

May 8, 2012
How 8 Small Companies are Retooling Big Data
As the buzz continues to blow around big data tools, frameworks and concepts, news from smaller companies—especially those with unique approaches to the challenges of tackling massive enterprise data—is often lost.
 This week we wanted to point to a handful of standout companies that are edging out some of the big players in a number of industries, including government, financial services and massive-scale retail.
This week we wanted to point to a handful of standout companies that are edging out some of the big players in a number of industries, including government, financial services and massive-scale retail.
Following our list of the top eight (which by the way, are in no particular order since many of them bring their own piece to the big data puzzle) we included a handful of honorable mentions—companies that are blazing trails in their area of focus.
Without further delay, let’s begin with our first small company that is reshaping how enterprises are considering their big data problems:
Opera Solutions
The first time Opera Solutions garnered a significant amount of attention was back in 2009 when they won the analytics competition run by Netflix. From then on, the company grew quickly, scoring over $84 million in further funding and a bevy of new use cases.
 The analytics company is something of a jack-of-all trades when it comes to complex analytics on massive data sets. Their solutions explore the use of machine learning, web-scale analytics and massive-scale data management in diverse settings, including at investment firms, manufacturing centers, government and financial services.
The analytics company is something of a jack-of-all trades when it comes to complex analytics on massive data sets. Their solutions explore the use of machine learning, web-scale analytics and massive-scale data management in diverse settings, including at investment firms, manufacturing centers, government and financial services.
The company’s analytical capabilities are delivered in a cloud model.
The primary technologies are centered around its Vektor offering, which they describe as a “secure and flexible big data analytics platform that extracts powerful signals and insights from massive amounts of data flow, and then streams analytically enriched guidance and recommendations directly to the front lines of business operations.”
The company was founded in 2004 by CEO Arnab Gupta and continues to expand on its over 400-employee-strong base globally. Opera Solutions calls Jersey City home but has a presence in other worldwide cities, including New York, London, Paris, San Diego, Shanghai and New Delhi. The latter three offices are their R&D centers.
Next – In the New Data Warehouse >>>
The New Data Warehouse: 1010Data
While it might receive the press attention of other, much larger and more established data warehouse companies, 1010Data brings some notable use cases to the table in areas as diverse as big finance, insurance and retail.
 The company takes a “power to the people” approach with data warehousing with their cloud-based data warehouse/business intelligence platform. The 1010data warehouse enables analysts and programmers to work directly with data in its raw and truest form. Since the warehouse is cloud-based, it enables customers to work with their data in a way that is manageable and no longer the pure domain of gatekeepers.
The company takes a “power to the people” approach with data warehousing with their cloud-based data warehouse/business intelligence platform. The 1010data warehouse enables analysts and programmers to work directly with data in its raw and truest form. Since the warehouse is cloud-based, it enables customers to work with their data in a way that is manageable and no longer the pure domain of gatekeepers.
With the aim of “democratizing data” the company says that the chasm between people who need to get insight from data and the data itself has grown unchecked. This is, in part anyway, due to the among of time and effort required to set up the technical infrastructure to assemble, store and deliver data to users.
1010Data says they want to eliminate the gap between users—both end users and application developers—and the data. Data is made available almost immediately, with no up-front requirements and design phases. The user can be given access to raw data rather than summarized or processed data, and can do any analysis, even things that no one has ever considered before, in an intuitive way from anywhere.
The company claims that the key to their growth is that they combine data management and analysis technology with a rich and sophisticated array of built-in analytical functions and an intuitive spreadsheet interface that offers the fastest time to value.
NEXT — Bringing Hadoop Down to Earth
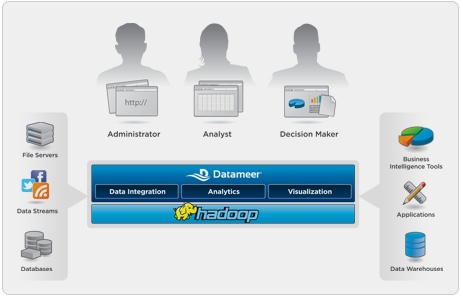
Datameer Brings Hadoop Down to Earth
Datameer’s emphasis on bringing Hadoop down to the level of the average data user is not unique in that other companies (continue through the list) are seeking to make Hadoop easy.
 This has been a popular approach across the Hadoop ecosystem as companies find themselves being told to look into using Hadoop, only find that there is significant complexity for untrained users.
This has been a popular approach across the Hadoop ecosystem as companies find themselves being told to look into using Hadoop, only find that there is significant complexity for untrained users.
The company says they are able to leverage the scalability, flexibility and cost-effectiveness of Apache Hadoop to deliver an end-user focused analytics solution for big data. Like other Hadoop-slinging startups that integrate the framework, analytical tools and visualization component, Datameer says they overcomes Hadoop’s complexity and lack of tools by providing business and IT users with BI functionality across data integration, analytics and data visualization in one analytics platform.
Datameer has some notable clients, including Visa, which is using the company for undisclosed BI functions. Other customers include Orange Labs and ZEvents.
