

February 10, 2014
Red Hat Deal Gives Hortonworks Enterprise Clout
The strategic partnership that Hortonworks and Red Hat unveiled today is interesting on several fronts. For starters, there are the joint development projects, most notably the connector that allows Hortonworks’ Hadoop distribution to talk natively to Red Hat Storage. Beyond that, the partnership with the $10-billion commercial open source software company provides a glimpse of who Hortonworks might want to be when it grows up.
![]() The roots of the partnership go back over a year, when “upstream” open source software developers affiliated with the two companies started working together across various Hadoop, JBoss, Fedora, and OpenStack projects. The first round of integration work on three projects is nearly done, and will be made available via open source license when it’s ready.
The roots of the partnership go back over a year, when “upstream” open source software developers affiliated with the two companies started working together across various Hadoop, JBoss, Fedora, and OpenStack projects. The first round of integration work on three projects is nearly done, and will be made available via open source license when it’s ready.
The companies announced the start of a beta program for the Hortonworks Data Platform (HDP) plug-in for Red Hat Storage. The plug-in will enable HDP to work on data stored in Red Hat Storage platform, which essentially allows customers to build their own petabyte-scale private cloud storage platform (i.e. Amazon S3 without the security and data transfer issues).![]()
When it’s ready, customers will just need to download the latest release of HDP with Ambari, and the software will virtualize the connections, enabling HDP to write and read data to and from Red Hat Storage as a Hadoop compatible file system, says Red Hat director of storage business strategy Greg Kleiman. “It basically puts an HDFS API on top of it, so YARN and Pig and Hive and MapReduce think they’re saving it to HDFS, but it’s really going to Red Hat Storage,” he says.
Developers are the target of the work Hortonworks and Red Hat are doing to integrate HDP with OpenJDK. “We’re not asking them to write low-level MapReduce code with this integration,” says Hortonworks vice president of corporate strategy Shaun Connolly. “They’re actually able to operate at a much higher level, a much more agile layer.”
The new JBoss Data Virtualization connector will make it easier to pull outside data into Hadoop, including data residing in third party data warehouses, SQL and NoSQL databases, enterprise and cloud applications, and flat and XML files. This will allow enterprise customers, and in particular application developers, “to represent the data inside of Hadoop through a common data model and therefore allow it to be combined with data sources outside of Hadoop, like OTLP systems, transaction systems in large enterprise, or large SQL databases,” Connolly says.
The third area of current collaboration between Hortonworks and Red Hat is in the OpenStack arena. “We’ve been doing a lot there together in the upstream community around the Savanna project,” Kleiman says. “We are already aggressively collaborating around bringing Hadoop, and specifically elastic Hadoop, to OpenStack, which basically allow enterprises to get all the best of elastic MapReduce, but inside on their secure private cloud.”
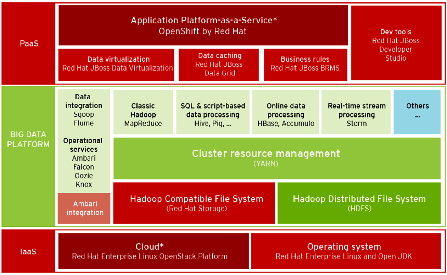 |
|
| The Big Data Analytics stack, in green (Hortonworks) and red (Red Hat) | |
When you add it all up, the combination of Hortonworks’ big data analytics and Red Hat’s infrastructure offerings create a platform that can support any deployment scenario, from on premise running on RHEL to virtualized running on Red Hat Enterprise Virtualization to cloud running on OpenStack, Kleiman says. “It gives operators inside the enterprise more flexibility, and gives developers more options on how to deploy,” he says.
The new partnership seems like a natural fit on many levels. (The companies call this an extension of an existing partnership, but Red Hat was not listed among Hortonworks’ partners on the company’s website). The most obvious similarity is the strong commitment to open source at both companies. Red Hat, of course, was the initial pioneer of the open source movement when Linux first started gaining steam in the early 2000s. Red Hat was also the first company to spearhead the commercial open source model that so many big data analytics companies today are emulating.
While all Hadoop distributors talk about their commitment to open source, none go so far as Hortonworks in backing it up with action. When Red Hat surveyed the field of Hadoop vendors, Hortonworks stood out for its commitment to open source software and its ability to test Hadoop at scale, Kleiman says. “The common theme is we’re both 100 percent open source companies,” he says. “Hortonworks is absolutely the best match for Red Hat among all the Hadoop distributions.”
Meanwhile, working with Red Hat gives Hortonworks enterprise clout and backing as battles for Hadoop supremacy with the likes of Cloudera, IBM, Pivotal, and Intel. Red Hat survived epic platform battles with Microsoft–which, ironically, is another strategic ally of Hortonworks–and today commands $1.3 billion in revenue and a market capitalization in excess of $10 billion.
As enterprises move to adopt new analytic applications built on Hadoop, Hadoop distributors need to make it as easy as possible for customers to develop the app, to provide choice in where to run it, and to feed it with as many data sources as possible. The partnership with Red Hat meets these three needs for Hortonworks.
The companies are considering building additional tools together in the future, including hooking into the JBoss data grid, Red Hat’s NoSQL data store; hooking into the JBoss business rules engine; and the OpenShift integration. Today, the integration points are a bit of a hodge-podge, with some bits available from Hortonworks and some from Red Hat, so there is the possibility that the companies would stitch the products more closely together at some point in time.
There’s also the possibility (although no representatives of Red Hat or Hortonworks would say this) that Red Hat might be interested at some point in potentially buying a company like Hortonworks. Obviously that’s not the announcement we’re seeing today, but it’s something to keep in the back of your mind as big data analytic applications become more mainstream and the Hadoop marketplace matures.
Related Items:
Shining a Light on Hadoop’s ‘Black Box’ Runtime
The Future of Hadoop Runs on Tez, Hortonworks Says
Reaping the Fruits of Hadoop Labor in 2014
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States