

July 21, 2016
Supercharging Apache Spark with Flash and NoSQL

(Timofeev Vladimir/Shutterstock)
Apache Spark has become the defacto standard computational engine in the big data world. But as an in-memory technology, Spark has limitations. One of the ways people are getting around those limitations is by pairing Spark with superfast, Flash-based NoSQL databases, including key-value stores.
Big data architects have an abundance of technologies to work with at the moment, including Apache Spark, the computational Swiss Army knife that has quickly replaced MapReduce as the core data processing engine in Hadoop.
But Spark isn’t limited to Hadoop/YARN, and in fact has quickly gained traction in a variety of next-gen stacks, including running atop the Mesos resource scheduler, running as a standalone service in the cloud (see: Databricks), and paired with a variety of NoSQL and NewSQL databases, including Apache Cassandra, MongoDB, Aerospike, and MemSQL.
One of the more exotic pairings involves running Spark atop fast key-value stores, such as Memcache-D and Redis. This is becoming a popular approach for getting past the in-memory limitations of Spark. While Spark can spill to disk if it needs to when working with large data sets that don’t fit into memory, it doesn’t run nearly as fast or efficiently that way.
A key advantage of pairing Spark with a key-value store is better speed when iterating upon large data sets. If a big data workloads requires the engine to make multiple passes atop the data, perhaps to keep intermediate datasets around–such as for training machine learning algorithms—the data can sometimes be more efficiently stored on a key-value database than asking Spark to manage the data.
There are numerous examples of Spark running with key-value stores. One open source effort called IndexedRDD essentially pre-indexes entries, which leads to more efficient joins, point lookups, updates, and deletions, according to the project’s homepage on GitHub.
Commercial ventures are also looking to speed Spark on SSD-based key-value stores, including Aerospike, which supports using its Flash-based key-value store as the backing for Spark’s resilient redundant datasets (RDDs). Aerospike is also supportive of the open source “Aerospark” connector, which is also hosted on GitHub.
One company that’s developed a packaged solution with Spark and a KV store is Levyx. The Irvine, California-based company recently received $5.4 million in venture funding to build up its business around Helium, a transactional oriented key-value store designed to run atop Flash SSDs.
Reza Sadri, the CEO and co-founder of Levyx, recently discussed how Helium works with Spark to bolster the processing of big data workloads.
“The main issue with Spark is if the size of the data is very large, then you have to spread the data across a lot of nodes,” Sadri says. “So your cluster size grows a lot, if you have a few hundred terabytes of data.
“What we do,” he continues, “is we have an engine that enables indexing and sorting data very efficiently on Flash. We have integrated that into Spark so the type of application that requires processing large data sets…can run on much smaller clusters.”![]()
The proprietary technology, which Levyx started developing before Spark took off in popularity, essentially tricks Spark into thinking that it’s running on a big giant in-memory grid, when in fact it’s actually running on a relatively small cluster of servers featuring a large amount of SSD-based storage.
While Spark has its differences from MapReduce, it borrows the latter’s reliance on shuffling data among different nodes in between processing jobs. Keeping the data on SSDs, rather that the combination of RAM and spinning disk, enables Levyx to cut down on the shuffling.
“If you have 1,000 nodes, you have almost 1 million connections to move the data among nodes,” Sadri says. “If you have 100 nodes, then you have 10,000 connections. So if you use a technology like ours that utilizes Flash instead of memory so it can process a lot more data in a single node, then the number of these connections is going to decrease by n squared. That makes the network bottleneck much less….There’s quadratically less amount of data being shuffled across the nodes.”
One early Levyx customer, a cybersecurity company, turned to Helium after initially considering running Spark MLlib machine learning workloads on Amazon. According to Sadri, the 500 node cluster on AWS would cost about $30,000 per day, or about $1 million per month. After factoring Helium into the equation, the company figured out how to run it on a 50 node cluster, Sadri says.
There is a cost of adding Flash-based SSDs to Spark nodes, of course. But Flash costs considerably less than the equivalent DRAM. Getting Spark to think it’s talking to DRAM when in fact it’s talking to Flash is the “secret sauce,” says Levyx COO Luis Morales.
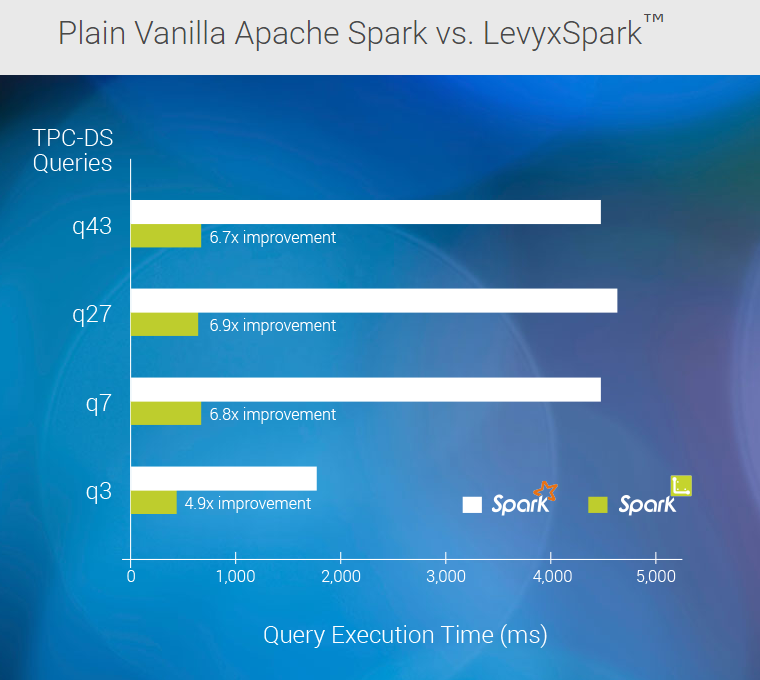
Results of a benchmark test between plain vanilla Spark and the LevyxSpark solution (Source; Levyx)
“Flash is inherently slower than DRAM. That’s the physics of it,” Morales says. “But with our software, if you can process a lot more data on the limited amount of DRAM that you have, and use Flash for the storage of the data, then in effect what you have is the ably to create very dense nodes with the same amount of DRAM that processes just as fast as a bunch of DRAM intensive nodes. That’s the secret sauce.”
To be sure, there are many other technological combinations that customers can come up with, especially considering that much of the technology involved is open source. Helium, alas, is proprietary, and a license will cost about $5,000 per TB per year. But for those hitting the upper bounds of what Spark can do, it could be worth it.
Related Items:
Which Type of SSD is Best: SATA, SAS, or PCIe?
Skip the Ph.D and Learn Spark, Data Science Salary Survey Says
Applications:
Data Mining
Sectors:
Retail
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States