

November 17, 2015
Why Google Open Sourced Deep Learning Library TensorFlow
Google last week open sourced TensorFlow, a new machine learning library used in deep learning projects. Even though the Web giant has just started using the software in its products, it apparently felt the need to donate it to the world. But why?
TensorFlow was originally developed by researchers and engineers working on the Google Brain Team within Google’s Machine Intelligence research organization for the purpose of conducting research into deep neural networks, Google says on the TensorFlow website.
“TensorFlow is a machine learning library that’s used across Google for applying deep learning to a lot of different areas,” says Rajat Mongo, a technical lead on the TensorFlow project, in a YouTube video.
At a technical level, TensorFlow facilitates numerical computation by using data flow graphs. According to Google (now a subsidiary of Alphabet (NASDAQ: GOOG), data flow graphs describe mathematical computation with a directed graph of nodes and edges. These data edges carry dynamically-sized multidimensional data arrays, or tensors, the company says. The software gets its name from the flow of tensors through the graph.
Google Research Fellow Jeff Dean says the framework has already been used in various Google offerings, including speech recognition, image recognition, email, and search products.
“Although it was initially a research project we’ve since collaborated with about 50 different teams at Google and deployed these systems in real products across a wide spectrum of products,” he says in the YouTube video.
The framework is “really powerful at doing various kinds of perceptual and language understanding tasks,” Dean says in the video. “These models are able to actually make it so computers can actually see or are actually able to underhand what is in an image when you’re looking at it or what is in a short video clip and that enables all kinds of powerful product features.”
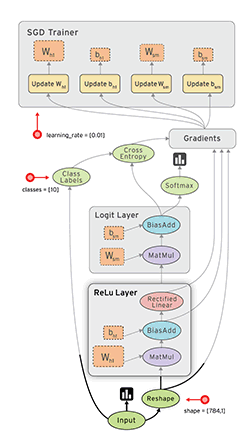
A TensorFlow graph
While TensorFlow originated on the research side of the house, Google’s developers have stated to use it too. This applicability to both researchers and developers is at the core of the reason Google gave for why it open sourced TensorFlow.
“Machine learning is the secret sauce for the products of tomorrow,” Greg Corrado, a senior search scientist at Google, says in the video. “It no longer makes sense to have separate tools for researchers to use machine learning and people who are developing real product. There should be one set of tools that researchers can use to try out their crazy ideas. And if those ideas work they can move them directly into products without having to rewrite them.”
According to Google, TensorFlow provides that common framework that facilitates communication and collaboration among researchers and developers. “It allows a researcher in one location to develop and idea and explore it and then just send code that somebody else can use on the other side of the world,” Corrado says. “We think we have the best machine learning infrastructure in the world and we have the opportunity to share that, and that’s what we want to do.”
But there be other reasons at play besides the openness of Google’s heart. Lukas Biewald, formerly a lead data scientist at Yahoo and founder and CEO of crowd microtasking startup CrowdFlower, suggests Google is not risking much by putting its algorithms out there.
That’s because the real secret sauce that differentiates Google from everybody else in the world isn’t the algorithms—it’s the data, and in particular, the training data needed to get the algorithms performing at a high level.
“A company’s intellectual property and its competitive advantages are moving from their proprietary technology and algorithms to their proprietary data,” Biewald says. “As data becomes a more and more critical asset and algorithms less and less important, expect lots of companies to open source more and more of their algorithms.”
TensorFlow is complete enough for Google employees to use it, but it’s not anywhere near a complete product. The TensorFlow website says that while the framework sports an easy to use Python interface and a no-nonsense C++ interface, “we’re hoping to entice you to contribute SWIG interfaces to your favorite language — be it Go, Java, Lua, Javascript, or R.”
Related Items:
Skip the Ph.D and Learn Spark, Data Science Salary Survey Says
Avoiding the Pitfalls of Bigger Data at the Human-Machine Interface
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States