

January 28, 2014
White-Glove Hadoop Cloud Service Launched by Altiscale
Hadoop users that need more handholding than Amazon can provide may want to check out the new Hadoop as a Service (HaaS) offering launched today by Altiscale. Founded by veteran technologists from Yahoo and AltaVista, the company intends to provide a high-touch experience for running and–more importantly–optimizing production Hadoop workloads in a private cloud.
Anecdotal evidence points to Amazon’s Elastic MapReduce (EMR) service becoming quite the hit among organizations that don’t want the hassle of owning and operating their own Hadoop cluster. Once you have your big data application coded, putting it up on EMR is ridiculously easy and much cheaper than provisioning your own cluster. These economic realities are leading other public cloud companies to find success with hosted Hadoop, too.
While there is no stopping the rise of Hadoop cloud environments, the folks at Altiscale want you to know that not all Hadoop cloud environments are created equal. When it comes to running production big data applications on hosted Hadoop environments, sometimes it’s the little things that matter most.
“The EMR product certainly does provide a certain ease of use above just going to Apache and downloading JAR files. So to that degree they offer some nice automation,” says Altiscale CEO Raymie Stata, the former CTO at Yahoo, an MIT Ph.D., and a veteran of hyperscale search applications going back to AltaVista.
“But at end of day, getting Hadoop up and running is just the beginning. Keeping the jobs running and keeping the jobs running well is the main part of the battle,” Stata continues “With Amazon in particular, you not only have to be a Hadoop expert, but an Amazon expert too. That’s especially true if you change instance types. There’s a lot of AWS complexities that are added on top of Hadoop complexities in that environment.”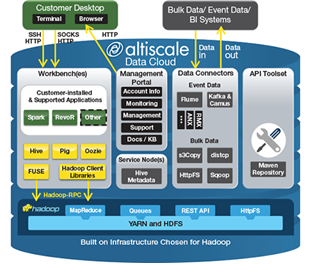
Today, Altiscale officially opened the doors to its private Hadoop environment, which is built on X86 servers from Supermicro, Arista switches, and the Apache Bigtop distribution of Hadoop. The San Francisco, California, company runs its own Hadoop cluster in a West Coast data center, and is expected to open a second data center on the East Coast before April.
Stata dubs it “Hadoop dial tone.” “It’s a purpose-built Hadoop cluster that is always on and at your fingertips. It just works,” he tells Datanami. “You just submit jobs, and as a user you don’t worry about ‘Do I have enough nodes? Do I have too many nodes? Do I have the right kind of nodes? Do I have the right number of disks on those nodes?’ We erased node thinking out of your mind. Just submit jobs, and if more capacity is needed, we take care of it.”
While an infinitely scalable Hadoop cluster may sound like something science fiction, that’s exactly what AltiScale is hoping to present to the user. In a way, it’s like gaining access to the Hadoop system at Yahoo or Google’s Hadoop-like BigFile system.
When Stata left Yahoo, where he had access to a “centrally run, super awesome Hadoop environment,” he found Hadoop environments on the outside to be less than compelling. “They looked subscale–tiny clusters, tiny teams, not able to make the investments in not only the infrastructure but the expertise you need to run Hadoop and run it well,” he says. “We saw an opportunity to create a company that can bring to the broader IT community the type of Hadoop environment, big data environment, that the large Internet companies enjoy. And that’s our mission.”
Out of Stealth, Into the Fire
The company has been in stealth mode for about two years and has about 10 customers running on its cluster. The environments run anywhere from 10 TB to hundreds of TB; one customer is close to a petabyte. Altiscale is catering to organizations that have already developed Hadoop applications–including MapReduce, Hive, Pig, Oozie, and Spark–and are now looking to scale them up in production.
 |
|
| Altiscale CEO Raymie Stata | |
While Hadoop clouds are quickly becoming a commodity, Altiscale is aiming to provide just a little bit more. Specifically, the company promises to work closely with clients to tune their Hadoop workloads and configure them so they run faster and take better advantage of the hardware underneath them.
Altiscale has the skills to help its clients, Stata says. “To keep Hadoop running well, you not only have to monitor Hadoop and its infrastructure, but you have to monitor the jobs as well,” he says. “One of the side effects of monitoring jobs is that you know how the jobs are going. You can often tell that a job is going to fail, often a couple hours before it does. When it comes through, you also understand it’s suboptimal and there’s ways to fix it.”
As part of its “proactive Hadoop help desk” service, the company will provide tuning tips. That is more than you will get from Amazon, which offers no personalized service for tuning EMR workloads. The company helps customers optimize their code, but they won’t do the coding–the data science–for them.
“We do provide architectural input,” Stata says. “If people are thinking Kafka versus Flume, Impala versus Stinger, or do I want to use Oozie–we also provide that very high-level architectural input. But when it comes to writing application code, we don’t do that.”
 |
|
| Altiscale claims its Hadoop service is much more efficient than Amazon’s EMR | |
Altiscale’s pricing is basically the same as Amazons, Stata says. Pricing starts at $750 per TB of data stored in HDFS. While the pricing is comparable, Stata argues that his customers can get a lot more done for the same dollar–not only because Altiscale’s infrastructure is faster, Stata says, but because of the optimizations it can provide.
“If it’s not jobs failing, it’s because people are using the wrong splits or wrong compression or using too many or too few files,” Stata says. “Once we get a job running on our infrastructure, [it’s amazing] how frequently we’ve been able to provide people with significant improvements that have nothing to do with the fact that we’re just simply faster.”
Stata’s co-founders include two other former Yahoo employees who were early Hadoop pioneers, including CTO David Chaiken, an MIT Ph.D. who was chief architect at Yahoo; and head of operations Charles Wimmer, who ran a 40,000-node Hadoop cluster at Yahoo.
Related Items:
When to Hadoop, and When Not To
Keeping Tabs on Amazon EMR Performance
Hitching a Big Data Ride on Amazon’s Cloud
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States