

June 9, 2015
JethroData Indexes Its Way to $8.1M SQL Payday
There’s no shortage of SQL-on-Hadoop projects in the works. Hive, Impala, Presto, HAWQ—they all tout a certain advantage. But they all look mostly the same to Eli Singer, the CEO of JethroData, which today landed $8.1 million in Series B funding to continue development of his unique SQL query engine for Hadoop.
While all Hadoop SQL engines on the market today are unique in their own way, they’re all architecturally similar in one manner. According to Singer, they all run full scans over the database to get the answers. “Everybody just took the same architecture that we had for Teradata and Vertica, and just moved it to Hadoop,” he tells Datanami.
This approach works in some situations, but as the data set gets bigger, the full-scan approach can lead to bigger latencies and longer delays. This is not an issue if you’re analyzing a big data set in search of patterns, as you might need to do in a predictive analytics project. You’re going to need to look at every row anyway.
But if your analysts are doing more targeted searches–what is commonly the case with so-called interactive queries or ad-hoc analytics–then the full-scan approach can introduce latencies that are unacceptably long.
Enter the Index
JethroData‘s solution to this problem involves re-introducing indexing back into the equation.
Indexing, of course, is nothing new. Indexes are heavily relied upon in relational databases to reduce latencies in modern business systems. The database schemas relied upon by modern ERP system are rife with all sorts of pre-built tables to speed up access times to frequently used data, including powering the reporting and business intelligence (BI) tools that access production ERP databases.
But in the fast-paced world of big data analytics—where Hadoop’s focus is on ingesting data as quickly as possible and figuring out what to do with it later—indexing has never really caught on.
When ingesting terabytes of data per day, it’s simply too expensive computationally to use indexes, which typically requires putting a lock on the tables while the index is being updated.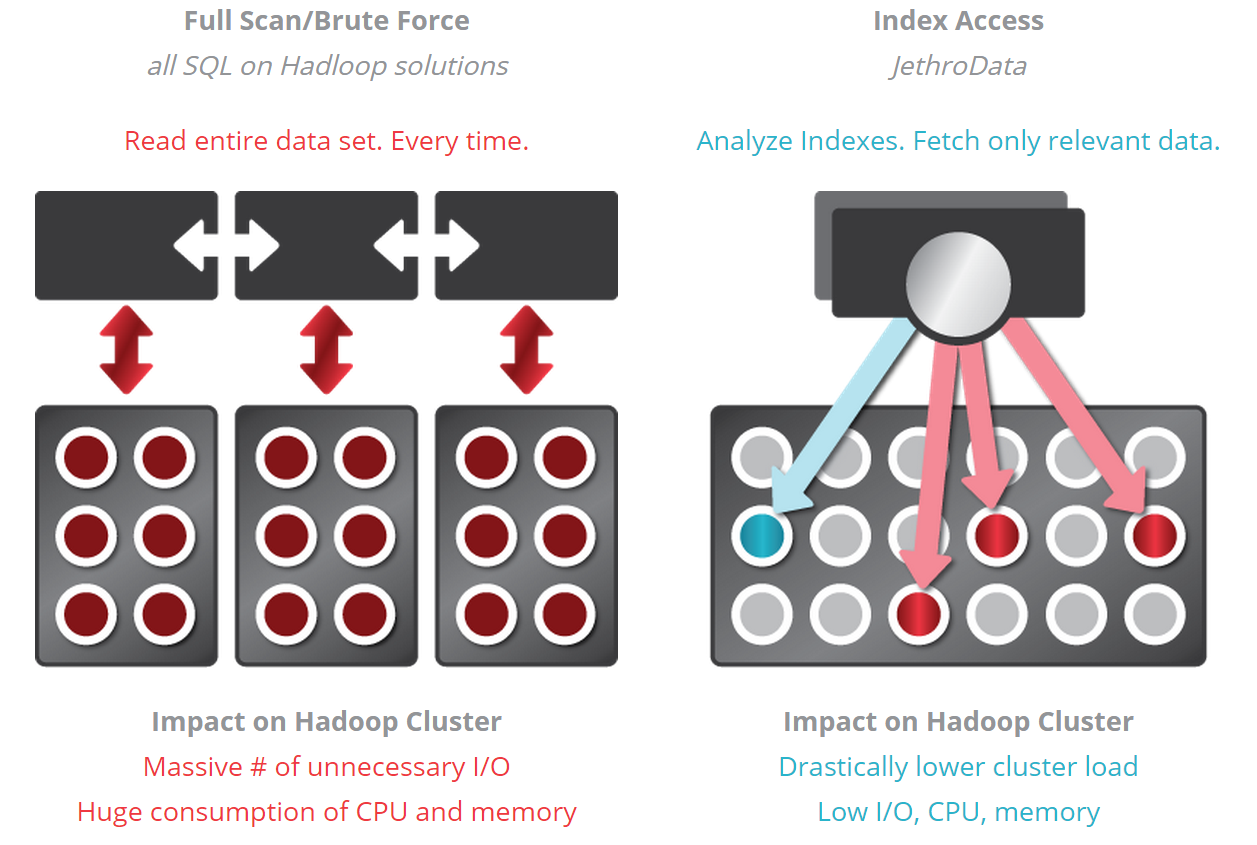
But done correctly, indexing can work in Hadoop without the compromises, according to Singer. JethroData has essentially taken a column-oriented database (like Vertica or Impala) and combined it with a search engine indexing tool. The resulting columnar-based database is fully indexed, where each additional column of data is treated as its own index.
