

October 5, 2015
How Uber Uses Spark and Hadoop to Optimize Customer Experience
If you’ve ever used Uber, you’re aware of how ridiculously simple the process is. You press a button, a car shows up, you go for a ride, and you press another button to pay the driver. But there’s a lot more going on behind the scene, and much of that infrastructure increasingly runs on Hadoop and Spark, as the Uber data team recently shared.
Uber has the envious position of sitting at the junction of the digital and physical worlds. It commands an army of more than 100,000 drivers who are tasked with moving people and their stuff within a city or a town. That’s a relatively simple problem. But as Uber’s Head of Data Aaron Schildkrout recently said, that simplicity of its business plan gives Uber a huge opportunity to use data to essentially perfect its processes.
“It’s fundamentally a data problem,” Schildkrout says in a recording of a talk that Uber did with Databricks recently. “Because it is so simple, we sort of get to the essence of what it means to automate an experience like this. In a sense we’re trying to bring intelligence, in an automated and basically real time way, to cars that all over the globe right now that are carrying people around, to make that happen at this tremendous scale.”
Whether it’s calculating Uber’s “surge pricing,” helping drivers to avoid accidents, or finding the optimal positioning of cars to maximize profits, data is central to what Uber does. “All these data problems…are really crystalized on this one math with people all over the world trying to get where they want to go,” he says. “That’s made data extremely exciting here, it’s made engaging with Spark extremely exciting.”
Big Data at Uber
In the Databricks talk, Uber engineers described (apparently for the first time in public) some of the challenges the company has faced in getting its back-office applications to scale, and what it’s done to meet that demand.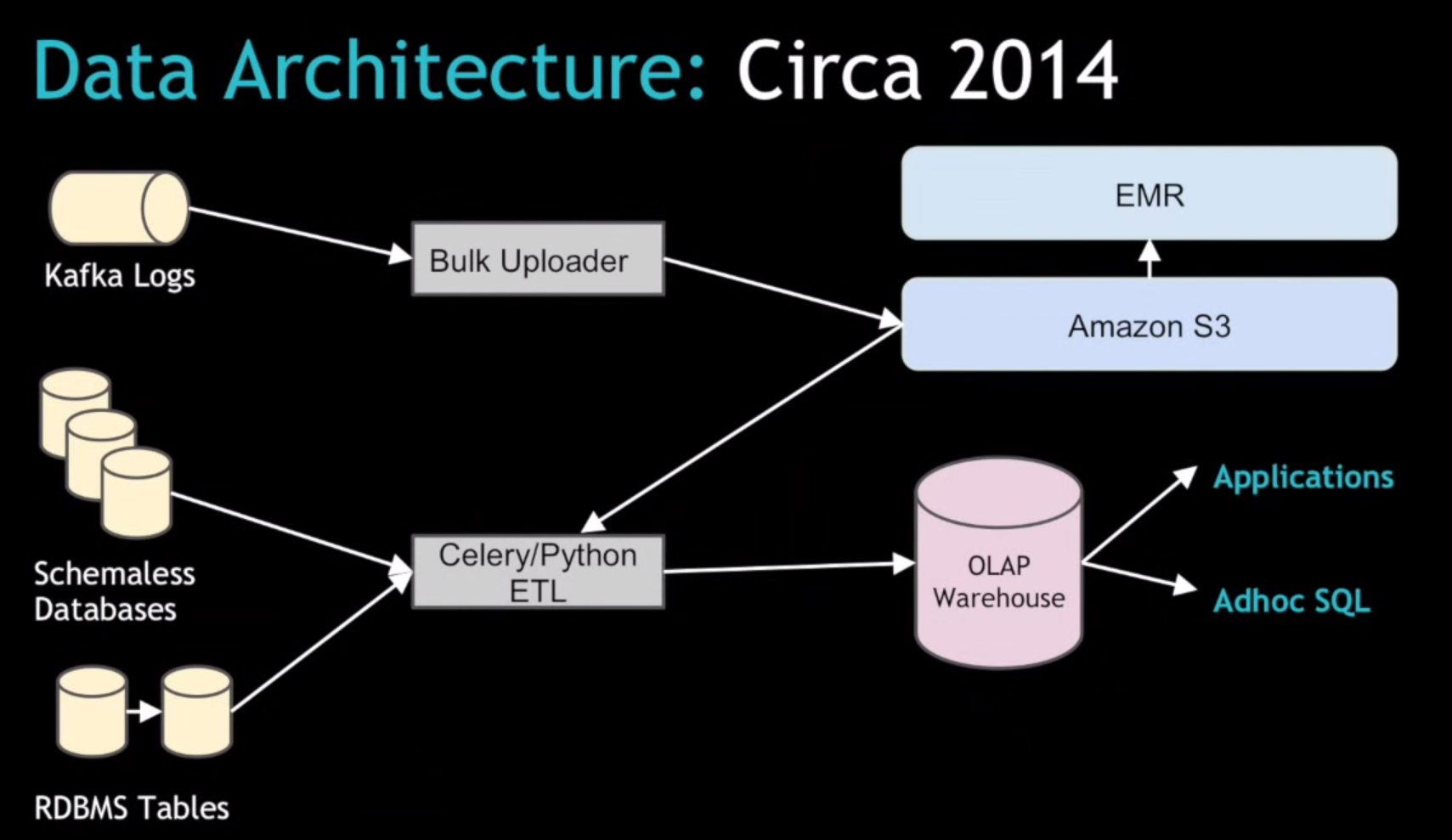
Spark has been “instrumental in where we’ve gotten to,” says Vinoth Chandar, who’s in charge of building and scaling Uber’s data systems. Under the old system, Uber relied on Kafka data feeds to bulk-load log data into Amazon S3, and used EMR to process that data. It then moved the “gold-plated” output from EMR into its relational warehouse, which is accessed by internal users and the city-level directors leading Uber’s expansion around the world.
