

September 27, 2017
Former Yahoo Unit Releases Vespa Engine

Vespa, Yahoo’s big data processing and serving engine, is now available as open source on GitHub, Oath Inc., the company formed in June after the completion of Verizon’s acquisition of Yahoo, announced this week.
Yahoo released Hadoop as an open-source platform in 2006. Oath, the successor to Yahoo, said Tuesday (Sept. 26) the release of Vespa is the next step in opening up its big data infrastructure to developers. The move responds to the growing data volumes involved in building applications.
While developers can still use the Hadoop stack to store and batch process big data, these and other stream-processing technologies are ill suited to delivering results to business users. By releasing the Vespa serving engine, “we are making it easy for anyone to build applications that can compute responses to user requests, over large datasets, at real time and at Internet scale – capabilities that up until now, have been within reach of only a few large companies,” the Verizon (NYSE: VZ) unit noted in an announcement.
Vespa has evolved since its launch in 2003 from a search technology to a serving engine. Oath describes it as
a platform for “processing and serving personally-recommended content at scale. Coupled with offline signal processing and machine learning, it is the entire backend technology stack for many content streams….”
Vespa also is designed to address the need within many applications for heavy computing over large data sets when search results or a recommendation are served to a user. “It won’t do to compute the result upfront,” Jon Bratseth, a Vespa architect, noted in a blog post. “It must be done at serving time, and since a user is waiting, it has to be done fast.”
That hyper-scale capability requires distributed algorithms, efficient data structures and memory management, Bratseth added. The company further claims that Vespa has been wrung out working on billions of daily search requests for documents in response to search queries from users of Yahoo.com.
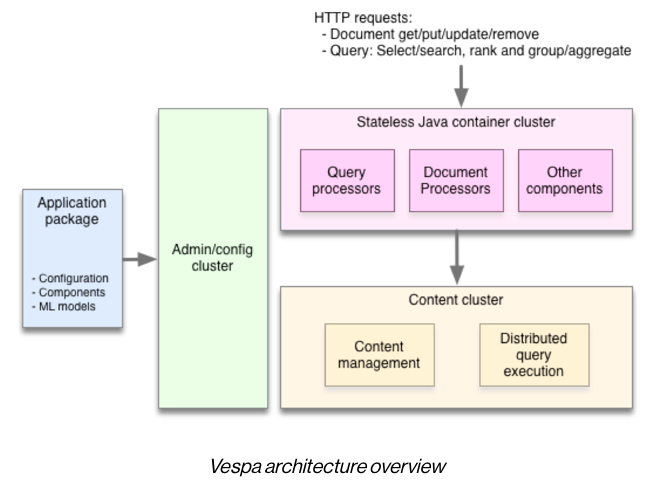
Vespa serve engine architecture (Source: Oath Inc.)
Developers further claim Vespa can process and serve content at a rate of nearly 90,000 requests a second with latencies in the tens of milliseconds.
For building new applications, Oath (former Yahoo) developers select content items using SQL-like queries and text search. Once all matches are organized, they are ranked via manual or machine learning models. Content clusters can grow, shrink or be reconfigured while serving data, the company said.
Vespa runs on premises or in the cloud, and comes with Docker images along with what the company calls “rpm packages” that run on a laptop or an Amazon Web Services (NASDAQ: AMZN) cluster. Using Vespa, Bratseth said developers should be able to get applications running “in less than ten minutes” following the company’s documentation.
Vespa is available on Github here.
Recent items:
Unstructured Data Search Engine Has Roots in HPC
Searching Geospatial Data Gets Easier
Applications:
Enterprise Analytics
Technologies:
Frameworks
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States