

April 2, 2014
Hortonworks Drives Stinger Home with HDP 2.1
Hortonworks today unveiled a major new release of its Hadoop distribution that puts significant new capabilities into the hands of its customers. The speed and scale of SQL processing in Apache Hive were improved with the final phase of the Stinger initiative, while the additions of Apache Storm and Apache Solr in HDP 2.1 open up new ways for customers to manipulate their data. Security and data governance were bolstered with Apache Knox and Apache Falcon, respectively, while Apache Spark is now available as a tech preview.
![]() You will notice a lot of “Apaches” in discussions about the latest release of the Hortonworks Data Platform. That’s by design, according to Jim Walker, director of product marketing for the Palo Alto, California company.
You will notice a lot of “Apaches” in discussions about the latest release of the Hortonworks Data Platform. That’s by design, according to Jim Walker, director of product marketing for the Palo Alto, California company.
“This is an incredibly significant release, not just for Hortonworks but the [open source] community as well,” he tells Datanami. “The community has been building Hadoop like none other before. HDP 2.1 is a significant release because it rounds out all enterprise Hadoop capabilities, in a single distribution, all delivered completely open.”
The most significant new features in HDP 2.1 arguably revolves around Hive and the Stinger initiative that Hortonworks spearheaded more than a year ago to improve interactive SQL processing on Hadoop. With the delivery of Hive .13 (which replaces the MapReduce innards with Tez), SQL processing is 100 times faster than it was before the Stinger initiative started 13 months ago, Walker says; performance improvements on Hive .12 are more modest.
Stability at scale has also been bolstered, and Hive can be counted on to handle queries with hundreds of gigabytes and to perform joins involving petabyte-size data sets and fact tables, he says. Several new SQL semantic commands have been added too.
The Hive 13 improvements are the result of a group effort that included 145 developers from 44 companies, who committed more than 330,000 lines of code. It even included contributions from Microsoft SQL Server developers, who contributed functionality around vectored queries. 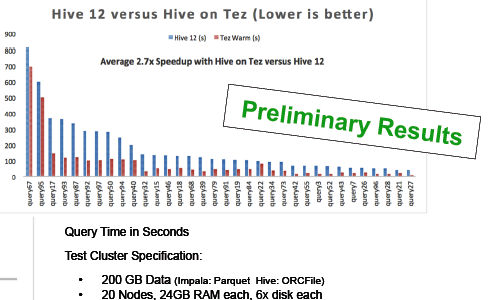 “It’s 10 times what any individual company can do,” Walker says, referring to Cloudera and its Impala initiative to improve SQL processing.
“It’s 10 times what any individual company can do,” Walker says, referring to Cloudera and its Impala initiative to improve SQL processing.
The burst of activity around the Stinger initiative is over, and now it’s back to regular Apache Hive project. “Stinger phase 3 is now done. The Stinger project is over,” Walker says. Going forward, the Hive community will be working on adding new functionality, such as support for ACID transactions and update, delete, insert functions, which are planned for the next release.
The addition of the Apache Storm stream processing engine and the Apache Solr search engine to HDP 2.1 opens up new use cases for Hadoop users. Apache Storm, in particular, can trace its roots to the delivery of the YARN resource manager in Apache Hadoop version 2 last October.
“It really opened up the view for Hadoop to be this multi-tool system for processing data,” Walker says. “I can now analyze streams coming into Hadoop, land that data and have algorithms working on that data, say, via Pig script, and all at the same while, loading the data into HBase, so I can have low-latency access to it. What we’re looking at is end to end view of the use case and really opening up the use cases for people to actually do things with their data.”
While Hive, Storm, and Solr introduce new or enhanced data processing engines to HDP 2.1, the addition of Apache Knox and Apache Falcon functionality will shave off some of Hadoop’s rough edges and help it behave like a responsible and well-groomed member of the corporate data center.
Apache Knox provides perimeter security and access control list (ACL) functionality for Hadoop, as well as enabling single sign on capabilities via integration to LDAP and Microsoft Active Directory. The functionality was developed by the open source community in conjunction with Microsoft, says David McJannet vice president of marketing for Hortonworks.
