

March 6, 2014
Apache Spark: 3 Real-World Use Cases
The Hadoop processing engine Spark has risen to become one of the hottest big data technologies in a short amount of time. And while Spark has been a Top-Level Project at the Apache Software Foundation for barely a week, the technology has already proven itself in the production systems of early adopters, including Conviva, ClearStory, and Yahoo.
![]() Spark is an open source alternative to MapReduce designed to make it easier to build and run fast and sophisticated applications on Hadoop. Spark comes with a library of machine learning (ML) and graph algorithms, and also supports real-time streaming and SQL apps, via Spark Streaming and Shark, respectively. Spark apps can be written in Java, Scala, or Python, and have been clocked running 10 to 100 times faster than equivalent MapReduce apps.
Spark is an open source alternative to MapReduce designed to make it easier to build and run fast and sophisticated applications on Hadoop. Spark comes with a library of machine learning (ML) and graph algorithms, and also supports real-time streaming and SQL apps, via Spark Streaming and Shark, respectively. Spark apps can be written in Java, Scala, or Python, and have been clocked running 10 to 100 times faster than equivalent MapReduce apps.
Matei Zaharia, the creator of Spark and CTO of commercial Spark developer Databricks, shared his views on the Spark phenomena, as well as several real-world use cases, during his presentation at the recent Strata conference in Santa Clara, California.
Since its introduction in 2010, Spark has caught on very quickly, and is now one of the most active open source Hadoop projects–if not the most active. “In the past year Spark has actually overtaken Hadoop MapReduce and every other engine we’re aware of in terms of the number of people contributing to it,” Zaharia says. “It’s an interesting thing. There hasn’t been as much noise about it commercially, but the actual developer community votes with its feet and people are actually getting things done and working with the project.”
Zaharia argues that Spark is catching on so quickly because of two factors: speed and sophistication. “Achieving the best speed and the best sophistication have usually required separate non-commodity tools that don’t run on these commodity clusters. [They’re] often proprietary and quite expensive,” says Zaharia, a 5th year Ph.D. candidate who is also an assistant professor of computer science at MIT.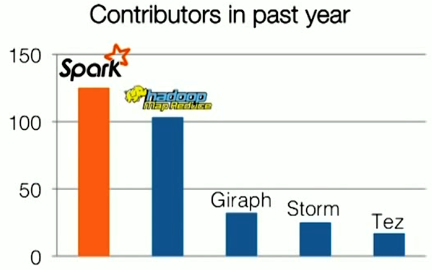
Up to this point, only large companies, such as Google, have had the skills and resources to make the best use of big and fast data. “There are many examples…where anybody can, for instance, crawl the Web or collect these public data sets, but only a few companies, such as Google, have come up with sophisticated algorithms to gain the most value out of it,” Zaharia says.
Spark was “designed to address this problem,” he says. “Spark brings the top-end data analytics, the same performance level and sophistication that you get with these expensive systems, to commodity Hadoop cluster. It runs in the same cluster to let you do more with your data.”
Spark at Yahoo
It may seem that Spark is just popping onto the scene, but it’s been utilized for some time in production systems. Here are three early adopters of Spark, as told by Zaharia at Strata:
Yahoo has two Spark projects in the works, one for personalizing news pages for Web visitors and another for running analytics for advertising. For news personalization, the company uses ML algorithms running on Spark to figure out what individual users are interested in, and also to categorize news stories as they arise to figure out what types of users would be interested in reading them.
“When you do personalization, you need to react fast to what the user is doing and the events happening in the outside world,” Zaharia says. “If you look at Yahoo’s home page, which news items are you going to show? You need to learn something about each news item as it comes in to see what users may like it. And you need to learn something about users as they click around to figure out that they’re interest in a topic.”
To do this, Yahoo (a major contributor to Apache Spark) wrote a Spark ML algorithm 120 lines of Scala. (Previously, its ML algorithm for news personalization was written in 15,000 lines of C++.) With just 30 minutes of training on a large, hundred million record data set, the Scala ML algorithm was ready for business.
Yahoo’s second use case shows off Hive on Spark (Shark’s) interactive capability. The Web giant wanted to use existing BI tools to view and query their advertising analytic data collected in Hadoop. “The advantage of this is Shark uses the standard Hive server API, so any tool that plugs into Hive, like Tableau, automatically works with Shark,” Zaharia says. “And as a result they were able to achieve this and can actually query their ad visit data interactively.”
Spark at Conviva and ClearStory
Another early Spark adopter is Conviva, one of the largest streaming video companies on the Internet, with about 4 billion video feeds per month (second only to YouTube). As you can imagine, such an operation requires pretty sophisticated behind-the-scenes technology to ensure a high quality of service. As it turns out, it’s using Spark to help deliver that QoS by avoiding dreaded screen buffering.
In the early days of the Internet, screen buffering was a fact of life. But in today’s superfast 4G- and fiber-connected world, people’s expectations for video quality have soared, while at the same time their tolerance for video delays has plummeted.
Enter Spark. “Conviva uses Spark Streaming to learn network conditions in real time,” Zaharia says. “They feed [this information] directly into the video player, say the Flash player on your laptop, to optimize the speeds. This system has been running in production over six months to manage live video traffic.” (You can read more about Conviva’s use of Hadoop, Hive, MapReduce, and Spark here.)
Spark are also getting some work at ClearStory, a developer of data analytics software that specializes in data harmonization and helping users blend internal and external data. ClearStory needed a way to help business users merge their internal data sources with external sources, such as social media traffic and public data feeds, without requiring complex data modeling.
ClearStory was one of Databricks first customers, and today relies on the Spark technology as one of the core underpinnings of its interactive, real-time product. “Honestly if it weren’t for Spark we would have very likely built something like this ourselves,” ClearStory founder Vaibhav Nivargi says in an interview with Databricks co-founder Reynold Xin.
“Spark has notion of resident distributed data sets which are these in-memory units of data that can span across multiple machines in a cluster,” Nivargi says in the video. “As a computing unit of data that is really promising for the kinds of workloads we see at ClearStory.”
Related Items:
Spark Graduates Apache Incubator
Databricks Partners with Cloudera for Analytics
Technologies:
Middleware
Vendors:
Startups and More...
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States