

June 26, 2012
Virtualizing the Mighty Elephant
The adoption of virtual machines to power mission-critical environments has been increasing, as have use cases for the open source Hadoop framework.
 Recognizing this convergence, virtualization titan VMware is seizing on the opportunity to bring these two worlds closer together. This week the company announced an ambitious step towards virtualizing Hadoop with the release of their new open source project, Serengeti. The project will, according to the virtualization giant, enable enterprises to deploy, manage and scale Apache Hadoop in virtual and cloud environments.
Recognizing this convergence, virtualization titan VMware is seizing on the opportunity to bring these two worlds closer together. This week the company announced an ambitious step towards virtualizing Hadoop with the release of their new open source project, Serengeti. The project will, according to the virtualization giant, enable enterprises to deploy, manage and scale Apache Hadoop in virtual and cloud environments.
While the move might not come as a surprise since there have been rumblings about VMware’s Hadoop in the ether for some time, it does bring forth some big questions—not just about the flexibility, performance and reliability of Hadoop in general, but also about how these issues might be magnified when viewed with the multi-tenancy and latency and management lenses.
Richard McDougal, CTO for the Application Infrastructure group at VMware says that despite the valid concerns about these matters, there are a multitude of reasons why his team sought to virtualize the mighty elephant. For one thing, says McDougal, users can spin up an HA Hadoop cluster in a mere 10 minutes onto a vSphere farm using traditional shared storage or local storage. McDougal claims that Serengeti will also let users tap multiple distros and the more widely used components, including Pig, MapReduce and HDFS.
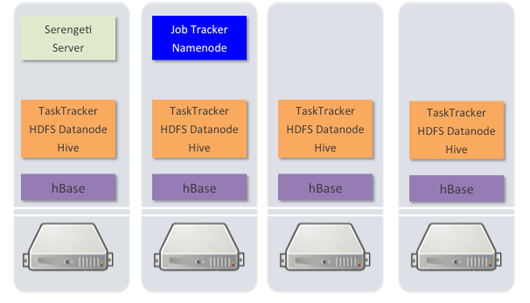
Reliability and availability are some of the more frequently-addressed problems users find with Hadoop, no matter what the distro. While Cloudera and MapR have both updated their platforms to expel the name node worries, this is nonetheless an issue many Hadoop-driven vendors are trying to solve.
Recognizing this, VMware gave their Serengeti news a twist by claiming that their vSphere tool will take care of reliability, protecting master nodes via monitoring and jumpstarting new virtual machines in the event of a planned or unplanned downtime.
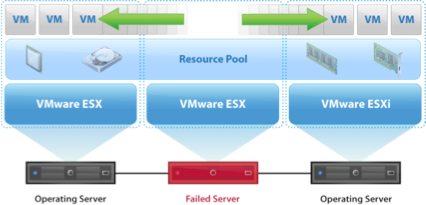
The other frequent Hadoop complaints, including general ease of use, from spinning up the cluster to running the first job, have also made it onto VMware’s radar. They say that Serengeti uses a template document to configure all the nodes – which means that users edit a document to specify the configuration of the cluster, then hand the thing over to Chef and the underlying templates to deploy each of the nodes.
But what if you are tapping a commercial distro instead of the real-deal open source package? McDougal says that wrangling that isn’t difficult with “addition via tarball” into the directory, which lets the user configure the distro manifest to point to the new addition.
This is the latest step in VMware’s recent expansion after partnering with Hortonworks and picking up start-up Cetas within the last month. However, partnering with the formidable virtualization entity that could prove equally useful to Hadoop. Yahoo and Facebook have been on board with Hadoop for years but they have the necessary resources to supply themselves with a multitude of Hadoop nodes. Smaller companies with big data aspirations might not. “Hadoop must become friendly with the technologies and practices of enterprise IT if it is to become a first-class citizen within enterprise IT infrastructure,” notes Ovum’s Principal Analyst Tony Baer. “The resource-intensive nature of large big data clusters make virtualization an important piece that Hadoop must accommodate.”
VMware says virtualization will make Hadoop more affordable and accessible to smaller enterprises. Without the need for multiple costly nodes (which can individually burn over $3000), Hadoop introduces itself to a larger client base. As Baer eloquently explains, analyzing big data requires significant resources. “Companies that are testing the platform and have less than 20 nodes or so… are ideal for virtualized distributions of Hadoop because it will not require large new capital expenses if Hadoop can run on legacy vShphere private clouds,” remarks Fausto Ibarra, VMware’s senior director of product management via Brandon Butler’s piece on Network World. These are the companies which suddenly have larger access to Hadoop and can provide Hadoop the resources it needs to achieve long-term stability.
Affordability aside, some say that the virtualized version of Hadoop would come with some unwanted performance overhead. To counter this, McDougal says that his team has done several “deep studies of Hadoop in a virtual environment, and this is an ongoing focus area for us with our Hadoop partners. Our results show that on average Hadoop performs within a few percent of that of a pure-physical environment.” He said that in some cases, the team saw slightly better performance due to better scaling because of the ability to partition the machine into several smaller nodes.
One Hadoop challenge VMware and Serengeti may help solve is that of its complexity. Baer says, “A lack of skilled workers to manage Hadoop clusters and interpret the data Hadoop creates is another challenge for curious enterprises.” If nothing else, VMware can at least apply its talent to conquer Hadoop’s intricacies.
If successful, Serengeti would be a major coup for VMware (to further entrench itself in the open source community), Hadoop (to make itself more accessible to smaller enterprises), and small businesses with sights on unlocking big data’s secrets.
Serengeti is available through free download under Apache 2.0 on VMware’s website and is a “one-click deployment toolkit that allows enterprises to leverage the VMware vSphere platform to deploy the Apache Hadoop cluster in minutes, including common components like Apache Pig and Apache Hive.”
Technologies:
Frameworks
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States