

July 22, 2015
Big Data, Big Misnomer

Outside of the data warehouse profession, the phrase “Big Data” is still widely misunderstood. Even Google is confused: a Google search for “define ‘big data’” returns the definition: “extremely large data sets that may be analyzed computationally to reveal patterns, trends, and associations, especially relating to human behavior and interactions.”
But on a modern laptop with Excel you can easily analyze hundreds of millions of rows of data. Google (a “Big Data” pioneer) should know better. This article looks at what led to the rise of big data and why instead of being called “Big Data” it should perhaps be called “Parallel Processing for the Masses.”
Hadoop, the Elephant in the Room
The iPhone’s personal assistant, Siri, is backed by a Mesos cluster comprised of thousands of machines storing data in HDFS, the Hadoop File System. Hadoop’s logo is a yellow toy elephant, and it is Hadoop that is usually the underpinning technology of “Big Data.” But what is so special about this file system?
Hadoop’s file system allows you to store very large files that otherwise would be troubling to store and use with traditional tools or databases. Hadoop’s special sauce is in how the files are stored and accessed. The files are split apart into smaller “blocks” of size 64M to 256M, and the blocks for a single file are spread across a cluster of several machines. Each block is replicated across multiple machines (usually three), thus providing a mechanism for ensuring data is not lost if a single machine dies.
The fact that the files are broken into small chunks and split across multiple machines creates an opportunity for processing the data a block at a time and in parallel. Parallelism is the crucial part of “big data.”
Why is Splitting up the Data So Important?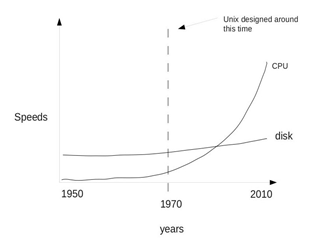
Moore’s law remains sacrosanct for some aspects of computing (CPU, RAM), but disk I/O speeds barely creep up over the last several decades. Therefore, it is not practical to store and interact with a large file. As mentioned above, with Hadoop, overcoming the disk I/O bottleneck is achieved by spreading the files across several physical disks across several machines.
Parallel Processing for the Masses
Hadoop gained popularity because, in addition to the cluster-based file system, it provided a special processing framework called MapReduce. This simple set of APIs and programs allowed the programmer to write the programs that could be shipped to the cluster and process the data that has been split across the cluster, in parallel.
What HDFS and MapReduce did was bring parallel processing capabilities to developers. Nowadays, a rich ecosystem of tools has brought parallel processing to the masses.
An Ecosystem
In Hadoop’s early days, custom Java programs adhering to the “MapReduce” APIs were required to interact programmatically with the data. However, MapReduce code is costly to write and difficult to troubleshoot and manage. MapReduce is inefficient for exploring datasets. Thus an ecosystem was born.
 The ecosystem has tools that span a wide variety of needs, including providing layers of abstraction that make interacting with the data simpler. Why write a MapReduce Java program when you can simply write SQL? HiveQL (the SQL-like tool) and Pig Latin (a functional programming language) were some of the early tools on the scene and have grown through community support. A large list of the current ecosystem tools can be found here.
The ecosystem has tools that span a wide variety of needs, including providing layers of abstraction that make interacting with the data simpler. Why write a MapReduce Java program when you can simply write SQL? HiveQL (the SQL-like tool) and Pig Latin (a functional programming language) were some of the early tools on the scene and have grown through community support. A large list of the current ecosystem tools can be found here.
Management Mess
Cluster Management
Hadoop is a challenge for IT management. To begin: a cluster of several machines is required; small clusters for hundreds of Terabytes (TBs) are usually comprised of less than ten machines, but large clusters like the ones at large enterprises often consist of hundreds of machines. The cluster of machines must be linked with high-speed network connections. Nonetheless, business requirements and data requirements need to be understood in order to spec out a cluster.
Cloud to the Rescue
For targeted use cases, dynamically allocating Hadoop clusters on the public cloud is possible. Genworth Financial takes this approach for executing some financial models and dynamically spins up an Amazon Web Services (AWS) cluster on demand.
The Human Problem
Arun Murthy, Hortonworks founder and an early Hadoop contributor, recently said, “… data management, data governance is a piece of Hadoop that has not been solved.” As HDFS is nothing more than a fancy file system with a set of tools for interacting with it, it is easy for a cluster to become cluttered and difficult for analysts and developers to use. Data Management Platforms try to address this concern by providing an information radiator – a web-based view into the files residing in the cluster – along with tools for managing the entire data pipeline across the various roles in an organization, including streaming ingestion, entity management with HCatalog integration and workflow management with pre-built actions that perform common activities such as Hive partition management and data quality checks.
The Future
The Hadoop ecosystem is rapidly evolving. Apache Spark is a recent addition to the Hadoop ecosystem that has wide support (it is the most active Apache project), and for good reason. MapReduce, as mentioned earlier, provided a basic parallel processing framework, but it is a rigid API and forces processing to incur excess disk I/O between its Map and Reduce phases. Spark, on the other hand, provides a rich API, multiple interfaces (Scala and Python command-line, SQL command line, APIs), language interoperability, data science-focused libraries (R, machine learning, graph analytics), and seamless external data source integration. Spark is tailored for in-memory operations so operations that must revisit data points, like regression analysis or K-means, can revisit in-memory structures.
The phrase “Big Data” remains in the lexicon of computing and business although the technology stack that is usually associated with the phrase has evolved much beyond the commonly given definitions (see this article for 12 common definitions of “Big Data”). The technology, popularized by the open source Hadoop project, proved its worth by tackling the traditional challenges of storing and processing of large datasets (billions or trillions of rows of data) for large enterprises. Hadoop is poised to be a key component for the IoT era. However, the phrase “Big Data” is likely to remain. “Parallel Processing for the Masses” does not roll off the tongue quite as easily.
About the author: Craig Lukasik is Senior Solution Architect at Zaloni, Inc.  Craig is highly experienced in the strategy, planning, analysis, architecture, design, deployment and operations of business solutions and infrastructure services. He has a wide range of solid, practical experience delivering solutions spanning a variety of business and technology domains, from high-speed derivatives trading to discovery bioinformatics. Craig is passionate about process improvement (a Lean Sigma Green Belt and MBA) and is experienced with Agile (Kanban and Scrum). Craig enjoys writing and has authored and edited articles and technical documentation. When he’s not doing data work, he enjoys spending time with his family, reading, cooking vegetarian food and training for the occasional marathon.
Craig is highly experienced in the strategy, planning, analysis, architecture, design, deployment and operations of business solutions and infrastructure services. He has a wide range of solid, practical experience delivering solutions spanning a variety of business and technology domains, from high-speed derivatives trading to discovery bioinformatics. Craig is passionate about process improvement (a Lean Sigma Green Belt and MBA) and is experienced with Agile (Kanban and Scrum). Craig enjoys writing and has authored and edited articles and technical documentation. When he’s not doing data work, he enjoys spending time with his family, reading, cooking vegetarian food and training for the occasional marathon.
Related Items:
Big Data’s Small Lie – The Limitation of Sampling and Approximation in Big Data Analysis
‘What Is Big Data’ Question Finally Settled?
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States