 Apache Falcon, meanwhile, implements a data governance framework for Hadoop. Specifically, Falcon will help manage how data is acquired and processed, where and when it’s replicated, and under what circumstances data can be redirected outside of Hadoop. The software, which was contributed to open source by the Indian company InMobi, will also provide an audit trail.
Apache Falcon, meanwhile, implements a data governance framework for Hadoop. Specifically, Falcon will help manage how data is acquired and processed, where and when it’s replicated, and under what circumstances data can be redirected outside of Hadoop. The software, which was contributed to open source by the Indian company InMobi, will also provide an audit trail.
While it’s not formally supported yet by Hortonworks, the Apache Spark in-memory processing engine is now available as a technology preview with HDP 2.1. Hortonworks already has some customers using Spark, which is currently gaining a lot of momentum in the Hadoop community as a speedier alternative to MapReduce that also comes with a set of machine learning algorithms, graph libraries, streaming functionality, and SQL interface.
“There’s no doubt in-memory processing is absolutely hot,” Walker says. “Is it right for some uses case? Absolutely, we completely agree with that. But we want to make sure that [Spark] is enterprise ready. So it’s not just the large Web companies on the West Coast that are adopting it, but everybody. In order for that to happen, it has to integrate with all the management tools. Security has to be built into it. All those key enterprise capabilities need to be there.”
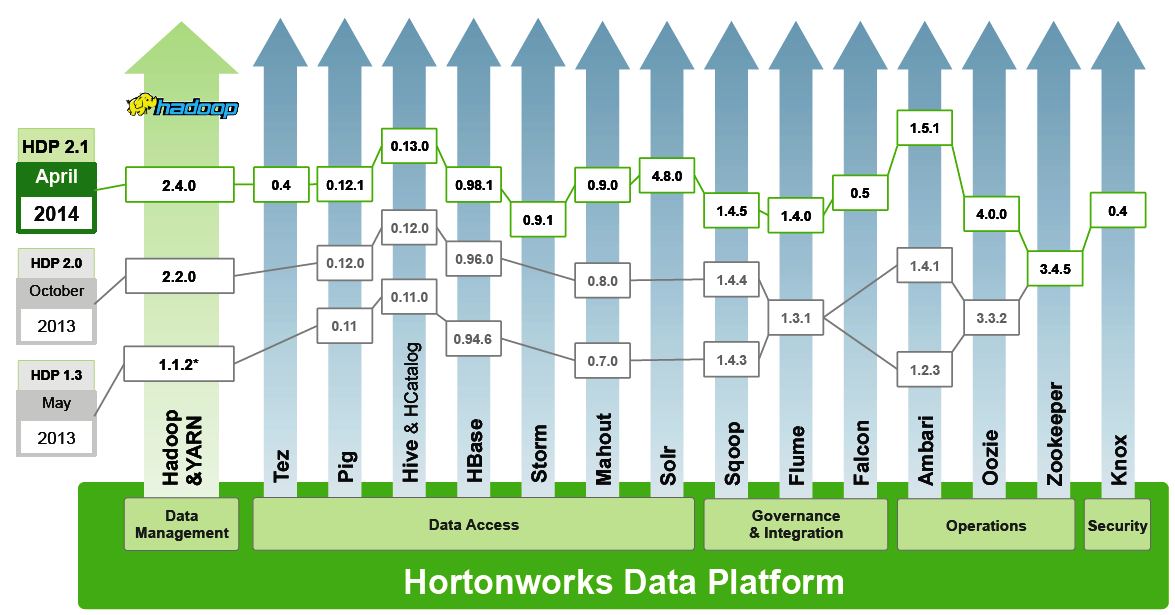
HDP 2.1 includes lots of other stuff too, including new features in Ambari, Baikal, HBase, Flume, Mahout, Oozie, Pig, Scoop, and Tez. The software becomes generally available on Windows and Linux on April 22.
Related Items:
Glimpsing Hadoop’s Real-Time Analytic Future
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States