

September 8, 2015
Intel Exec: Extracting Value From Big Data Remains Elusive

Intel Corp. is convinced it can sell a lot of server and storage silicon as big data takes off in the datacenter. Still, the chipmaker finds that major barriers to big data adoption remain, most especially what to do with all those zettabytes of data.
“The dirty little secret about big data is no one actually knows what to do with it,” Jason Waxman, general manager of Intel’s Cloud Platforms Group, asserted during a recent company datacenter event. Early adopters “think they know what to do with it, and they know they have to collect it because you have to have a big data strategy, of course. But when it comes to actually deriving the insight, it’s a little harder to go do.”
Put another way, industry analysts rate the difficulty of determining the value of big data as far outweighing considerations like technological complexity, integration, scaling and other infrastructure issues. Nearly two-thirds of respondents to a Gartner survey last year cited by Intel stressed they are still struggling to determine the value of big data.
“Increased investment has not led to an associated increase in organizations reporting deployed big data projects,” Gartner noted in its September 2014 big data survey. “Much of the work today revolves around strategy development and the creation of pilots and experimental projects.”
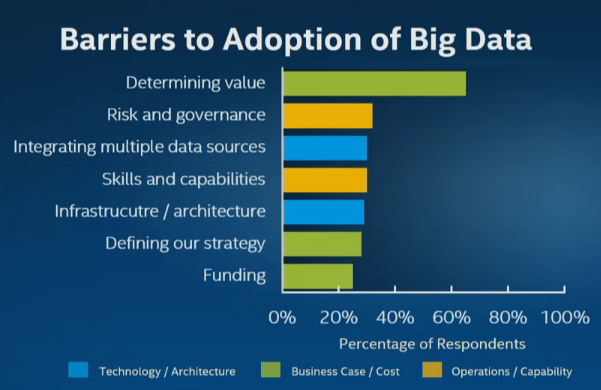
Source: Gartner
A key requirement is finding new use cases for big data, Intel’s Waxman argued. One example is attempting to replicate early use cases like retailers using big data to generate more revenue from online sales. The chipmaker is focusing on applications ranging from collecting and analyzing sensor data to managing smart grid and smart metering deployments.
There is little disagreement that big data “could really be an unseen driver for the overall datacenter business,” Waxman added.
Huge storage requirements for big data in the datacenter ranging as high as 35 zettabytes, according to estimates cited by the chipmaker, present an opportunity to “extract value from data,” Waxman stressed. As server performance increases and hardware costs continue to decline, so to, Intel notes, do storage costs per gigabytes. Intel and industry estimates peg the steep decline in storage costs at 90 percent over the last decade.
The chipmaker also is betting that the projected $41 billion total annual market for big data technologies over the next four years will include a growing percentage of hardware as more open source software replaces proprietary approaches.
Intel’s own big data strategy focuses on a combination of “scale-up” data platforms for in-memory analytics along with “scale-out” platforms for big data analytics. “We want to make sure that both a high-end, high-performance solution like SAP HANA as well as a commodity, mass big data scale-out solution such as Hadoop are optimized for the Intel architecture,” Waxman said.
Another element of Intel’s strategy was its 2014 investment in Cloudera and its decision to promote Cloudera’s distribution of Hadoop. The Intel-Cloudera big data roadmap adds security features while incorporating Intel’s new 3D XPoint memory technology, Waxman added.
Still, the Intel executive acknowledged, “Part of the challenge is making sure that there are actual solutions. Just putting all your data into a distributed data store doesn’t exactly solve that problem: You need analytics on top of that” and the analytics market “is a giant jigsaw puzzle.” For example, Waxman cited the machine-learning segment where there are more than 200 proprietary algorithms.
Ultimately, the world’s largest chipmaker is leveraging its market power to ensure that big data platforms and emerging tools like machine learning are optimized for Intel chips in the same way that much of the current IT infrastructure like servers and storage has been.
Recent items:
Intel Exits Hadoop Market, Throws in With Cloudera
Intel Hitches Xeon to Hadoop Wagon
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States