The Celery/Python-based ETL system the company built to load the data warehouse “worked pretty well,” but then Uber ran into scale issues, Chandar said. “As we add more cities…as the scale increased, we hit a bunch of problems in existing systems,” particularly around the batch-oriented upload of data.
In particular, Uber needs to ensure that the “trips” data–one of its most important data sets, which documents the hundreds of thousands of actual car rides that Uber drivers give each day and is critical for accurately paying drivers—is ready to be consumed by downstream users and applications. “This system we had wasn’t built for multiple data centers,” Chandar said. “We need to get them all into a single data center in sort of a merged view.”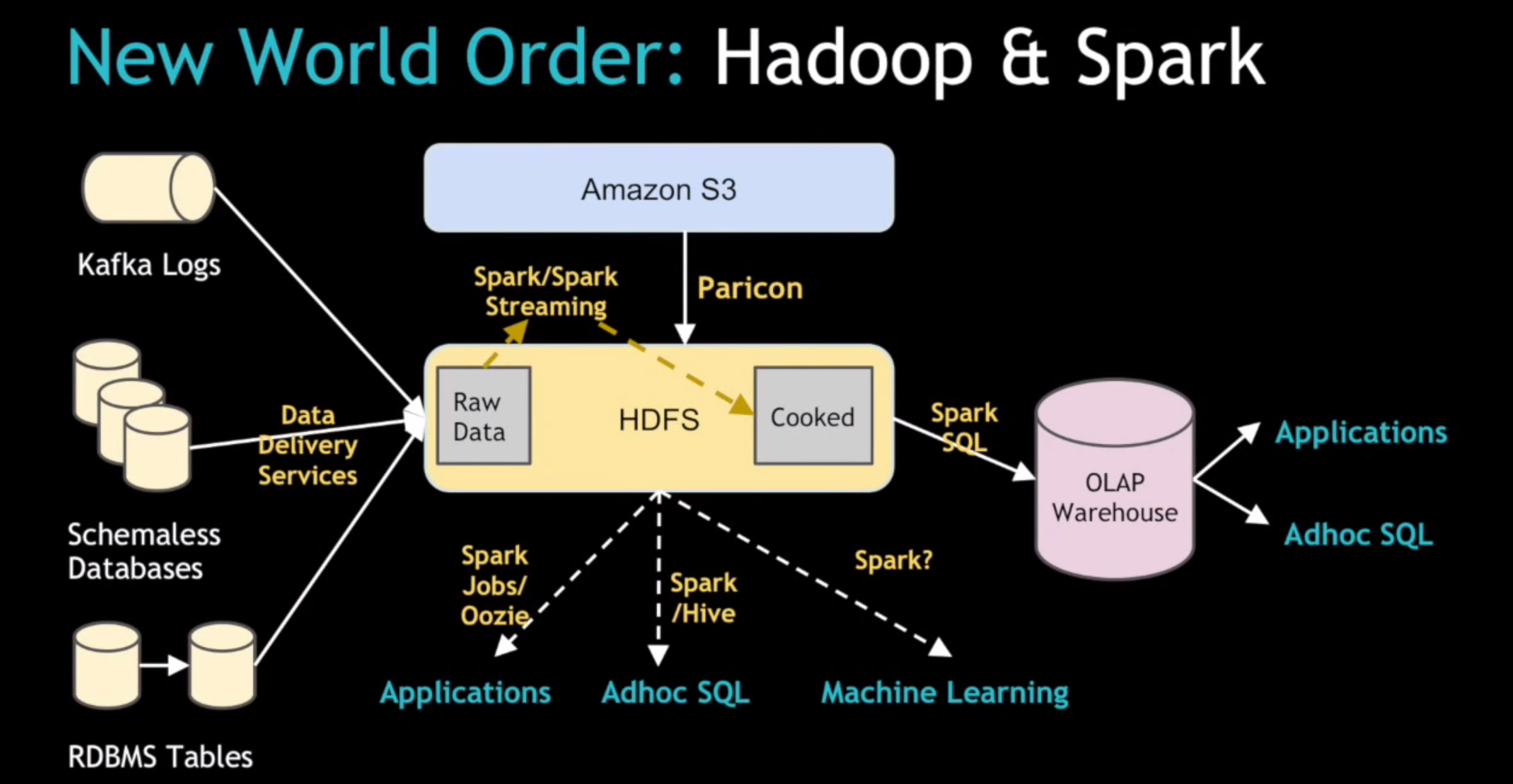
The solution involved a new Spark-based system called streamIO that replaced the Celery/Python ETL system. The new system essentially decouples the raw data ingest from the relational data warehouse table model, Chandar said. “You want to get raw data onto HDFS and then later rely on something like Spark that can do very large scale processing to figure out the transformations later on,” he added.
So instead of trying to aggregate the trip data from multiple distributed data centers in a relational model, the company’s new system uses Kafka to stream change-data logs from the local data centers, and loads them into the centralized Hadoop cluster. The system then uses Spark SQL to convert the schema-less JSON data into more structured Parquet files, which form the basis for SQL-powered analysis done using Hive.
“This solved a bunch of additional problem we had and we’re now at a point with basics in place [where] we’re trying to get more into a solid, longer-term ingestion system using Spark and Spark Streaming,” he said. “We also plan to open access to raw data and ingest the data, with Spark jobs and Hive and machine learning and all the fun stuff that can be unlocked with Spark.”
Paricon and Komondor
After Chandar gave an overview of Uber’s adventure into Spark, two Uber engineer, Kelvin Chu and Reza Shiftehfar, provided more details on Paricon and Komondor, two Spark projects at the heart of Uber’s foray into Spark.
