

June 25, 2014
Google Re-Imagines MapReduce, Launches DataFlow
It’s well known in the industry that more than 10 years ago Google invented MapReduce, the technology at the heart of first-generation Hadoop. It’s less well known that Google moved away from MapReduce several years ago. Today at its Google I/O 2014 conference, the Web giant unveiled a possible successor to MapReduce called Dataflow, which it’s selling through its hosted cloud service.
Google Cloud Dataflow is a managed service for creating data pipelines that ingest, transform, and analyze massive amounts of data, up into the exabyte range. The same work done in the Dataflow SDK can be used for either batch or streaming analytics, Google says. Dataflow is based internal Google technologies like Flume and MillWheel, and can be thought of as a successor to MapReduce that’s especially well-suited for massive ETL jobs.
Urs Hölzle, Google’s senior vice president of technical infrastructure and a Google Fellow, described Dataflow during a keynote address at today’s Google I/O conference in San Francisco.
“We’ve done analytics at scale for a while and we’ve learned a few things. For one we don’t really use MapReduce anymore. It’s great for simple jobs but it gets too cumbersome as you build pipelines, and really everything is an analytics pipeline these days,” Hölzle says.
“So what we needed was a new analytic system that scales to exabytes and makes it really easy to write pipelines, that optimizes these pipelines for you and that lets you use the same code for both batch and streaming analytics. Today we’re annoying just that with Cloud Dataflow.”
The new service lets developers construct an analytics workflow and then send it off to the Google Cloud for execution. “Cloud Dataflow is an SDK and a managed service for building big and fast parallelized data analysis pipelines,” Google engineer Eric Schmidt (not the CEO) said during a demo. “You write a program; there’s a logical set of data transformations to specify your analysis. You then submit the pipeline to the data flow service, and it handles all optimization deployment of VMs, scheduling, and monitoring for you.”
What’s more, the parallelization is optimized for the developer, who doesn’t have to worry about the whole analytics process as much as they would using MapReduce. “Dataflow provides powerful built-in primitives for doing MapRedue-like and continual computation operations,” Schmidt says. “It handles all the aging out of data, shuffling etc. I don’t have to worry about that.”
During the demo, Schmidt showed an application that analyzed the sentiment of soccer fans during World Cup matches, expressed via Twitter. Here’s how it works: Dataflow grabs the tweets, converts the JSON into objects, calls Google Translate if it’s not in English, and then scores the sentiment expressed in those words by calling AlchemyAPI. (By the way, in addition to extracting entities from language, AlchemyAPI has done some fascinating work with image classification using GPUs; check out our write-up on the company from May).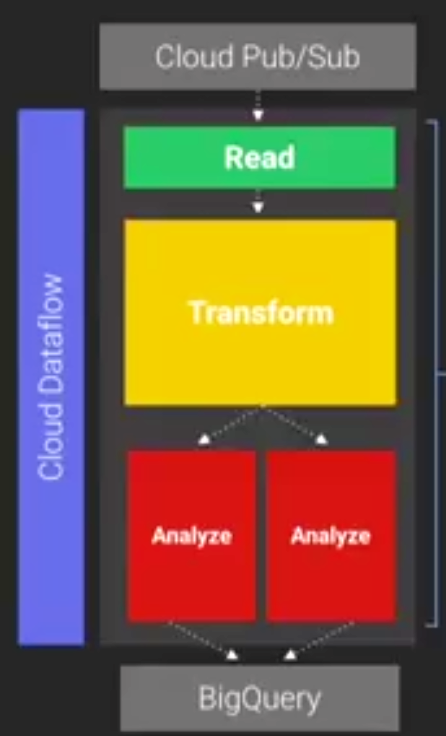
“Two lines of code to create sliding windows and average all the tweets over that window,” Schmidt says. “We’re reducing a massive collection of data down to one record per minute per team.”
Google isn’t in the software business per se, so you can’t go out and buy the software for your Hadoop cluster. You can, however, move your analytics to the cloud. In fact, if you want to get your hands on Dataflow, that is what you’ll have to do.
A lot has changed since Google created MapReduce a decade ago to help solve its data classification problem for Web search. Twitter and Facebook weren’t even invented yet. Much of the big data sets that organizations like Google want to analyze now come from social media, and developers are moving quickly to come up with alternatives to MapReduce.
“Information’s is being generated at an incredible rate and of course we want you to be able to analyze that information without worrying about scalability,” Hölzle says. “And today even when using MapReduce, which we invented over a decade ago, it’s still cumbersome to write and maintain analytics pipelines. And if you want streaming analytics, you’re out of luck. And if most instance, once you have more than a few petabytes, they kid of break down….I hope you understand now why we stopped using MapReduce years ago.”
One technology that’s emerged as a potential alternative to MapReduce is Apache Spark, which touts the same sort of interactive and real-time analytic capabilities as DataFlow, but from an open source API, as opposed to a proprietary API like Google’s. The 2014 Spark Summit starts Monday at the St. Francis Hotel in San Francisco. But today it was Google’s show down the road at the Moscone Center.
Related Items:
Google Bypasses HDFS with New Cloud Storage Option
Can Google Harness Big Data to Ward Off Death?
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States