According to Shawn Rogers,Vice President Research, Business Intelligence, Enterprise Management Associates, “Hadoop promises to become a ubiquitous framework for large scale business intelligence, but right now it is difficult for many developers to use.”Rogers says he sees tremendous value in Datameer’s approach – making Hadoop accessible to more users who need scalable analytic power for their organization’s big data requirements.”
NEXT — The Data Diaspora >>>
The Data Diaspora
If you ask the development team at San Francisco-based Dataspora what the next generation of predictive analytics applications will look like, chances are they’ll point well beyond mere prediction.
 It is the company’s view that prediction alone is not powerful enough—rather, changing the world based on action items that haven’t appeared on the radar yet is the real key.
It is the company’s view that prediction alone is not powerful enough—rather, changing the world based on action items that haven’t appeared on the radar yet is the real key.
The small company leverages both proprietary and open-source tools to extract knowledge from high dimensional data sets. Rather than simply observing patterns and making predictions about the world around us, they claim to “take business intelligence to the next level by learning what to do in order to change the world around us in the manner we desire.”
At the heart of their approach are machine learning tools and technologies that they say allow users to create causal network models to solve the toughest “big data” challenges. These network models capture causal relationships, not just correlations, from massive data sets.
Learning causal models directly from observational data enables one to ask “what-if” questions about specific business scenarios. For example, there might be a mere prediction that customer X is likely to leave a service provider. Again, that’s not enough—they say users need tools that allow them to answer the more difficult question of which product offer is most likely to cause customer X to stay with the entity.
As the company states, “Predictive analytics will only be as valuable as the actionable insights that your organization can glean from the results.”
While they might not provide much in the way of customer use case information, Dataspora maintains one of the most expertly-maintained blogs in the big data/small company space.
NEXT — Easing into the Platform >>>
Platfora and the Hadoop Curve…
San Mateo-based Platfora raked in a Series A round of $7.2 million recently to further its foray into enterprise big data.
 At the core of Platfora’s approach is a combination of what they call “server technology, user experience innovation, and data science.” The company’s platform works with existing Hadoop clusters (Cloudera, MapR, Amazon EMR, etc.), and automatically turns the questions of business users into Hadoop jobs that synthesize and distill Hadoop datasets into dimensional and predictive dashboards, reports and insights.
At the core of Platfora’s approach is a combination of what they call “server technology, user experience innovation, and data science.” The company’s platform works with existing Hadoop clusters (Cloudera, MapR, Amazon EMR, etc.), and automatically turns the questions of business users into Hadoop jobs that synthesize and distill Hadoop datasets into dimensional and predictive dashboards, reports and insights.
The system intelligently drives Hadoop to create and maintain ‘work products’ — highly compressed partial results that are refined at the click of a button to achieve subsecond report delivery, analytics overlay, and drilldown performance.
Platfora’s focus in on our platform is one seeing past traditional data warehouses, ETL tools and the legacy BI products of the past. However, while they admit that Hadoop is their emphasis, as a raw tool for reshaping enterprise big data, it is not enough.
The company makes the argument that even though Hadoop has been touted as the cure-all for big data woes, it is low-level infrastructure that has similarities to batch-processing system from the 1960s. Platfora leaders argue that “Everything takes minutes to hours to run, and jobs need to be carefully submitted by experts. It isn’t interactive like a traditional database, so just layering a BI product on top is asking for disappointment. Interactive reporting for business users simply doesn’t exist for Hadoop.”
“Businesses are increasingly looking to Hadoop, rather than traditional databases, to store their fast-growing datasets,” said Ben Werther, founder and CEO of Platfora. “We transform Hadoop from promising back-end technology into an effortless, interactive and beautiful way for business users to get rapid insight and answers from any sized dataset, even those with petabytes of information.”
Next — ParAccel Finds Big Name Successes >>>
ParAccel Finds Big Name Successes
When it comes to analytical platforms from smaller companies, ParAccel has been able to stand out from the crowd enough to attract big name companies, including the Department of Defense, Goldman Sachs, OfficeMax, Home Depot and several others.
 At the core of ParAccel’s platform is a high performance analytic database, designed specifically for the fastest query performance at any scale. The massively parallel, columnar, compressed, compiled approach is what drives performance and attracted some of their household name customers.
At the core of ParAccel’s platform is a high performance analytic database, designed specifically for the fastest query performance at any scale. The massively parallel, columnar, compressed, compiled approach is what drives performance and attracted some of their household name customers.
According to ParAccel, “the built-in algorithms, in database analytics, load capacity and sheer processing power are unmatched in the industry. While the video below is really pitching the platform, it is nonetheless revealing in terms of the company’s integrated approach to analytics at scale.
ParAccel has wrapped the massively parallel database with an extensibility framework that embeds 502 analytic functions and supports the on-demand integration of a variety of structured and unstructured data and analytic results, right at the point of execution.
The Campbell, California-based company just raised $20 million and hit record revenue numbers. “We are off to a great start for 2012, as Q1 was the largest quarter in the history of the company,” said Chuck Berger, chairman and CEO for ParAccel in a prepared statement. “The confidence demonstrated by our core investors doubling down on ParAccel underscores the momentum we’re experiencing with customers and the sharp uptick in market demand for ways to harness big data to develop new business insights.”
