

February 4, 2014
Novel Storage Technique Speeds Big Data Processing
Between the data deluge and the proliferation of uber-connected devices, the amount of data that must be stored and processed has exploded to a mind-boggling degree. One commonly cited statistic from Google Chairman Eric Schmidt holds that every two days humankind creates as much information as it did from the dawn of civilization up until 2003.
![]() “Big data” technologies have evolved to get a handle on this information overload, but in order to be useful, the data must be stored in such a way that it is easily retrieved when needed. Until now, high-capacity, low-latency storage architectures have only been available on very high-end systems, but recently a group of MIT scientists have proposed an alternative approach, a novel high-performance storage architecture they call BlueDB (Blue Database Machine) that aims to accelerate the processing of very large datasets.
“Big data” technologies have evolved to get a handle on this information overload, but in order to be useful, the data must be stored in such a way that it is easily retrieved when needed. Until now, high-capacity, low-latency storage architectures have only been available on very high-end systems, but recently a group of MIT scientists have proposed an alternative approach, a novel high-performance storage architecture they call BlueDB (Blue Database Machine) that aims to accelerate the processing of very large datasets.
The researchers from MIT’s Department of Electrical Engineering and Computer Science have written about their work in a paper titled Scalable Multi-Access Flash Store for Big Data Analytics.
The team observes that for many big data applications, performance is limited by the transportation of large amount of data from hard disks to where it can be processed. In the past, the entire working set of a problem could be stored in a computer’s main memory, aka dynamic random access memory (DRAM), when performance needs dictated, but modern big data application sets are often too large to be cached in main memory, at least not in an affordable way. The workaround has been to store data on multiple hard disks on a number of machines across an Ethernet network, but this increases the distance the data must travel, which in turn increases the time it takes to access the information.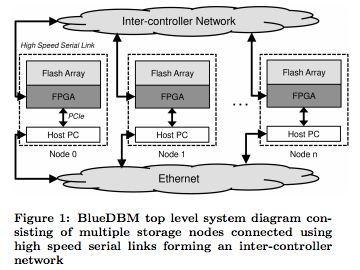
This concept is further explained by co-author Sang-Woo Jun, a graduate student in the Computer Science and Artificial Intelligence Laboratory (CSAIL) at MIT. “Storing data over a network is slow because there is a significant additional time delay in managing data access across multiple machines in both software and hardware,” he says. “And if the data does not fit in DRAM, you have to go to secondary storage — hard disks, possibly connected over a network — which is very slow indeed.”
The team developed a flash-based storage system for big data applications that aims to overcome these limitations by dramatically speeding access times. The approach is on track to enabling the same bandwidth and performance from a storage network as far more expensive machines.
Developing BlueDB was a two-step process. First, high-throughput was enabled by sharing large numbers of flash chips across a low-latency backplane. Second, each flash device was connected to a field-programmable gate array (FPGA) to create an individual node. The FPGAs not only control the flash device, they can also be used for local computation.
“This means we can do some processing close to where the data is [being stored], so we don’t always have to move all of the data to the machine to work on it,” Jun says.
Furthermore, the FPGA chips can be linked together using a high-performance serial network, which has a very low latency, such that information from any of the nodes can be accessed within a few nanoseconds.
“So if we connect all of our machines using this network, it means any node can access data from any other node with very little performance degradation, [and] it will feel as if the remote data were sitting here locally,” Jun says.
The researchers believe that the device holds the potential to boost the processing time on real-science workloads. They’re using data from a simulation of the universe generated by researchers at the University of Washington – it contains data on all the particles in the universe, across different points in time.
“If we’re fast enough, if we add the right number of nodes to give us enough bandwidth, we can analyze high-volume scientific data at around 30 frames per second, allowing us to answer user queries at very low latencies, making the system seem real-time,” he says. “That would give us an interactive database.”
A four-node prototype device based on the Xilinx ML605 board and a custom-built flash board achieved network bandwidth that scaled directly with the number of nodes. The average latency for user software to access flash storage was less than 70 microseconds, including 3.5 microseconds of overhead.
The researchers are now building a much faster 20-node prototype network with more modern flash boards and newer Xilinx boards, in which each node will operate at 3 gigabytes per second. The new system will be used to explore real-world big data problems.
The team will be demonstrating BlueDB in February at the International Symposium on Field-Programmable Gate Arrays in Monterey, California.
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States