

July 27, 2017
Four Open Source Data Projects To Watch Now

via Shutterstock
While open source isn’t the sole source of creativity and progress in big data, it’s a major driver in the space. Market-shaking tech like Kafka, Spark, Hadoop, and MongoDB all began as obscure open source projects backed by enthusiasic developers. Which open source project will be the next breakout star?
Many open soruce projects are organized under the Apache Software Foundation, but not all. Here are four recently founded upstream big data projects – two hosted by the ASF and two that aren’t — that could find their way into your quiver of big data analytics tools.
Apache Fluo
Apache Fluo is an open source implementation of Percolator, the Google software developed to speed the incremental processing of updates to the Google search index. The Hadoop-based software runs atop Apache Accumulo, the open source key-value database based on Google’s Bigtable technology, and “makes it possible to update the results of a large-scale computation, index, or analytic as new data is discovered,” the project says.
Fluo is said to provide better performance for incremental updates on large data sets compared to batch-oriented Spark and MapReduce engines. It also eliminates the need to reprocess entire data sets when adding new data to the existing set, a common concern in data lakes.
Fluo graduated into a Top-Level Project at the ASF yesterday. “Apache Fluo is a very clever piece of software, elegantly supplementing Apache Accumulo’s ability to store and maintain very large indexes,” said Christopher Tubbs, ASF Member and Committer on Apache Accumulo and Apache Fluo. “Its support of transactions enables Accumulo to solve a whole new set of big data problems, and its observer framework makes designing ingest workflows fun.”
The project includes a core API that supports simple, cross-node transactional updates, and a Recipes API that supports complex transactional updates. It’s managed at fluo.apache.org.
Apache Lens
Apache Lens is an OLAP technology for Hadoop that provides a unified model and execution engine for querying data that resides in multiple locations, including Apache Hive and traditional data warehouses, such as HPE Vertica or Teradata, ostensibly.![]()
“Lens aims to cut the data analytics silos by providing a single view of data across multiple tiered data stores and optimal execution environment for the analytical query,” it says on the project’s GitHub site.
According to Apache Lens Vice President Amareshwari Sriramadasu, the technology ” solves a very critical problem in big data analytics space with respect to end users. It enables business users, analysts, data scientists, developers and other users to do complex analysis with ease, without knowing the underlying data layout.”
The software was initially devloped at InMobi, the mobile ad network company, and has been an open source projecdt at GitHub since 2013. It became a Top-Level Project at the ASF two years ago, and is managed at github.com/apache/lens.
Deck.GL

Deck.GL is a compelling data visualization framework developed by Uber and released as open source in 2016. The software is designed to make it easy to create complex, interactive data visualizations from large sets of geospatial data, while delivering high performance by emulating of 64-bit floating point computations in GPUs.
Deck.GL’s key attribute is its layered approach to data visualization, whereby a user can create complex visualizations by composing various layers, which are reusable. The library includes a catalog of existing layers that allow users to quickly roll out visualizations based on GeoJSON formatted data, grid and hexagon layers, polygons, scatterplots, and hexagons, to name a few. The framework generates compelling two-dimensional and three-dimensional visualizations that let users explore data sets – including historical and real-time — in a fun and informative manner.
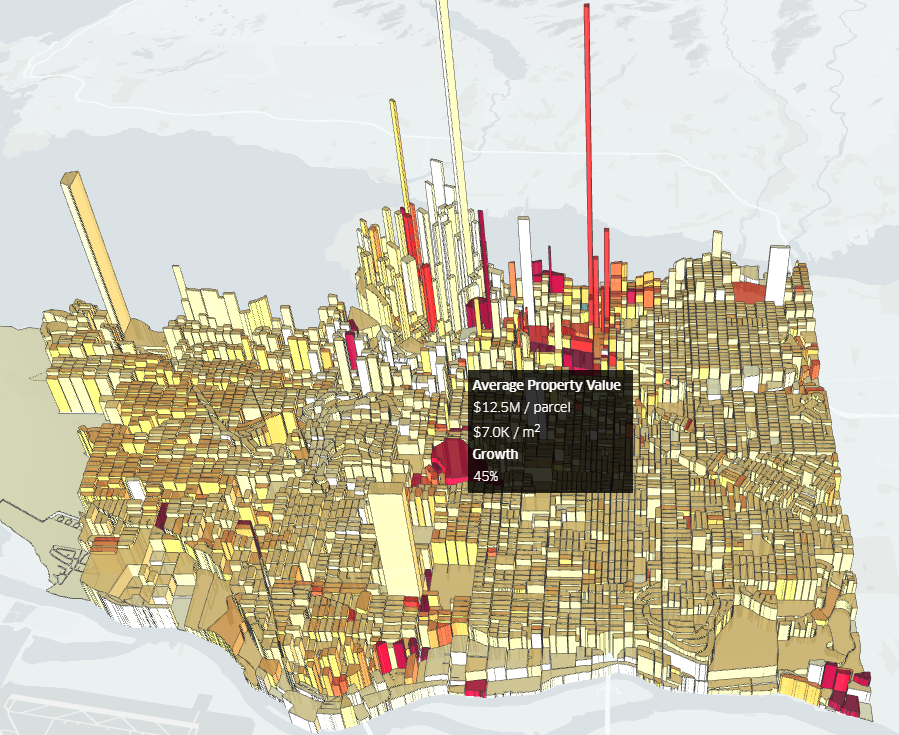
A 3D hexagon-based depiction of Vancouver property values created in Deck.GL
Custom visualizations created with Deck.GL can be packaged and shared through the WebGL JavaScript library. The framework is designed to be paired with React, the JavaScript library from Facebook, and Mapbox GL, the library of custom online maps developed by Mapbox and used by Uber, FourSquare, and other firms.
The most recent release of Deck.GL includes a 3D surface layer that “can be used for rendering things like Partial Dependence Plots for machine learning models, highlighting the correlations between two variables and their impact on a prediction,” writes Uber data visualization engineer Nicolas Garcia Belmonte in an April blog post.
The project is managed at uber.github.io.
Photon ML
PhotonML is a machine learning library for Apache Spark that was released to open source by LinkedIn last year. The company developed PhotonML to improve offline machine learning tasks used to train algorithms powering various aspects of its website, including the feed, advertising, recommender systems, email optimization, and search engines.
PhotonML supports a range of “handy analytical” capabilities that data scientists and data modelers can use to train algorithms in an optimal manner. Specifically, the library supports features like generalized liner models; regularization; feature scaling and normalization; offset training; feature summarization; and model diagnoses tools.
In the future, PhotonML will support Generalized Additive Mixed Effect (GAME) techniques, which enable data scientists to add random effects to their models. “It manages to scale model training up to hundreds of billions of coefficients while still solvable within Spark’s framework,” it says on the project’s GitHub site.
GAME is a specific expansion of traditional Generalized Linear Models that further provides entity level (e.g., per-user/per-item) or segment level (e.g., per-country/per-category) coefficients, also known as random effects in the statistics literature, in addition to global coefficients. It manages to scale model training up to hundreds of billions of coefficients while still solvable within Spark’s framework.
You can read more about LinkedIn’s GAME plans for PhotonML in a June 2016 blog post by LinkedIn engineer Paul Ogilvie. The project is hosted at github.com/linkedin/photon-ml.
Related Items:
An Open Source Tour de Force at Apache: Big Data 2016
Apache Beam’s Ambitious Goal: Unify Big Data Development
Sectors:
Financial Services
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States