Technically, JethroData uses B-Tree indexing technology to create indexes that are “sorted, multi-hierarchy, compressed bitmaps.” As more data is added to HDFS–which is an append-only system (unless you’re using MapR‘s distribution, which allows random updates to the file system)–JethroData does not update the existing indexes. Instead, it adds them to the end of the index, basically allowing duplicate index entries (which eventually get cleaned up). To keep from getting lost in a sea of appends, JethroData essentially creates an “index of indexes.” In this manner, it can make indexing work on Hadoop without expensive table locks.
Indexing Performance
This approach brings tremendous performance advantages because the SQL queries can use the indexes to find the relevant data, instead of scanning the entire database. JethroData is focusing primarily on interactive queries, such as those generated by BI tools from Tableau, Qlik, and Microstrategy.
“If my query is looking for all males over 40 living in Florida who have two cars and two kids, in JethroData, we use indexes for gender, age, state, marital status etc.” Singer says. “Each one of those indexes narrows down the search. You don’t have to go and read the entire population.”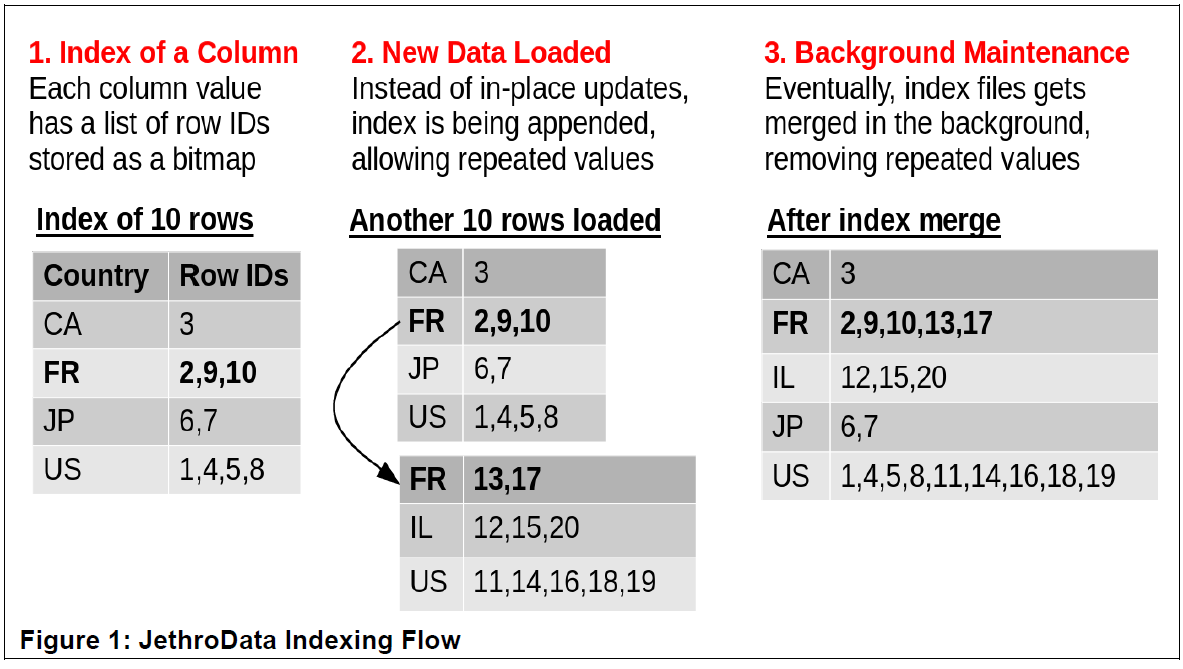
Using this “surgical strike” approach instead of the “brute force” approach of the full-scan SQL engines brings another advantage: The more you drill down and specify the parameters of the SQL query, the faster the query runs.
The JethroData SQL engine, which installs on one or more nodes in a Hadoop cluster (it also supports Amazon S3), can process a billion rows of data per hour. “For most use cases, that’s more than enough,” Singer says. The sweet spot for JethroData involves data sets with 5 billion to 50 billion rows, where analysts are doing targeted queries using a BI tool.
There are some small caveats to JethroData’s approach. First, it doesn’t scale indefinitely. The system currently has a limit of about 4,000 columns of data, or 4,000 indexes. You’ll need to make your data fit within this limit.
Also, JethroData works best on “manicured” data, according to Singer. You can’t throw the SQL engine against a bunch of raw data sitting in HDFS and expect to run lightning-fast Tableau queries against it. The data must first be hammered into a more structured form, using an ETL tool or other pre-processing approach, such as MapReduce or Spark routines. Of course, customers who are using traditional BI tools against Hadoop already face this dilemma—only in most cases, they’re not hitting data in Hadoop (as JethroData does), but instead are moving it to a separate box.
Today JethroData announced that it has closed an $8.1 million Series B financing round, bringing its total financing to-date to $12.6 million. The latest round was led by Square Peg Capital, and including existing investor Pitango Venture Capital.
“Eli and the amazing team at JethroData are bringing a revolutionary technology to enterprises,” says Square Peg Capital partner Arad Naveh. “Hadoop users have gained great scale and cost effective storage, largely at the expense of performance. With JethroData, enterprises quickly see improved performance, making Hadoop a viable enterprise infrastructure.”
Singer plans to use the funding to double R&D investments. He’ll also increase sales and marketing initiatives.
Related Items:
How Advances in SQL on Hadoop Are Democratizing Big Data–Part 1
How Advances in SQL on Hadoop Are Democratizing Big Data–Part 2
Top Three Big Data Startups at Strata
Technologies:
Middleware
Vendors:
JethroData
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States