

May 18, 2016
Hadoop 3 Poised to Boost Storage Capacity, Resilience with Erasure Coding
(image courtesy Nanyang Technological University)
The next major version of Apache Hadoop could effectively double storage capacity while increasing data resiliency by 50 percent through the addition of erasure coding, according to a presentation at the Apache Big Data conference last week.
Apache Hadoop version 3 is currently being developed by members of the Apache Hadoop team at the Apache Software Foundation. Akira Ajisaka, who is an Apache Hadoop committer and a PMC member, shared information about the next major release at last week’s Apache show in Vancouver, British Columbia.
Hadoop 3 has been in the works for a while now, and Hadoop 3 actually diverged from Hadoop 2 in 2011, according to Ajisaka, who works as a software engineer at NTT Data. Because Hadoop version 2 is based on Java Developer Kit (JDK) version 7, which reached end of life (EOL) in April 2015, the Apache Hadoop team agreed that it was time to work on Hadoop 3, he said.![]()
Hadoop 3, as it currently stands (which is subject to change), won’t look significantly different from Hadoop 2, Ajisaka said. Made generally available in the fall of 2013, Hadoop 2 was a very big deal for the open source big data platform, as it introduced the YARN scheduler, which effectively decoupled the MapReduce processing framework from HDFS, and paved the way for other processing frameworks, such as Apache Spark, to process data on Hadoop simultaneously. That has been hugely successful for the entire Hadoop ecosystem.
It appears the list of new features in Hadoop 3 is slightly less ambitious than the Hadoop 2 undertaking. According to Ajisaka’s presentation, in addition to support for erasure coding and bug fixes, Hadoop 3 currently calls for new features like:
- shell script rewrite;
- task-level native optimization;
- the capability to derive heap size or MapReduce memory automatically;
- eliminating of old features;
- and support for more than two NameNodes.
But the erasure encoding appears to be the most significant new feature in Hadoop 3. Erasure coding is an error correction technology commonly found in object file systems that are used to store extremely large amounts of largely unstructured data measuring in the hundreds of petabytes to zettabytes.
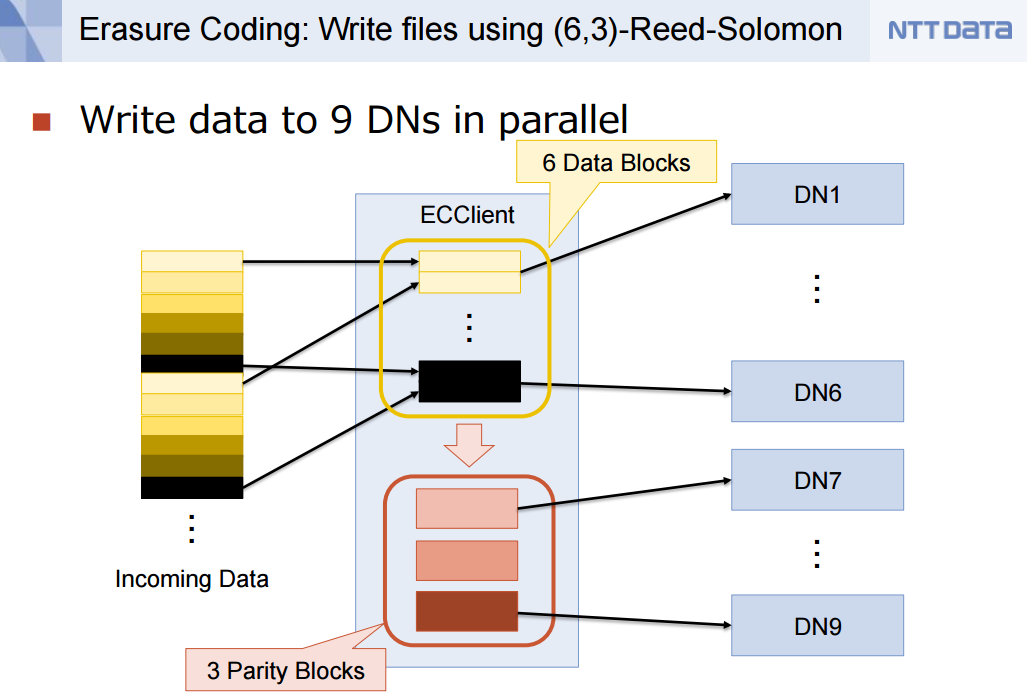
Hadoop 3 will use erasure codes to read and write data to HDFS
Erasure coding theory dates back more than 50 years, and essentially enables one arbitrary piece of data to be recovered based on other pieces of data (i.e. metadata) stored around it. It’s like an advanced form of RAID protection that rebuilds data automatically when hard disks fail, which happens predictably and in large numbers with big distributed systems like Hadoop.
