

September 9, 2013
Accelerate Hadoop MapReduce Performance using Dedicated OrangeFS Servers
Sponsored Content
Recent tests performed at Clemson University achieved a 25 percent improvement in Apache Hadoop Terasort run times by replacing Hadoop Distributed File System (HDFS) with an OrangeFS configuration using dedicated servers. Key components included extension of the MapReduce “FileSystem” class and a Java Native Interface (JNI) shim to the OrangeFS client. No modifications of Hadoop were required, and existing MapReduce jobs require no modification to utilize OrangeFS. The results also demonstrated the ability to deploy MapReduce with a general purpose High Performance file system in a High Performance Computing (HPC) environment, increasing potential for more flexible workflow.
The open source Hadoop MapReduce project has a traditional hardware architecture that differs from standard HPC architecture, where thin clients access remote, shared, and potentially distributed data servers. With HDFS, clients and data servers are paired together, running on the same hardware. Many HPC sites would like to extend their cluster use to support Hadoop MapReduce. With OrangeFS providing distributed storage as part of HPC clusters, they could leverage their existing investment in HPC to run Hadoop MapReduce workloads.
Through testing this configuration, a number of benefits emerged:
- MapReduce clients accessing a dedicated OrangeFS storage cluster yielded a 25 percent faster combined run time than the traditional approach, where MapReduce clients access data locally for the three operations (teragen, terasort, and teravalidate).
- OrangeFS and HDFS, without replication enabled, performed similarly under identical local (traditional HDFS) configurations (within 0.2 percent); however, OrangeFS adds the advantages of a general purpose, scale-out file system. With a general purpose file system, applications can read and write data to OrangeFS while it remains available for Hadoop MapReduce job input, improving run time by eliminating time-consuming HDFS stage-in and stage-out operations.
- Doubling the number of compute nodes accessing the OrangeFS cluster results in ~300 percent improvement on Terasort job run time.
- OrangeFS provides good results when clients significantly overcommit storage servers.
About OrangeFS
OrangeFS is a user-friendly, open-source, next-generation parallel file system for compute and storage clusters of the future. OrangeFS increases IO performance by storing a file in objects across multiple servers and accessing these objects in parallel. Offering more feature rich data access and manipulation than HDFS, OrangeFS is an ideal tool for storing, processing and analyzing data with MapReduce. A staff of developers support OrangeFS, improving stability and functionality for the base system and developing new interfaces.
OrangeFS has an object-based infrastructure. Each file and directory consists of two or more objects: one primarily containing file metadata, and the other(s) primarily containing file data. Objects may contain both data and metadata as needed to fulfill their role in the file system. This division and distribution of data to the servers is imperceptible to users, who see a traditional, logical file view. The OrangeFS distributed file structure provides outstanding scalability in performance and capacity.
OrangeFS client interfaces work with a range of operating systems, including Linux, Mac OS X and Windows. Compatible client interfaces include Direct Interface, WebDAV, S3, REST, FUSE, Hadoop and MPI-IO.
OrangeFS with Hadoop MapReduce
Hadoop’s abstract FileSystem class allows MapReduce to leverage file systems other than HDFS, with a configuration file that sets the designated file system. Hadoop MapReduce is written in Java, but OrangeFS’s client libraries are written in C. A Java Native Interface (JNI) shim allows data to be passed between programs, avoiding the overhead of memory copies with Java’s NIO Direct ByteBuffer. The JNI shim allows Java code to execute functions present in the OrangeFS Direct Client Interface. The OrangeFS Direct Client Interface Library is a collection of familiar POSIX-like and system standard input/output (stdio.h) library calls designed for parallel access to OrangeFS. OrangeFS differs from HDFS in that it allows modification of data after the initial write.
The Terasort benchmarks successfully explored potential for replacing HDFS with the prerelease version 2.8.8 of OrangeFS, working with the Hadoop 1.x stable release. The two Hadoop configurations which were evaluated are shown in Figure 1.
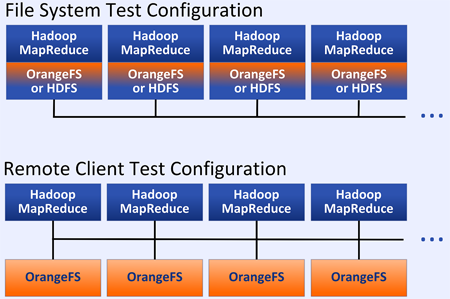
Figure 1 Test Configurations
Test Protocols
Hadoop MapReduce File System Test (Figure 2)
To test the impact of replacing HDFS with OrangeFS, developers performed a full terabyte (1 TB) Terasort benchmark on 8 nodes, each running both MapReduce and the file system shown in the first configuration above. The tests were performed on 8 Dell PowerEdge R720s with local SSDs for metadata and 12 2-TB drives for data. In this test, MapReduce ran locally on the same nodes, first over OrangeFS and then over HDFS, interconnected with 10Gb/s Ethernet. Both file systems used the compute nodes for storage as well.
