

April 11, 2024
Cohere Introduces Rerank 3: A New Foundation Model for Efficient Enterprise Search & Retrieval
April 11, 2024 — Cohere today unveiled its latest foundation model, Rerank 3. In this blogpost, Sylvie Shi and Nils Reimers detail how this innovative model is set to advance enterprise search and Retrieval Augmented Generation (RAG) systems, promising enhanced efficiency and accuracy.
 Today, we’re introducing our newest foundation model, Rerank 3, purpose built to enhance enterprise search and Retrieval Augmented Generation (RAG) systems.
Today, we’re introducing our newest foundation model, Rerank 3, purpose built to enhance enterprise search and Retrieval Augmented Generation (RAG) systems.
Our model is compatible with any database or search index and can also be plugged into any legacy application with native search capabilities. With a single line of code, Rerank 3 can boost search performance or reduce the cost of running RAG applications with negligible impact to latency.
Rerank 3 offers state-of-the-art capabilities for enterprise search, including:
- 4k context length to significantly improve search quality for longer documents.
- Ability to search over multi-aspect and semi-structured data like emails, invoices, JSON documents, code, and tables.
- Multilingual coverage of 100+ languages.
- Improved latency and lower total cost of ownership (TCO).
Generative models with long contexts have the ability to execute RAG. However, in order to optimize accuracy, latency and cost a RAG solution requires a combination of generative models and our Rerank models. The high precision semantic reranking of Rerank 3 makes sure that only the most relevant information is fed to the generative model, increasing response accuracy and keeping latency and cost low, in particular when retrieving information from thousands and millions of documents.
Enhanced Enterprise Search
Enterprise data is often complex and current systems have difficulty searching through multi-aspect and semi-structured data sources. The most useful data at companies is not often in simple document format and semi-structured data formats such as JSON are common across enterprise applications. Rerank 3 is able to rank complex, multi-aspect data (e.g. emails) based on all of their relevant metadata fields, including their recency.
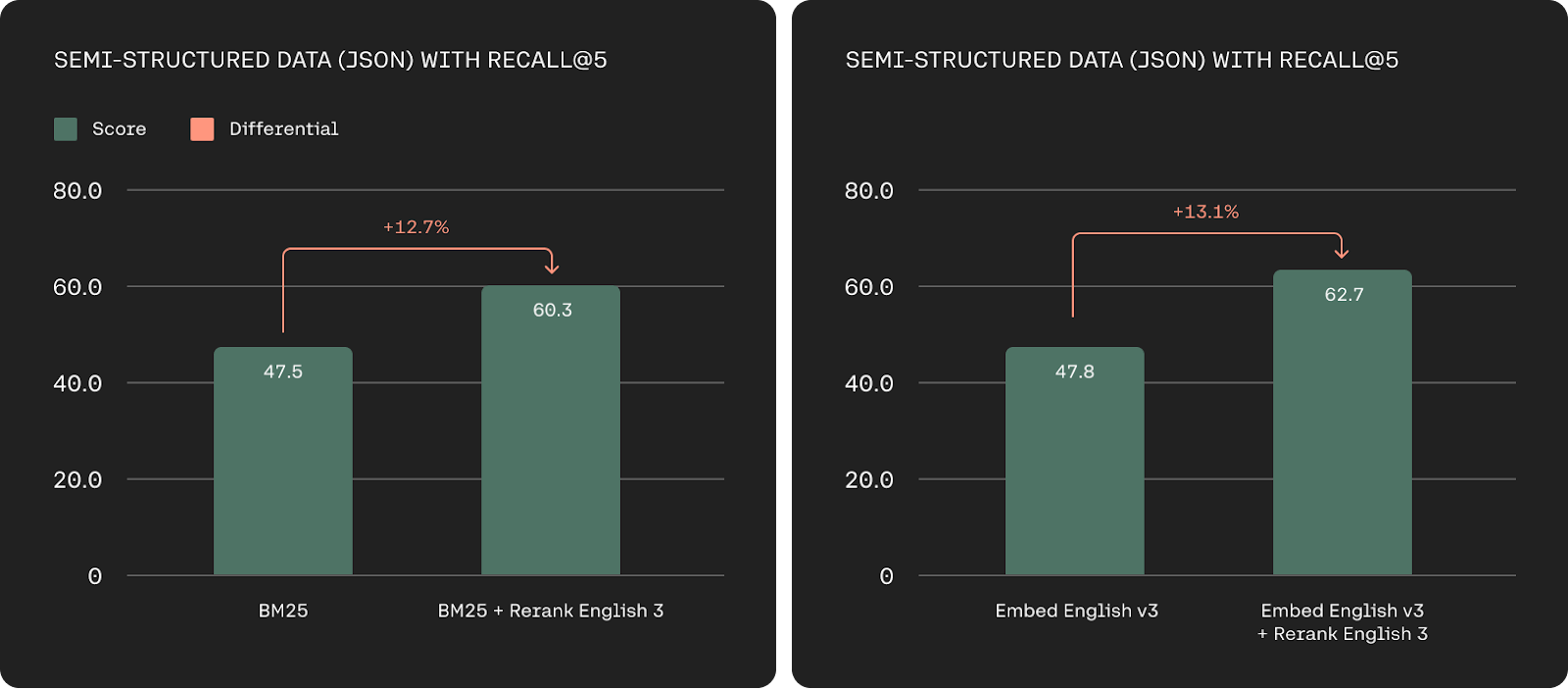
Semi-structured retrieval accuracy based Recall@5 on TMDB-5k-Movies, WikiSQL, nq-tables, and Cohere annotated datasets (higher is better).
Rerank 3 also demonstrates a marked improvement on code retrieval capabilities. This could include retrieval over an enterprise’s proprietary code repository to enhance the productivity of their engineering teams, or over huge corpuses of documentation.
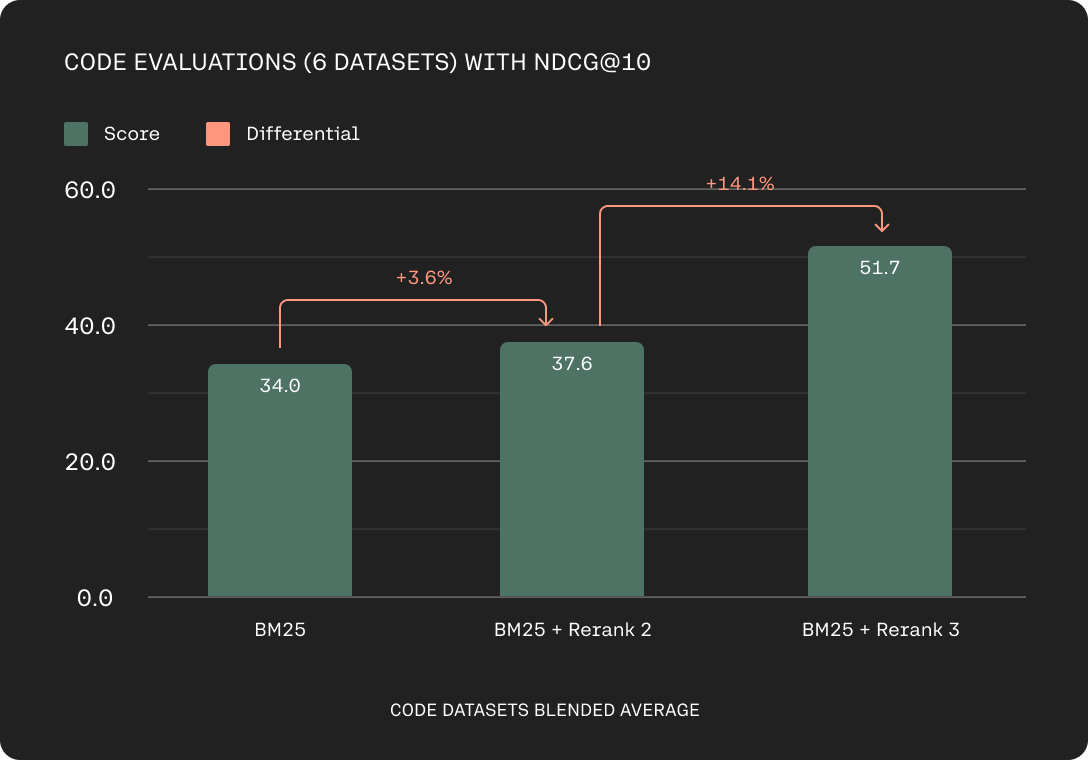
Code evaluation accuracy based on nDCG@10 on Codesearchnet, Stackoverflow, CosQA, Human Eval, MBPP, DS1000 (higher is better).
