

June 19, 2017
Carts & Horses: Why You Need to Focus on Data First

Like most of us, I love shiny new objects and learning about how successful companies are building them into their operations. Google’s use of Neural Nets for Translate? Tell me more. Got some data about Uber using artificial intelligence? I’m all ears. Facebook’s using Vertica? To do what?
I remember from my time buying enterprise software how easy it is to get distracted by some feature and truly believe it’s going to effect massive change in the organization. After talking to dozens of customers and hundreds of prospects over the last four years at Tamr, I can tell you that shiny-object-syndrome (S.O.S.) is alive and well in the enterprise. I’ve spent countless hours hearing about enterprises’ plans to use the latest in neural nets and algorithms to tackle massive challenges.
I love that technology leaders are thinking big – and I think that AI and ML are finally getting the recognition they deserve. But for most large, Fortune2000-ish enterprises, their S.O.S. is causing them to put the AI Cart before the Data horse.
That is, the reason companies like Facebook, Google and Tesla can use those shiny objects effectively is because they already have a good handle on their data. But for the rest of us – who didn’t build our systems from scratch fairly recently and have been treating our data more like an exhaust from our business instead of a strategic asset – if our data is a mess, there is no magic AI or ML algorithm that will transform our business. We’re behind Facebook and Google in this respect not because we’re not using cutting edge algos, but because we haven’t gotten our data in order.
It’s an old saying, but it’s still true: Garbage in, garbage out. And garbage abounds in enterprise data. I can tell you, firsthand, that the state of data for the average enterprise is abysmal.
Here’s what most people think their enterprise data looks like:
 Here is what it actually looks like:
Here is what it actually looks like:
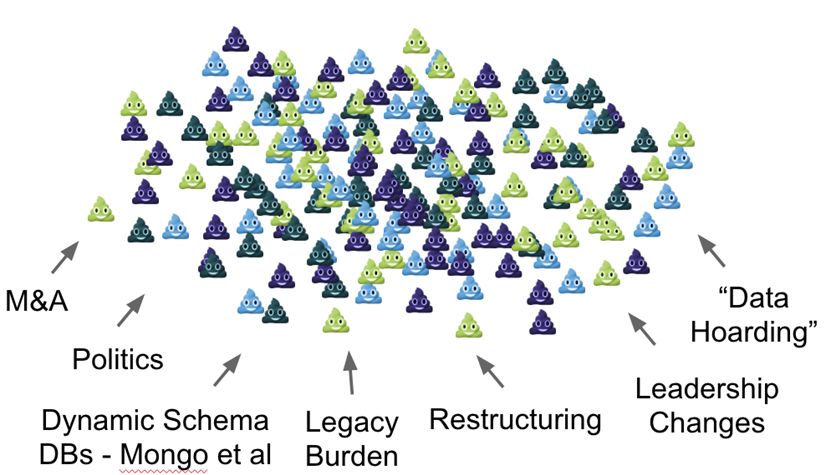 Not to scale
Not to scale
The variety and messiness of data is a natural consequence of how big organizations operate. Business units install their own operational systems; managers acquire new companies, technology executives install new systems to solve new problems…and as a result, no one operates with a holistic view across the enterprise. Large, older companies have been generating data for decades and essentially treating it like exhaust at best and waste at worse. These same companies now want to go in and fix years of mismanagement. It’s a hard problem.
Over the last twenty years, we’ve tried to solve these problems in a variety of ways.
- Many enterprises have worked hard to reduce the number of systems they use and push all of their data into single platforms. Still, this didn’t stop the number of separate instances of these systems from skyrocketing. Our customers commonly have dozens, if not hundreds of instances of systems across their lines of business. They often don’t know precisely how many because it’s too difficult to count.
- The holy grail of data management, standardization efforts by a company, industry or application just aren’t enough and mostly fall short of expectations. Standardization is useful and necessary but not sufficient.
- The promise of data warehouses has fallen short with regards to broadly integrating all sources at the enterprise level as they proliferate like Tribbles.
- Master Data Management. With business needs and data constantly evolving, schemas are obsolete within moments of going into production. And it’s foolish to think that with just enough data engineering, an organization can create a schema which will work for every use case and every business unit. Simply put, there is no “one schema to rule them all.”
I don’t mean to seem too bleak on the above – I think all these efforts are necessary but insufficient to address the information needs of the modern enterprise. Enterprise users expect information experiences at work that are at least as good as what they get on the modern consumer internet.
Plus, it’s only going to get harder. As more people have access to analytics creation and consumption tools, more people will be copying more data and using more systems to do more things. Clearly, there has to be a sea change in how we deal with radical data heterogeneity.
So how do we solve it?
I believe that enterprises need to invest heavily in developing the skills, technology and talent around ‘DataOps’ (a term I may have coined back in 2015 blog post) – the blend of disciplines which recognize the interconnected nature of data engineering, integration, security, quality and analytics. DataOps enables large organizations to manage data as a fuel which can be repurposed throughout the organization to create strategic competitive advantage. My good friend Toph Whitmore has done a great job of describing modern DataOps here.
One of the very first goals of a DataOps team needs to be organizing an enterprise’s data around core entities like customers, suppliers and products. When these entities are well understood across many data sources, they can be used to power transformational analytics.
For instance, one of Tamr’s customers started organizing their spend data around suppliers to answer a simple question: ‘Are we getting the best terms any time we buy a part?’ That simple question – and managing their data across hundreds of systems – led them to identify hundreds of millions of dollars in savings on direct spend. It didn’t require fancy AI or deep learning. Just getting the data right provided a massive return in itself.
Just imagine what they can do with fancy AI and deep learning now that they have clean data. It turns out, when the Horse and Cart are oriented correctly it’s a pretty fun ride.
About the author: Andy Palmer is a serial entrepreneur who specializes in accelerating the foundation and growth of early-stage, mission-driven companies. He has helped start, fund or found more than 25 innovative companies in technology, health care and the life sciences. He is currently the CEO and co-founder of data transformation software provider Tamr.
Related Items:
Breaking Down the Seven Tenets of Data Unification
GE Invests on Data Prepper Tamr
Applications:
Enterprise Analytics
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States