

August 25, 2015
Spark 1.5 to Incorporate ‘Tungsten’ Upgrades

A preview release of the Apache Spark open source in-memory processing framework incorporates major performance upgrades, according to Databricks Inc., the big data processing company founded by Spark’s creators.
Databricks said Aug. 18 is expects to release Apache Spark 1.5 in a “few weeks,” adding the preview release would allow the Spark community to conduct quality assurance testing.
Databricks said Spark 1.5 would focus on “under-the-hood changes to improve Spark’s performance, usability and operational stability.” Included in the latest release is the first phase of “Project Tungsten,” described as a new execution backend for DataFrames/SQL. The DataFrames API was introduced in February to expand big data processing to a wider audience.
Project Tungsten is touted as the largest change to Spark’s execution engine since the project’s inception and is designed to bring Spark closer to bare metal by improving memory and processing efficiency for Spark applications.
“Through code generation and cache-aware algorithms, Project Tungsten improves the runtime performance with out-of-the-box configurations,” Databricks engineers noted in a recent blog post. “Through explicit memory management and external operations, the new backend also mitigates the inefficiency in [Java virtual machine] garbage collection and improves robustness in large-scale workloads.”
Databricks also provided a performance comparison between Spark 1.4 and the latest version that implements Project Tungsten. The comparison shows “out-of-the-box” performance with no configuration changes for an aggregation query totaling 16 million records and 1 million composite keys. Runtime for an aggregation query on Spark 1.5 appears to be nearly four times faster on the new version, according to the performance comparison.
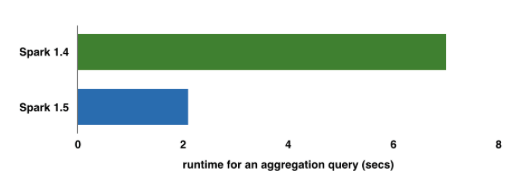
Source: Databricks Inc.
Another new feature dubbed “back pressure for Spark Streaming” is touted as allowing dynamic control of data ingestion rates ” to adapt to unpredictable variations in processing load,” Databricks said. “This allows streaming applications to be more robust against bursty workloads and downstream delays.”
Other new features in Spark 1.5 include new machine learning algorithms, a “sequential pattern mining” capability, improved R language support and upgrades for reporting memory usage.
San Francisco-based Databricks said Spark 1.5.0 would be released for testing on a “ready-to-go” cluster. Since multiple versions are supported, Spark 1.5 “canary clusters,” or the push of code changes, would be able to run with existing Spark production clusters, the company noted.
Databricks estimates that more than 220 open source developers from over 80 organizations contributed to the latest Spark release.
A Spark overview and a progress report on Apache Spark 1.5 can be found here.
The pace of Spark development is accelerating. Spark 1.4 was released in June, incorporating support for R notebooks and SparkR, the Databricks hosted service.
Spark got another boost in June when IBM announced it would integrate Spark software into the “core” of its analytics and commerce platforms. It also began offering Apache Spark as a service on its Bluemix cloud application development platform.
Recent items:
IBM, Databricks Join Forces to Advance Spark
Hortonworks Hatches a Roadmap to Improve Apache Spark
Applications:
Predictive Analytics
Technologies:
Frameworks
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States