

November 30, 2015
Spark Streaming: What Is It and Who’s Using It?

A recent study of over 1,400 Spark users conducted by Databricks, the company founded by the creators of Spark, showed that compared to 2014, 56 percent more Spark users globally ran Spark Streaming applications in 2015. Additionally, 48 percent of survey respondents noted Spark Streaming as their most-used Spark component.
Spark Streaming’s ever-growing user base consists of household names like Uber, Netflix, and Pinterest. This article explores why and how hundreds of companies are leveraging Spark Streaming to accelerate their business requirements.
The Need for Streaming Analytics
The common saying, “every company is now a software company” equates to companies collecting more data than ever and wanting to get value from that data in real-time. Sensors, IoT devices, social networks, and online transactions are all generating data that needs to be monitored constantly and acted upon quickly. As a result, the need for large scale, real-time stream processing is more evident than ever before.
For example, making a purchase online means that all the associated data (e.g. date, time, items, price) need to be stored and made ready for organizations to analyze and make prompt decisions based on the customer’s behavior. Similarly, detecting fraudulent bank transactions is another application that requires testing transactions against pre-trained fraud models as the transactions occur (i.e. as data streams) to quickly stop fraud in its tracks.
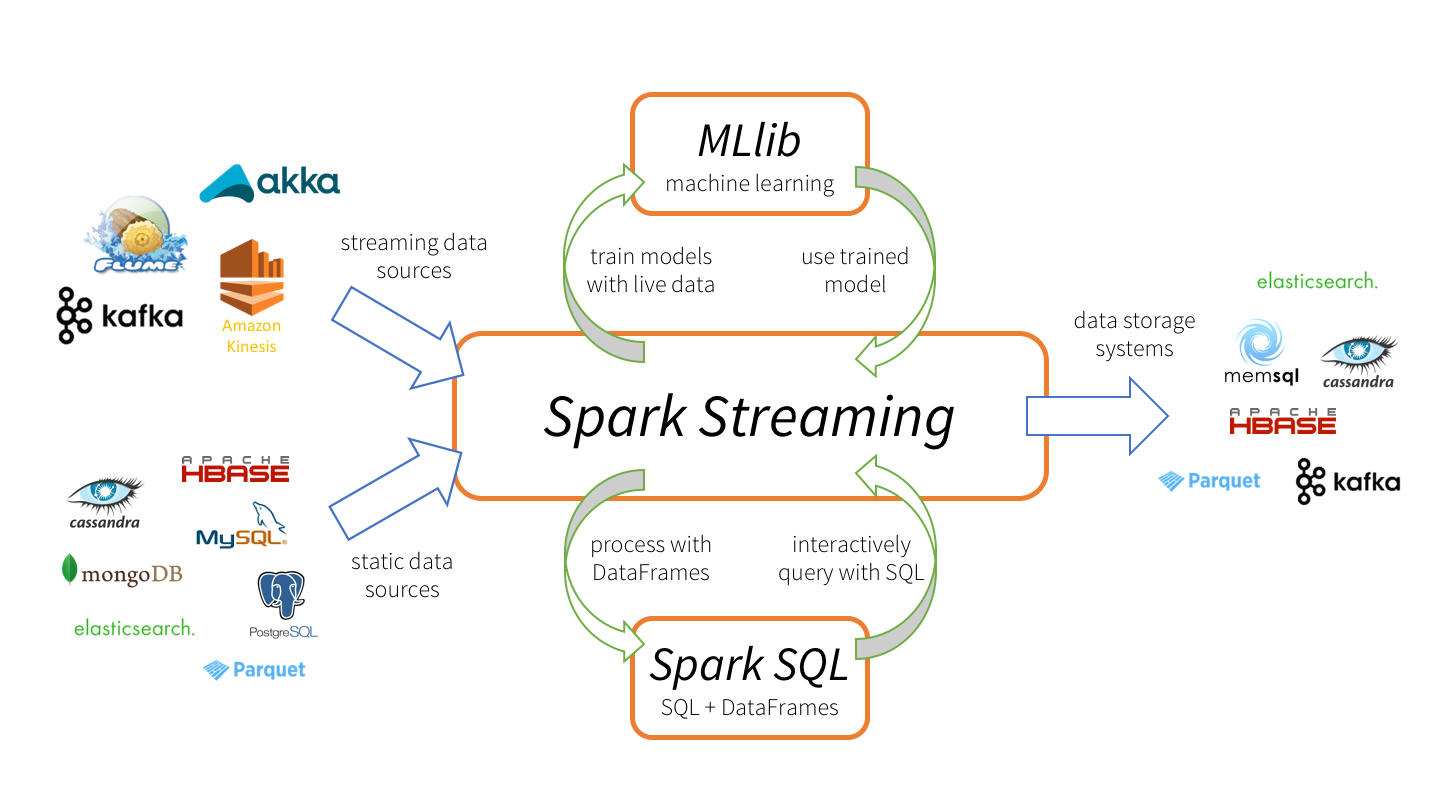
Spark Streaming ecosystem: Spark Streaming can consume static and streaming data from various sources, process data using Spark SQL and DataFrames, apply machine learning techniques from MLlib, and finally push out results to external data storage systems.
That same streaming data is likely collected and used in batch jobs when generating daily reports and updating models. This means that a modern stream processing pipeline needs to be built, taking into account not just the real-time aspect, but also the associated pre-processing and post-processing aspects (e.g. model building).
Before Spark Streaming, building complex pipelines that encompass streaming, batch, or even machine learning capabilities with open source software meant dealing with multiple frameworks, each built for a niche purpose, such as Storm for real-time actions, Hadoop MapReduce for batch processing, etc.
Besides the pain of developing with disparate programming models, there was a huge cost of managing multiple frameworks in production. Spark and Spark Streaming, with its unified programming model and processing engine, makes all of this very simple.
Why Spark Streaming is Being Adopted Rapidly
Spark Streaming was added to Apache Spark in 2013, an extension of the core Spark API that allows data engineers and data scientists to process real-time data from various sources like Kafka, Flume, and Amazon Kinesis. Its key abstraction is a Discretized Stream or, in short, a DStream, which represents a stream of data divided into small batches. DStreams are built on RDDs, Spark’s core data abstraction. This allows Spark Streaming to seamlessly integrate with any other Spark components like MLlib and Spark SQL.
This unification of disparate data processing capabilities is the key reason behind Spark Streaming’s rapid adoption. It makes it very easy for developers to use a single framework to satisfy all the processing needs. They can use MLlib (Spark’s machine learning library) to train models offline and directly  use them online for scoring live data in Spark Streaming. In fact, some models perform continuous, online learning, and scoring. Furthermore, data from streaming sources can be combined with a very large range of static data sources available through Spark SQL. For example, static data from Amazon Redshift can be loaded in memory in Spark and used to enrich the streaming data before pushing to downstream systems.