Global organizations also deal with multilingual data sources and historically multilingual retrieval has been a challenge with keyword-based methods. Our Rerank 3 model offers strong multilingual performance in over 100+ languages simplifying retrieval for non-English speaking customers.
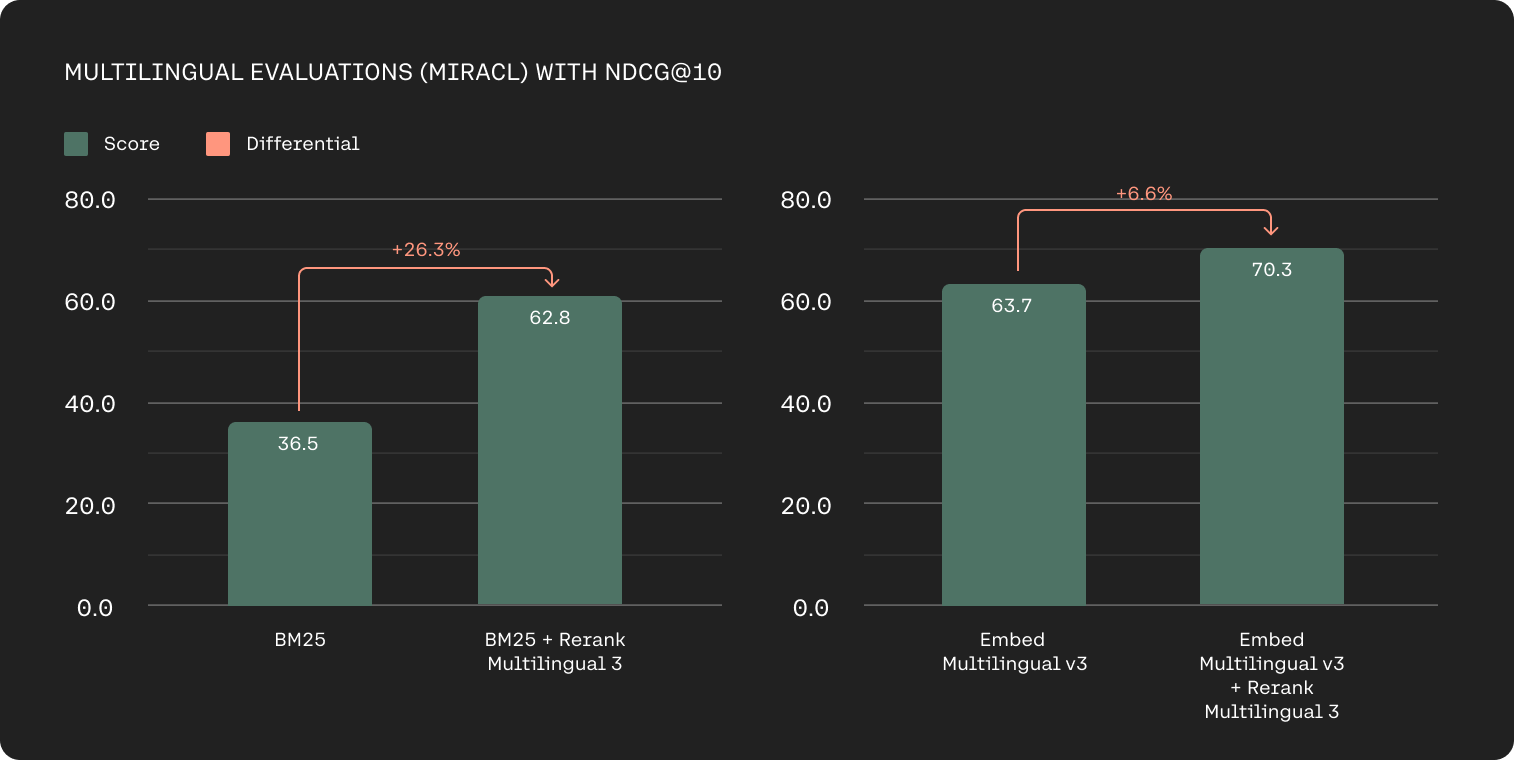
Multilingual retrieval accuracy based nDCG@10 on MIRACL (higher is better).