NEXT — The Next Gen for Data >>>
NextGen Enteprise: 10Gen
10Gen calls itself the “initiator, contributor and continual sponsor of the open source, non-relational database MongoDB. The company’s handiwork can be found as the underlying data handling framework at large entities, including Foursquare.
 MongoDB is being used in a number of applications that have stressed the traditional relational database. According to the company, the reason many look to MongoDB is because it offers them a more flexible schema model, a solid query language, and scale-out approach.
MongoDB is being used in a number of applications that have stressed the traditional relational database. According to the company, the reason many look to MongoDB is because it offers them a more flexible schema model, a solid query language, and scale-out approach.
Among other areas, 10Gen and MongoDB are being used to address big data areas like operational intelligence (for real-time reporting and feedback systems), meta-data-rooted enterprise content management, product data management and high volume data feeds.
The company’s director of product strategy briefly lays the groundwork for the multitude of differences something like MongoDB has in the era of big data, especially when compared to SQL.
10Gen says that when it comes to high-volume data feeds, ingesting large streams of data such as server logs, telemetry data, stock market data, or social media status updates requiers a storage layer that’s capable of keeping up with a high volume of writes. Their point of real difference—the MongoDB’s scale-out architecture that hones in on write performance make it better than some standard legacy approaches to storing and processing large volume data feeds.
Next — Managing Real-Time Big Data >>>
GridGain and Real-Time Data
GridGain develops software for companies including Apple, Sony, Digital Mountain and others who see real time big data as a strategic asset and who need live data business analytics and processing.
 The company’s flagship item is a Java-based open source in-memory platform that provides integration between in-memory data and compute grid technologies and can scale up from a single server to thousands of machines.
The company’s flagship item is a Java-based open source in-memory platform that provides integration between in-memory data and compute grid technologies and can scale up from a single server to thousands of machines.
As GridGain leaders say, “Unlike complex, decade-old ETL systems which use dead data for batch offline analytics, our platform allows companies to harness live data for smarter, faster real time processing and analysis.”
GridGain clusters typically reside between business applications and long-term storage or data warehouses such as SQL, ERP or Hadoop HDFS and provides in-memory platform for high performance, low latency processing of the data.
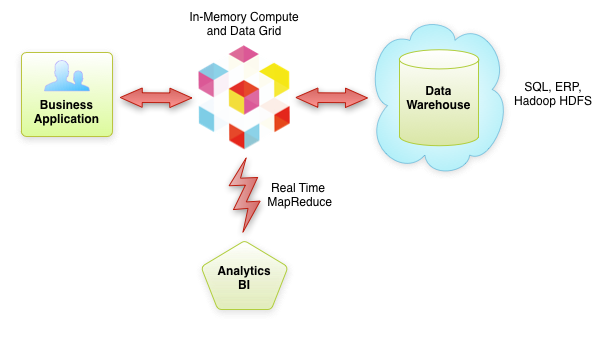
The cluster often holds an ‘operational subset’ of data that it currently needs to operate on in-memory. GridGain points to is “intelligent caching” technology as being pivotal here since it only clings to the necessary data in memory while automatically pushing the other data in a long-term storage or data warehouse.
In addition to the Fortune 500 customers under GridGain’s view, the company also has a significant foothold in higher education and within research institutions.
Last — Honorable Mentions >>>
Big Data’s Honorable Mentions….
Since we can’t go on indefinitely with details about every company we’re keeping an eye on as we wind into summer 2012, we do want to address a few other notable companies that are on the radar.
These include:
 Zettaset
Zettaset
Big data management company Zettaset is another in the list of platforms seeking to remove Hadoop-related complexity. The company works with all major distributions and provides everything from management, automation, analytics and security.
 NGDATA
NGDATA
Belgium-based NGDATA NGDATA brings big data technology and machine intelligence together, allowing organizations to capitalize on the massive amounts of data that is generated today. The company develops Lily, a data management system that lets users extract insights from their data in real time, to make an immediate impact on and improve business performance.
 SumoLogic
SumoLogic
SumoLogic turns raw, big data logs into new sources of operations, security and compliance intelligence.
Starting with log data users can pinpoint operational efficiencies, find a stronger security posture and more streamlined compliance with regulatory mandates by providing real-time actionable insights from raw machine data.
 Cloudant
Cloudant
Cloudant was in 2008 by three MIT physicist who were frustrated by the lack of tools to manage and analyze big data. Driven forth by the goal to create new solutions, the founders built a distributed, fault-tolerant, globally scalable data layer for applications, a platform that would free developers to focus on their applications knowing that they would never outgrow their data layer.
 Kognito
Kognito
Kognito seeks to provide a scalable and most affordable analytical platform that taps in-memory analytical capabilities to access and query data. As one of several startups targeting enterprise big data as a service (via the cloud) the company is leveraging new partnerships, including a recent one with Hortonworks.
Vendors:
Startups and More...
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States