Hadoop was originally developed with 3x data redundancy factor. That is, every piece of data is written in triplicate. This level of redundancy was sufficient to ensure a reliability level of 99.999 percent, Hortonworks (NASDAQ: HDP) architect Arun Murthy said at Hadoop Summit last year. If Hadoop only wrote data 2x, Murthy explained, it would basically eliminate one of the 9s of reliability. That may not sound so bad, until you consider the law of large numbers, and the fact that you can’t tell which piece of data in your Hadoop lake is corrupt. Even with “just” five-9s of reliability, the data reliability situation in Hadoop concerns people.
With the new erasure encoding in Hadoop 3, users will not only be able to increase their tolerance for failure by 50 percent, but it will cut the physical disk usage in half—essentially reducing that 3x disk consumption to 1.5x, according to Ajisaka presentation. That basically means you can store twice the amount of data on your current Hadoop cluster, or you can shrink your Hadoop cluster by half and store the same amount of data. Either way, it looks to save Hadoop customers big bucks on hardware outlays.
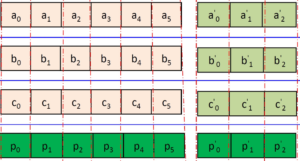
As it currently stands, Hadoop 3 will implement the (6,3)-Reed-Solomon erasure encoding algorithm, according to Ajisaka’s presentation. Reed–Solomon codes were developed in 1960 by Irving S. Reed and Gustave Solomon, who were then staff members of MIT Lincoln Laboratory, according to this Wikipedia entry.
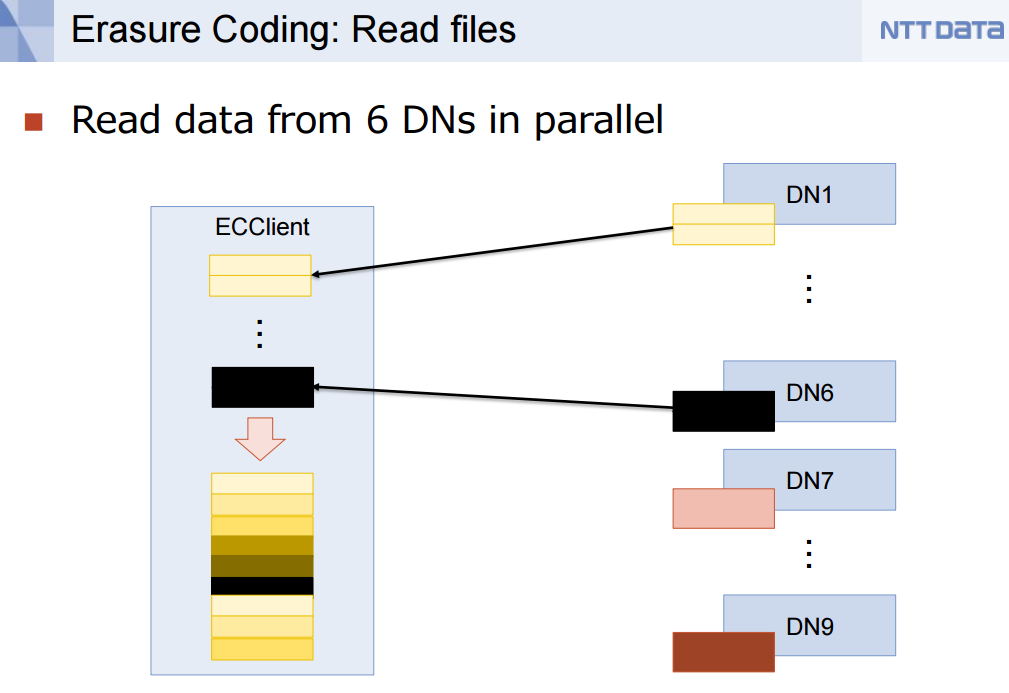
Erasure codes in Hadoop 3 will simultaneously boost the storage capacity of HDFS while improving resiliency
There are two phases to the implementation of erasure coding. Phase one, which is already available on the trunk, involves writing data in a striping fashion using small data cell sizes of 64KB. This approach will work for small files—which is an important design point, especially for the anticipated flood of small data expected from the IoT–but it doesn’t provide data locality.
Phase two, which is in development, involves writing data in a contiguous fashion using much larger block sizes of 128MB, which is the default block size for HDFS. This approach maintains provide data locality, which is important for some workloads, but will not work for small files.
You can expect to hear more about Hadoop 3 as the year goes on. “As far as I know, this is the first presentation to talk about Hadoop 3,” Ajisaka said during his presentation, the slides for which you can access here.
While the features that ship with Hadoop 3 have not been entirely nailed down and could change, Ajisaka said he expects alpha releases of Hadoop 3 to be released during the summer, and a GA version of Hadoop 3 possibly by November or December. But he warned that there’s still a lot of work left, and more developers are needed. You can view the core Apache Hadoop project page at hadoop.apache.org.
Related Items:
Hadoop Past, Present, and Future
Apache’s Wacky But Winning Recipe for Big Data Development
ODPi Offers Olive Branch to Apache Software Foundation
Applications:
Predictive Analytics
Vendors:
NTT Data
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States