use them online for scoring live data in Spark Streaming. In fact, some models perform continuous, online learning, and scoring. Furthermore, data from streaming sources can be combined with a very large range of static data sources available through Spark SQL. For example, static data from Amazon Redshift can be loaded in memory in Spark and used to enrich the streaming data before pushing to downstream systems.
Last but not least, all the data collected can be later post-processed for report generation or queried interactively for ad-hoc analysis using Spark. The code and business logic can be shared and reused between streaming, batch, and interactive processing pipelines. In short, developers and system administrators can spend less time learning, implementing, and maintaining different frameworks, and focus on developing smarter applications.
Streaming Use Cases – From Uber to Pinterest
While each business puts Spark Streaming into action in different ways, depending on their overall objectives and business case, there are four broad ways Spark Streaming is being used today.![]()
- Streaming ETL – Data is continuously cleaned and aggregated before being pushed into data stores.
- Triggers – Anomalous behavior is detected in real-time and further downstream actions are triggered accordingly. E.g. unusual behavior of sensor devices generating actions.
- Data enrichment – Live data is enriched with more information by joining it with a static dataset allowing for a more complete real-time analysis.
- Complex sessions and continuous learning – Events related to a live session (e.g. user activity after logging into a website or application) are grouped together and analyzed. In some cases, the session information is used to continuously update machine learning models.
In looking at use cases, Uber, for example, collects terabytes of event data every day from their mobile users for real-time telemetry analytics. By building a continuous ETL pipeline using Kafka, Spark Streaming, and HDFS, Uber can convert the raw unstructured event data into structured data as it is collected, making it ready for further complex analytics. Similarly, Pinterest built an ETL data pipeline starting with Kafka, which feeds that data into Spark via Spark Streaming to provide immediate insight into how users are engaging with Pins across the globe in real-time. This helps Pinterest become a better recommendation engine for showing related Pins as people use the service to plan products to buy, places to go, and recipes to cook, and more. Similarly, Netflix receives billions of events per day from various sources, and they have used Kafka and Spark Streaming to build a real-time engine that provide movie recommendations to its users.
The spike in Spark Streaming deployments in 2015 is just the tip of the iceberg to what we perceive to be an increasingly common trend. With the ability to react and make prompt decisions based on real-time processing, more businesses are beginning to expand beyond batch-processing methods to build new data products using Spark Streaming. We can expect the adoption of Spark Streaming to continue its rapid increase as more and more businesses learn, understand, and take advantage of the simplicity and real-time analysis that it helps provides.

About the author: Tathagata Das is a committer and member of the project management committee (PMC) to the Apache Spark project and lead developer of Spark Streaming. Das is currently employed by Databricks, and in the past has spent time at the AMPLab and at Microsoft Research India.
Related Items:
Skip the Ph.D and Learn Spark, Data Science Salary Survey Says
How Uber Uses Spark and Hadoop to Optimize Customer Experience
Apache Spark: 3 Real-World Use Cases
(feature image courtesy Anteromite/Shutterstock.com)
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States