A primary challenge when building semantic search and RAG systems is determining how to best chunk your data. Our Rerank 3 model now boasts a 4k context length allowing customers to pass in larger documents for ranking. This allows our model to consider more context from the document when determining a relevance score, and reduces the need for chunking documents in order to fit within the model’s context window.
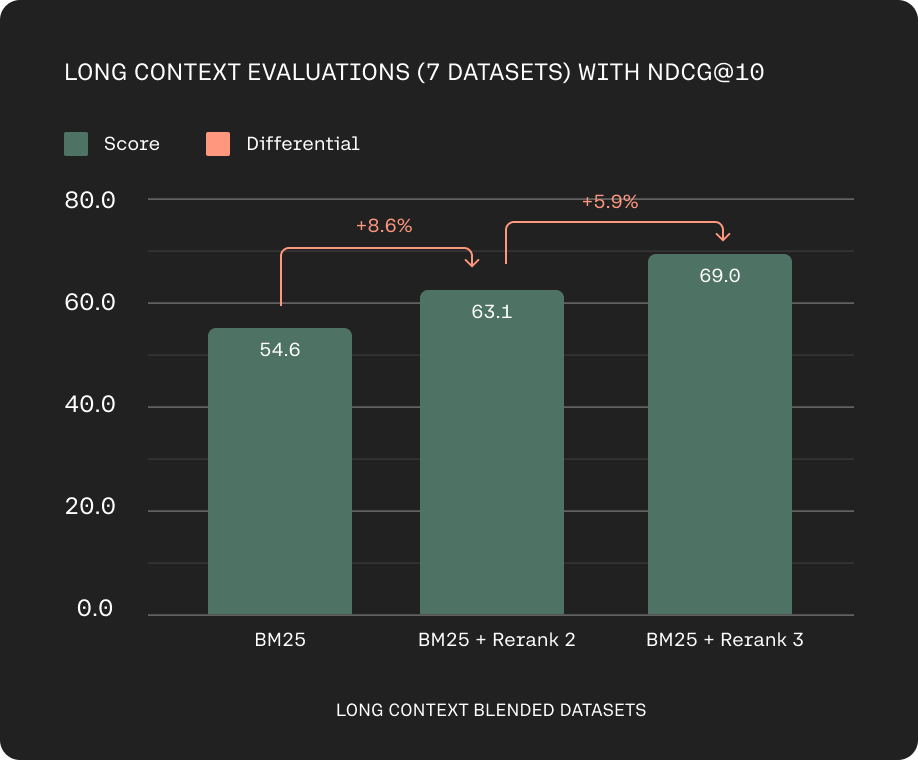
Long context accuracy based on nDCG@10 on TREC 2019-2022, Conditional QA , NQ-Hard, Qasper, Genomics, QMSum, FinanceBench (higher is better).
We are also excited to announce that Rerank 3 is supported natively in Elastic‘s Inference API starting today. Elasticsearch has a widely adopted search technology and the keyword and vector search capabilities in the Elasticsearch platform are built to handle complex enterprise data. To start building enterprise search systems with Cohere and Elastic, check out the latest guide here.
