigQuery is the most heavily used Google product at Spotify. “Over 500 unique users made over one million queries in August 2017, processing 200PB of data,” he writes.
![]()
BigQuery runs orders of magnitude faster for common SQL operations, like filtering, grouping and basic aggregations. But BigQuery generates results for more complex queries as “stringly typed” objects, which are hard to work with, Li says. To get around that limitation, the Spotify team built Scala macros to generate type-safe representation of the company’s data at compile time, Li says.
Scio is running at large scale for Spotify, for both batch and streaming. The biggest batch workload was a Bigtable job that used 25,600 CPUs and 166.4 TB of RAM to process 325 billion rows, accounting for 240 TB of data. A common streaming job encompasses 480 CPUs, 1.8 TB of RAM and a host of fast SSD disks for real-time recommendations and reporting.
The company is also using Scio alongside tools like BigDiffy and Algebird to compare the results of pipelines for generating high-level statistics, and for testing how the results of machine learning applications change over time.
While Scio is still under “heavy development” at Spotify, the software is also being adopted by the open source community as a product under an Apache 2.0 license. Nearly 40 contributors, including developers from Spotify, Discord, Uber, and Twitter, have worked on the Spotify software at its GitHub page.
Overall, Li is pleased with how Scio has turned out. “By moving to Scio, we are simplifying our inventory of libraries and systems to maintain,” he writes. “Instead of managing Hadoop, Scalding, Spark, and Storm, we can now run the majority of our workloads with a single system, with little operational overhead. Replacing other components of our big data ecosystem with managed services, e.g. Kafka with Pub/Sub, Hive with BigQuery, Cassandra with Bigtable, further reduces our development and support cost.”
For more info on Scio, see Spotify’s blog post on the product and Li’s SlideShare presentation on the API.
Related Items:
Google Lauds Outside Influence on Apache Beam
Google Reimagines MapReduce, Launches Dataflow
Technologies:
Frameworks
Sectors:
Retail
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States