

January 9, 2014
Pivotal Helps NYSE with Multi-Petabyte Problem
Think you’ve got big data problems? Compare them to the New York Stock Exchange, which is required by law to maintain detailed transaction data for years. With multiple terabytes of data being added to the pool each day, the storage costs quickly became overwhelming. Thanks to a data management solution from Pivotal Software that the NYSE implemented three years ago, it has saved millions.
![]() In December 2013, Pivotal published a case study (written by Nucleus Research) describing the NYSE’s struggles with maintaining huge data sets. The story starts back in 2006, at the end of the stock market boom, when the NYSE first started feeling the weight of exponential growth in the volumes of equity trading transaction data that the SEC requires it to keep for seven years.
In December 2013, Pivotal published a case study (written by Nucleus Research) describing the NYSE’s struggles with maintaining huge data sets. The story starts back in 2006, at the end of the stock market boom, when the NYSE first started feeling the weight of exponential growth in the volumes of equity trading transaction data that the SEC requires it to keep for seven years.
The NYSE elected to build a massively parallel processing (MPP) platform to fulfill the SEC’s data storage requirements. Two vendors were chosen to provide the underlying storage hardware for this system, including IBM’s Netezza and EMC Greenplum.
When this project started, the cost per MPP storage was $22,000 per TB. The NYSE was adding 750GB of data per day to its federated data lake, meaning that it was spending around $16,000 per day just to store the day’s data. “It was extremely cost prohibitive for the NYSE to store just one year of data, and they were required to store seven,” the Nucleus case study says.
What’s more, the data analysts were having trouble getting access to access the data they needed. In some cases, requests had to go through DBAs, and could take up to three weeks to fulfill. Clearly the NYSE needed another solution.
In 2007, the exchange decided to create a new enterprise data architecture that relegated the active data to Netezza and Greenplum and build a “federated data lake” to house the older data. The idea was to store active and historical data in one place, and to allow the NYSE data analysts self-provision their information on demand.
By 2010, the NYSE was generating 2TB of transaction data per day. However, the daily costs of storing that data did not change, due to the falling price of storage. Just the same, the NYSE was spending $4.5 million per year just to store the data, according to the case study. Also, it did nothing to alleviate the pain associated with delivering that data to 250 analysts.
According to Steven Hirsch, Chief Data Officer of NYSE Euronext, that pain was becoming acute. “We needed to empower the data analyst and break them free from the old data request retrieval process,” Hirsh says in the Nucleus Research case study. “The need for large volumes of data and the speed of when you consume that data has changed dramatically, and we needed to change to remain competitive.”
In 2010, NYSE implemented EMC’s Data Dispatch (now Pivotal’s) solution to streamline access to the data lake, which the NYSE elected to keep as opposed to migrating to a traditional data warehousing platform.
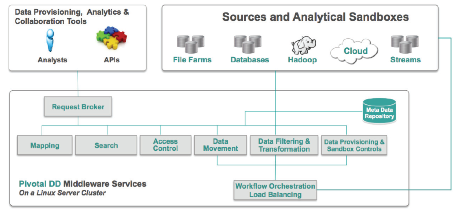 Data Dispatch is a Linux-based tool designed to allow analysts to “self provision” large data sets from multiple sources into sandboxes that it sets up for the analyst on a Hadoop or other MPP system. The software utilizes a metadata catalog that allows users to select and associate data using business-friendly terms (as opposed to using technical terms). An IT rules framework prevents users from accessing information they’re not supposed to touch, while a workflow tool lets analysts set up analytical workflows and complex data movements.
Data Dispatch is a Linux-based tool designed to allow analysts to “self provision” large data sets from multiple sources into sandboxes that it sets up for the analyst on a Hadoop or other MPP system. The software utilizes a metadata catalog that allows users to select and associate data using business-friendly terms (as opposed to using technical terms). An IT rules framework prevents users from accessing information they’re not supposed to touch, while a workflow tool lets analysts set up analytical workflows and complex data movements.
According to the case study, Data Dispatch “completely eliminated” the back and forth between the NYSE analysts and the IT department. Instead of waiting weeks for the IT department to furnish a given data set, Data Dispatch is delivering it within 30 to 60 minutes.
The ability to use the existing MPP platforms and the data lake, along with the savings in IT services, combined to save the NYSE an average of $7.7 million per year over the three years it has been using Pivotal Data Dispatch, Nucleus says in its case study. The payback time on the software, installation, and training was just three months.
Related Items:
Datanami Dishes on ‘Big Data’ Predictions for 2014
The 2013 Big Data Year in Review
Data Scientists–Who Needs Them Anyway?
Applications:
Enterprise Analytics
Technologies:
Middleware
Sectors:
Financial Services
Vendors:
Startups and More...
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States