While schema-less data can be easier to handle, Uber eventually likes to use schema within its data pipeline because it forms a sort of “contract” between the producers and the consumers of data within the company, and helps to avoid “data breakage.”
This is where Paricon comes into picture, Chu says. The tool consists of four Spark-based jobs: transfer, infer, convert, and validate. “So whenever someone wants to change a schema, they will go to our system and use our tool to change it,” Chu said. “Then our system will run multiple checks and tests to make the change sure it doesn’t break anything.”

Aaron Schildkrout, Head of Data at Uber
One of the nice features of Paricon is something called “column-pruning.” “We have a lot of columns–we have a wide table [database]–but usually we don’t use all of them, so pruning can save a lot of I/O for those jobs,” he said. Paricon also handles some of the “data stitching” duties. Some of Uber’s data files are big, but many are far smaller than the HDFS block size, so the company stitches the data together to better align the file size to HDFS and prevent the I/O from getting out of whack. And Spark’s “schema merging” functionality also helps to keep Uber data on the straight and narrow with its Paricon workflow tool, he added.
Meanwhile, Shiftehfar provided architectural details into Komondor, the Spark Streaming-built ingestion service that essentially “cooks” the raw, unstructured data that’s loaded from Kafka streams into HDFS and prepares it for consumption by downstream applications.
Before Komondor, it was up to individual applications to make sure they were getting the right data (including picking up their processing where they left off previous) and de-duplicating the data if needed. Now that’s handled more or less automatically by the Komondor system. If customers need to reload data, the use of Spark Streaming in the software makes it relatively easy.
The company is investing heavily in Spark to help it process millions of events and requests per day, and is looking to leverage more of the Spark stack, including the MLlib and GraphX libraries for machine learning and graph analytics. For more information, you can view the entire presentation below.
Related Items:
Cutting: Spark an ‘All-Around Win’ for Hadoop
Spark Is the Future of Hadoop, Cloudera Says
Apache Spark Continues to Spread Beyond Hadoop
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States