

June 3, 2014
DataTorrent RTS Clocks In at 1.5B Events per Second

What would you do with a system that could process 1.5 billion events per second? That’s the mind-boggling rate at which DataTorrent’s Real-Time Streaming (RTS) offering for Hadoop was recently benchmarked. Now that RTS is generally available–DataTorrent announced its general availability today at Hadoop Summit in San Jose–we may soon find out.
That 1.5-billion-events-per-second figure was recorded on DataTorrent’s internal Hadoop cluster, which sports 34 nodes. Each node is able to process tens of thousands of incoming events (call data records, machine data, and clickstream data are common targets) per second, and in turn generates hundreds of thousands of secondary events that are then processed again using one of the 400 operators that DataTorrent makes available as part of its in-memory, big-data kit.
When all the levels of operators and events are added up, RTS handled a total of 1.5 billion events per second. To put that into perspective, DataTorrent says that processing 1 billion data events per second is the equivalent of processing 46 cumulative hours of streaming Twitter data in one second. That is a lot of data.![]()
Not that anybody is asking for that much event-processing capacity at the moment. “We feel we’re at a point with 1.5 billion events per second where we have plenty of head room,” says John Fanelli, vice president of marketing at DataTorrent. “None of the prospects we work with have gotten anywhere near the headroom we provide with 1.5 billion events per second.”
RTS runs 1,000 times faster than Apache Storm, and about 100x faster than Spark Streaming. (Those numbers come from DataTorrent itself.) If the future of Hadoop is real-time data processing, then the folks at DataTorrent have to feel pretty good about where they are.
“I believe we can go further,” DataTorrent co-founder and CEO Phu Hoang says regarding the throughput figure. How much further do we need to go? How much data do we really need to process? “These things are coming faster than we think.”
Hoang sees a bright future for DataTorrent processing data coming off the Internet of Things (IoT), as well as “classic” big data use cases, such as online advertising analysis. “When you talk to some of these customers, it’s not about the incoming rate of streaming throughput. It’s what they’re thinking about or struggling with. In other words, what kind of processing do they want to do when they bring the event in?”
In the online advertising scenario, batch-oriented MapReduce applications running on Hadoop enabled advertisers to optimize the delivery of ads to people based on a number of factors. Companies crunch the various attributes of clickstream data, including which publisher, which advertisers, the ad size, the format, and location, to come up with an optimal blend. There can be more than two dozen attributes available, but there’s rarely the time to go that deep.
With DataTorrent, companies can perform the same type of processing, but do so in real time, and potentially go much deeper into the data. “Now when we give them this kind of infrastructure, it really allows us to open up and look at what other attributes we want to put in there,” Hoang tells Datanami. “So there’s an exponential explosion in terms of the number of events you have to look at. While nobody is doing it today, it’s only because they’ve been taught that no such thing exists. It can really open up the exploration of the data that they have.”
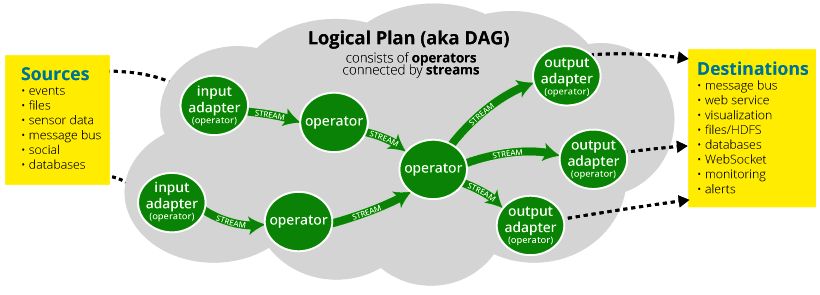 DataTorrent is one of a promising new class of YARN-enabled applications for the Hadoop 2 paradigm. The company took care to shield developers from the underlying plumbing going, with the goal of letting them focus on the business logic. The idea is let developers dip into the library of 400 operators to string together event-processing systems, using Java they’re familiar with.
DataTorrent is one of a promising new class of YARN-enabled applications for the Hadoop 2 paradigm. The company took care to shield developers from the underlying plumbing going, with the goal of letting them focus on the business logic. The idea is let developers dip into the library of 400 operators to string together event-processing systems, using Java they’re familiar with.
Relying on YARN for resource management enables RTS to run on the same Hadoop cluster as batch-oriented MapReduce applications. While real-time streaming is sometimes seen as a replacement for batch applications, they can co-exist peacefully.
“We find we’re quite complementary to batch processing,” Hoang says. “When there’ a lot of I/O going on, we’re actually using the cluster for the memory and processing. You can have these real-time streaming applications that run concurrently with other batch doing a lot of I/O application within a single cluster.”
DataTorrent owes a lot to the MapReduce coders who came before it, as they popularized the concepts around parallel programing. “That in a way is something that Hadoop already included, the notion of distributed computing,” Hoang says. “So I think we got to stand on the shoulder of Hadoop…We think it’s a very smooth transition going for someone with familiarity with a distributed computing concept like MapReduce to us.”
Related Items:
It’s Sink or Swim in the IoT’s Ocean of Bigger Data
Crossing the Big Data Stream with DataTorrent
Vendors:
DataTorrent
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States