Hadoop MapReduce Remote Client Test
Using the same benchmarks with typical HPC storage architecture, another test, “OFS Remote” in Figure 2, measured how MapReduce performs when data is stored on dedicated, network-connected storage nodes running OrangeFS. Eight additional nodes were used as MapReduce clients, and eight Dell PowerEdge R720s with local SSDs for metadata and 12 2-TB drives for data were used as storage nodes only, shown in the Remote Client Test Configuration in Figure 1.
Results
OrangeFS decreased Terasort run time in the dedicated OrangeFS storage cluster architecture by about 25 percent over the traditional MapReduce architecture, where clients access data from local disks. OrangeFS and HDFS, without replication enabled, performed similarly under identical local (traditional HDFS) configurations (within 0.2 percent); however, OrangeFS adds the advantages of a general purpose, scale-out file system.
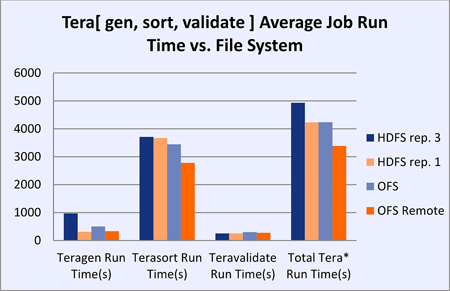
Figure 2 Hadoop MapReduce File System Test
Hadoop MapReduce over OrangeFS with Overcommitted Storage Servers (Figure 3)
A separate test evaluated MapReduce over OrangeFS, overcommitting the storage nodes and evaluating how well this approach scales with more MapReduce clients than storage nodes. The Terasort test was performed with an increasing number of clients utilizing a dedicated OrangeFS cluster composed of 16 Dell PowerEdge R720s with local SSDs for metadata and 12 2-TB drives for data. The Hadoop client nodes had only a single hard disk drive available for intermediate data storage purposes, increasing the time over previous tests where Hadoop clients possessed 12 disks. If the clients used a solid state drive (SSD) for storage and retrieval of intermediate data instead, the slowdown caused by the single disk compared to an array of disks would be alleviated to some extent.
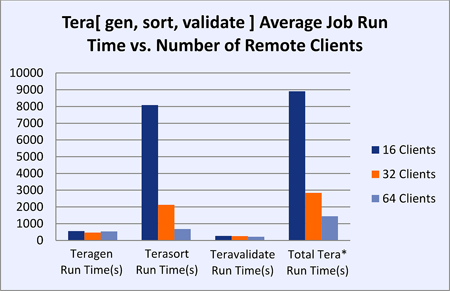
Figure 3 Hadoop MapReduce over OrangeFS with Overcommitted Storage Servers
Results
In testing 16, 32, and 64 compute nodes, doubling the number of compute nodes caused a ~300 percent improvement on Terasort job run time. OrangeFS provides good results when clients significantly overcommit the storage servers (4 to 1 in these tests). While providing improvements as a good general purpose file system for MapReduce, OrangeFS is also an excellent concurrent working file system to support the storage needs of other applications while simultaneously serving Hadoop MapReduce.
Benefits
- OrangeFS enables modification of data anywhere in a file, while HDFS requires copying data before modification, except in the case of Append in the Hadoop 2.x release.
- OrangeFS replaces the HDFS single namenode with multiple OrangeFS metadata/data servers, reducing task time with improved scalability and eliminating this single point of contention.
- Potentially, intermediate data can also be written to OrangeFS rather than a temporary folder on each Hadoop client disk, optionally retaining it for use in future jobs and further improving performance with OrangeFS serving the data to MapReduce.
Obstacles
- Unlike HDFS, OrangeFS doesn’t currently support built-in replication. (OrangeFS can be run in High Availability (HA) mode, and plans for the 3.0 release of OrangeFS include integrated replication for both data and metadata.)
- OrangeFS and Hadoop are separate installations which must be configured to work together. (Plans for the 2.8.8 release of OrangeFS include a more comprehensive documentation set, including instructions for using Hadoop’s MapReduce with the OrangeFS file system.)
Conclusion
The results demonstrated that replacing HDFS with OrangeFS produced better MapReduce performance for workloads with high volumes of intermediate data, i.e., terasort.
Separating MapReduce clients from storage servers can provide stability in the case of client failure, without the overhead of replication, and eases local disk contention during the reduce stage.
Hadoop MapReduce can leverage OrangeFS as its underlying storage system in an HPC environment. A Portable Batch System (PBS) or Sun Grid Engine (SGE) scheduled HPC environment can support on-demand Hadoop MapReduce clusters deployed and configured automatically, using the open source project “myHadoop.” Researchers could customize a version of myHadoop to schedule on-demand MapReduce clusters, with data persisting on OrangeFS, eliminating HDFS’s time consuming data stage-in and stage-out phases. (myHadoop scripts will be available with the next release of OrangeFS, for running jobs in a scheduled environment.)
Future evaluations may test how performance could be improved, since Hadoop Map and Reduce tasks could be patched to support reading and writing intermediate data to OrangeFS, rather than local disk, improving job run time with faster I/O rates.
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States