

September 17, 2013
LinkedIn Open Sources Samza Stream Processor
LinkedIn has donated Samza, its lightweight, real-time stream processing framework, to the Apache Software Foundation, thereby putting a promising new Hadoop engine into the open source realm for anybody to use.
Samza is a Hadoop-based engine that provides stream processing of various types of messages, which could include clicks on a website, updates made to a particular database table, or any other type of event data generated on the Web. Developers can work with the Samza API within a Hadoop framework to generate layers of real-time jobs that process and react to message streams as they occur.
A Samza job takes two or more message input streams, performs some kind of logical transformation on them, and then generates its own output stream, according to the Samza webpage at Apache. The advantage of Samza is that it’s fault tolerant, maintains statefullness, and is able to continue working without a hiccup if a node in a cluster goes down.
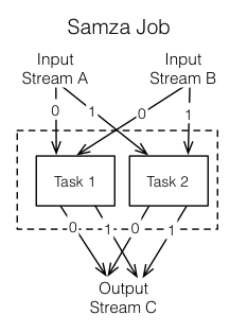
Samza works a lot like Storm, the Twitter-developed stream processing technology, except that Samza runs on Kafka, LinkedIn’s own messaging system. Storm also runs on YARN, the Hadoop processing framework, for fault tolerance, processor isolation, security, and resource management. Samza was developed with a pluggable architecture, enabling developers to use the software with other messaging systems, LinkedIn says.
The newly open source software has practical uses in social media, ecommerce, advertising, and fraud-detection. In social media and advertising, it could be used to count the number of page-views for each user per hour, or to do page ranking. The software could also be used to update a Web dashboard with this information.
In an ecommerce setting, Samza could be used to import feeds of merchandise from merchants, normalize them by product, and present products with all the associated merchants and pricing information, according to the Samza project page at Apache. The capability to capture user clicks can also be useful for detecting patterns that indicate possible fraud.
Samza provides a lightweight stream processing framework that addresses some difficult computer engineering problems, writes LinkedIn Staff Software Engineer Chris Riccomini in a Monday blog post.
“The expected time to get output from a stream process is usually much lower than batch processing, frequently in the sub-second range,” Riccomini writes. “Processors often accumulate a significant amount of state if they are aggregating events (counting events by member ID, for example), or trying to buffer or join streams over a window of time.

“Managing these demands in the face of machine failures is hard,” he continues. “Doing all of this at scale in a partitioned, distributed setting is even harder. Samza is a light weight framework that makes it easier for our engineers to process our real-time data feeds without having to worry about so many of these problems.”
LinkedIn decided to donate the software to the open source community (it’s currently an incubation project at Apache) as a result of the good experience it had with Kafka and Helix, LinkedIn’s previous donations to the ASF. Kafka was the key to LinkedIn’s transition to a real-time architecture for its data flows, and today is responsible for processing 26 billion unique messages per day to hundreds of message feeds, which eventually make their way into LinkedIn subscribers’ inboxes, according to Riccomini.
There are a few restrictions to using Samza in a production environment at this point. For starters, it depends on a snapshot version of Kafka that will not officially be released for a few months. As you can imagine, the version that is available for download from the Apache website is not the production version that LinkedIn uses. The Apache incubator project also hasn’t fully implemented its plans around fault-tolerance semantics.
Related Items:
LinkedIn Centralizing Data Plumbing with Kafka
Yahoo! Spinning Continuous Computing with YARN
Achieving Low Latency: The Fall and Rise of Storage Caching
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States