

April 7, 2015
Deep Gooses MySQL Performance with New Database Math

Deep Information Sciences today unveiled a new storage engine for MySQL that it claims will blow any other database engine out of the water in performance and scalability. The secret to creating a 1 trillion row database or ingesting data at the heady rate of 60 million rows per minute, they say, is the total elimination of 1970s-style math from the stack.
Despite the recent proliferation of new database management systems, such NoSQL and NewSQL databases, most databases today use the same underlying math, called B-Tree indexing, to tell the database where to store the data. While there are some databases that have ventured outside the B-Tree world–such as Tokutek’s TokuDB, which brings Fractal Tree indexing to MySQL–the majority of relational, NewSQL, and NoSQL databases use the same standard B-Tree indexing math.
The problem is, B-Tree indexing imposes inherent limits on an application, says Thomas Hazel, the founder of Deep Information Sciences and its chief scientist/architect. “Think of classic B Plus trees, where the behaviors and structures are fixed, meaning there are certain limits where the read balancing has to happen,” he says. “Nodes and leaves and branches have to be created based on the specific order of the B Tree, for instance.”
About seven years ago, Hazel began work on an alternative to B-Tree, which he calls CASSI, which stands for Continuously Adaptive Sequential Summarization of Information. CASSSI forms the basis for the Deep Engine that became available today.
“We took the behavior and data structure and split them apart so that we don’t 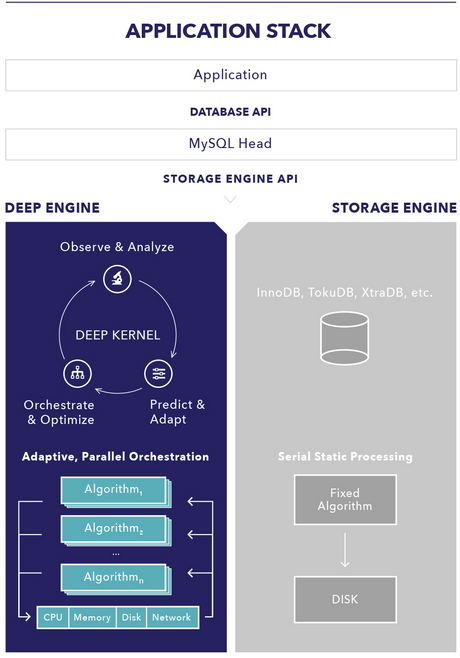 have to follow the fixed nature of the existing math that’s used to organize the B-Tree,” Hazel tells Datanami. “We actually see the capability of what the hardware has with CPU, memory, and disk I/O performance, and we’ll choose to defer, defrag in memory, or compress in memory, before we even try to do a split or merge in a classical sense.”
have to follow the fixed nature of the existing math that’s used to organize the B-Tree,” Hazel tells Datanami. “We actually see the capability of what the hardware has with CPU, memory, and disk I/O performance, and we’ll choose to defer, defrag in memory, or compress in memory, before we even try to do a split or merge in a classical sense.”
Instead of continually writing data to disk, CASSI uses machine learning algorithms to better predict the optimal moment to write data to disk, based on the particular configuration and capability of a computer, says Chad Jones, the chief strategy officer for Deep IS, which is based in New Hampshire but is moving down the road to Boston.
“As things come in we’ll say, ‘What’s the best way to handle this by splitting up the in-memory and disk structures,'” Jones says. “We’re able to put an adaptive layer in between [the appellation and the database]. It allows us to say ‘I’m not going to write this down right now because the data hasn’t quiesced. I keep seeing a lot of changes in this one column of data, so let’s defer writing until we know it’s ready to be written and then write it, so we eliminate a lot of extra work in the database.'”
The results are somewhat astounding. According to Deep IS, its Deep database engine can deliver a 64x speed-up over a highly tuned instance of InnoDB, another database engine that users can plug into MySQL. Analytics runs at least twice as fast as other database engines, the company says, while transactions (Deep Engine maintains ACID compliance) will see a 40x speedup. Deep IS can cut database disk IOPS by 80 percent, while storage is slashed by 30 percent when no compression is used, and 80 percent when Deep IS’s compression algorithm is turned on.
At the upcoming Percona Live conference (Percona is the main driver behind enterprise MySQL), Deep IS is going to demonstrate three databases: a 10 million row MySQL database with heavy indexing, a 100 million row MySQL database with heavy indexing, and a one trillion row database, ostensibly without any indexing.
“We’re not recommending you to put a trillion rows underneath a table,” Hazel says. “We’re just demonstrating that the mathematics and the new data structures we’re talking about allow a customer to really scale up beyond what they thought was physically possible.”

Deep IS abides by what it calls “fair benchmarking” practices
MySQL customers don’t have to make any changes to their existing applications or databases to take advantage of the Deep Engine. “Because it’s implemented at the storage-engine level, you slide this in underneath the MySQL head, and the APIs and queries are unchanged,” Jones says. “All of it is unchanged as far as the application is concerned. You just see all of a sudden a massive uptick in scale and performance without anything having to be done to your applications.”
All that fresh database performance will also eliminate the need for database administrators to constantly fiddle and tweak stuff in an attempt to eek every last bit of performance or scalability’ from a MySQL database.
“What a DBA would typically do about addressing workload performance issues is they change page sizes, they change their schema. We’re removing that requirement so they can focus on their application,” Hazel says. “We’ll change page sizes on the fly, depending on the workload and the type of data that’s being ingested. It really removes some of the tedious nature of what a DBA would do. We are that DBA inside the box.”![]()
MySQL was an obvious target for Hazel and his team of engineers at Deep IS, which received a $10 million round of Series A financing in 2013. But it’s not the last database market that Deep IS will attempt to disrupt. “We’re going to do NoSQL with MongoDB by the end of year,” Jones says. “We’ll bring those benefits to NoSQL as well. NoSQL databases are trading out feature to get more scalability…on that legacy math.”
Deep Engine is packaged and delivered as 10MB down–“or about the size of Lynyrd Skynyrd’s Free Bird,” Jones adds. The Deep Engine is available now for free to academic institutions and organizations with less than $1 million in revenues; larger companies will have to pay a licensing cost, which Jones promises is not that much.
Related Items:
MongoDB Goes Pluggable with Storage Engines
Deep Attempts to Recreate the Single Platform, General Purpose Database
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States