

September 16, 2013
SAP Brings Hadoop Closer to the Vest
ERP software giant SAP last week announced reseller agreements with two Hadoop distributors, Hortonworks and Intel. The move presents interesting possibilities for SAP and its customers, particularly as it relates to the big data future of SAP’s in-memory database platform, HANA.
The agreements that SAP has forged with Intel and Hortonworks are designed to lower the barrier of entry into Hadoop for SAP and its customer base of a quarter million organizations, which range from mid-size organizations to the largest Fortune 50 accounts.
SAP is selling the Hadoop distributions from Hortonworks and Intel, and providing level 1 and 2 technical support for the Hadoop distributions. This move is aimed at preventing SAP’s customers from worrying about whether SAP, Hortonworks, or Intel is responsible for fixing stuff when it breaks. That will be increasingly important, as Hadoop begins to reach its long, hairy trunk into the heart of ERP systems like SAP Business Suite, and fundamentally alter the landscape of enterprise technology.
SAP is also working with Intel and Hortonworks to simplify the roll-out and integration of Hadoop in HANA environments, and has even rolled out the first of several shrink-wrapped applications designed to run on top of HANA and Hadoop data sets.
The combination of HANA and Hadoop are certainly intriguing. The vendors would have us believe that the combination of the technologies will provide customers with fast access to “valuable insights” across the “continuum of data,” ranging from hot real-time data streams to warm transactional data to cold data archives.
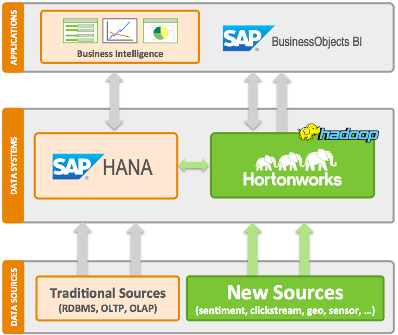 But all this begs the question: How do HANA and Hadoop actually work together? The two products are based on very different architectures. Hadoop is a batch-oriented system designed to store massive amounts of semi-structured data on clusters of commodity X86 servers loaded with petabyte’s worth of cheap spinning disks, whereas HANA is an in-memory database designed to be a single repository for a customer’s transactional (OLTP) and analytic (OLAP) data.
But all this begs the question: How do HANA and Hadoop actually work together? The two products are based on very different architectures. Hadoop is a batch-oriented system designed to store massive amounts of semi-structured data on clusters of commodity X86 servers loaded with petabyte’s worth of cheap spinning disks, whereas HANA is an in-memory database designed to be a single repository for a customer’s transactional (OLTP) and analytic (OLAP) data.
Nobody says that HANA and Hadoop have to run on the same system to give the customer value. In fact, such a system is a practical impossibility. But considering the investments that SAP, Intel, and Hortworworks are putting into the partnership, it’s worth understanding exactly how these two big data systems will work and relate to each other.
SAP provided Datanami with some answers to these questions. For starters, HANA and Hadoop will continue to be separate systems, but with “smart” new hooks that provide visibility from HANA into Hadoop, without requiring all the data to reside there, says Yuvaraj (“Yuva”) Raghuvir, a senior director in product management at SAP.
“We are not trying to take and stuff HANA with all the data that you can potentially use, and which might be huge but has very low value because a query hits it very rarely,” Raghuvir says. “Rather, we’re complementing HANA’s central capability of bringing information together across a variety of systems very fast, and combining it with these storage models…and looking at how you can start spreading over to infinite storage capabilities.”
In July, SAP started shipping a new feature in HANA SP6 that’s central to its capability to work with Hadoop. It’s called Smart Data Access, and it can do things like automatically generate Pig scripts and uses Hive and Sqoop to extract data from Hadoop. Another aspect of Smart Data Access is its data modeling capability, which enables users to build a virtualized and federated model of all of their data sources.
“Once this information is modeled,” Raghuvir says, “at the point when the query hits HANA, we can federate that query over to the nearby system [such as Hadoop], and extract only the information that’s relevant to the response.”
Byron Banks, SAP’s vice president of big data marketing, says it’s all about finding the right combination of structured data contained in the SAP ERP system and unstructured data, such as social media, click views, and sensor data. “We think Hadoop has a role to play. HANA certainly has a role to play. So why not bring it together so that, with one set of common tools, you can reach out into both of those environments?” he says.
SAP has started rolling out shrink-wrapped applications designed to run on the combination of Hadoop and HANA. The first application, called SAP Demand Signal Management, is designed to help manufactures capture and analyze large volumes of “downstream” demand signals, including retail point of sale (POS) data, consumer sentiment data, and market research data.
SAP has plans to deliver two additional shrink-wrapped Hadoop-HANA apps before the end of 2013, including the SAP Fraud Management analytic application and SAP Customer Engagement Intelligence solution. But SAP expects customers to build their own applications, and even has 100 Ph.D level data scientists ready to help.
Hortonworks presents several possible uses of a combined Hadoop-HANA system in a couple of recent publications, including “CIO Guide: How to Use Hadoop with Your SAP Software Landscape” and a reference architecture guide for Hadoop and SAP.
The most obvious is using Hadoop as a staging area for data that’s eventually loaded into HANA, or into its SybaseIQ database. A customer could also run MapReduce, TEZ, or other processing engines against the Hadoop data to whittle it down to the interesting bits. These bits are then loaded into HANA, mixed with the relational business data, and made available to the customer via SAP tools, such as BusinessObjects and Crystal Reports
With two-phase analytics, Hadoop can be used to run slower analytic processes, such as data mining, risk analysis, or OLAP fact table creation. The results of these processes are then loaded into HANA for faster analytic processing and delivery to the end user.
However, two-phase analytics are limited because users are restricted to running queries that have previously been run. When a user wants to really explore their Hadoop and HANA data stores, Hortonworks recommended using the federated query approach that’s available with Smart Data Access, which splits a query into separate components that hit the fast analytic capabilities of HANA (and SybaseIQ if necessary) and the slow analytic capabilities of Hadoop.
Related Items:
Analytics 3.0: A Blend of Big Data and Old Techniques
The Three T’s of Hadoop: An Enterprise Big Data Pattern
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States