“We’re excited to be partnering with Cohere to help businesses unlock the potential of their data.” said Matt Riley, GVP & GM of Elasticsearch “Cohere’s advanced retrieval models, Embed 3 and Rerank 3, offer leading performance on complex enterprise data. They are quickly becoming essential components in any enterprise search system. We’re happy to have Cohere’s offerings deeply integrated into Elasticsearch via our Inference API, as critical developer tools for best in class relevance and hybrid search.”
Improved Latency Even with Longer Context
In many business domains such as e-commerce or customer service, low latency is crucial to delivering a quality experience. We kept this in mind while building Rerank 3, which shows up to 2x lower latency compared to Rerank 2 for shorter document lengths and up to 3x improvements at long context lengths.
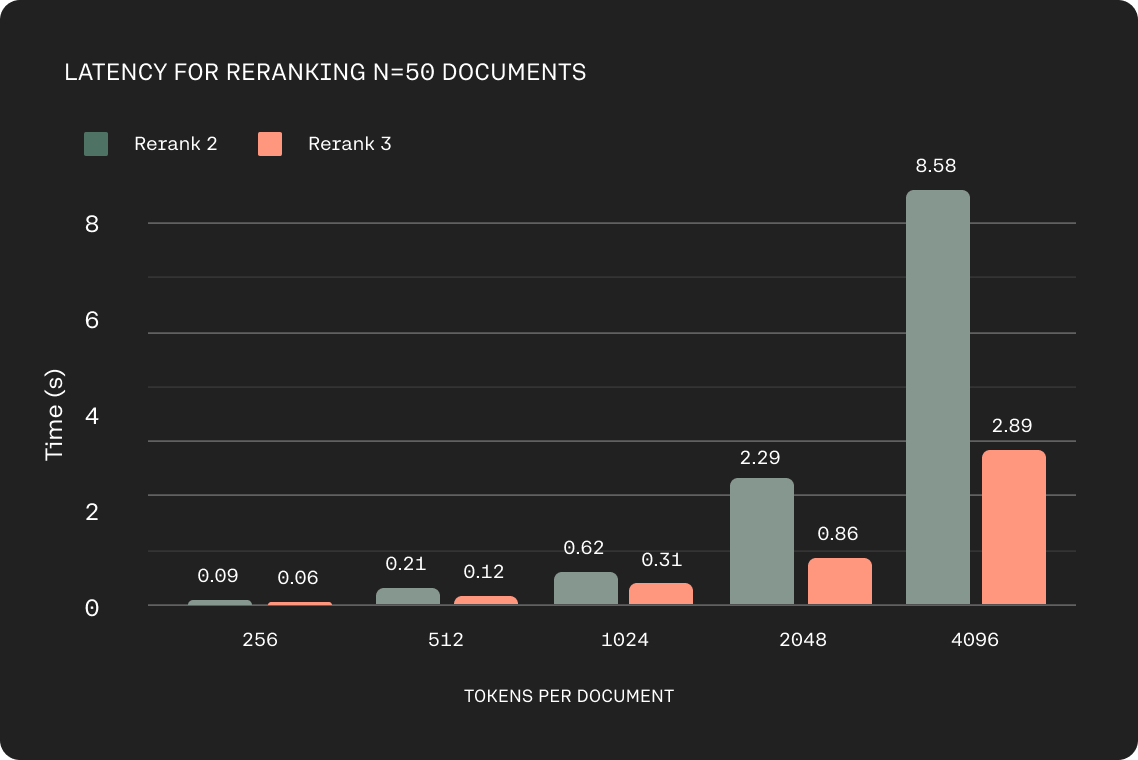
Comparisons computed as the time to rank 50 documents across a variety of document token-length profiles; each run assumes a batch of 50 documents with uniform token length across each document.
More Performant and Efficient RAG
The retrieval step is crucial in RAG. Rerank 3 bolsters the key factors for strong RAG performance: quality of responses and latency. Our model helps you isolate the most relevant documents to respond to a user’s question and increases the response accuracy of the overall RAG system. This allows large enterprises to unlock massive value from their proprietary data and source relevant information to support tasks in a range of business functions from customer support, legal, HR, finance, and more.
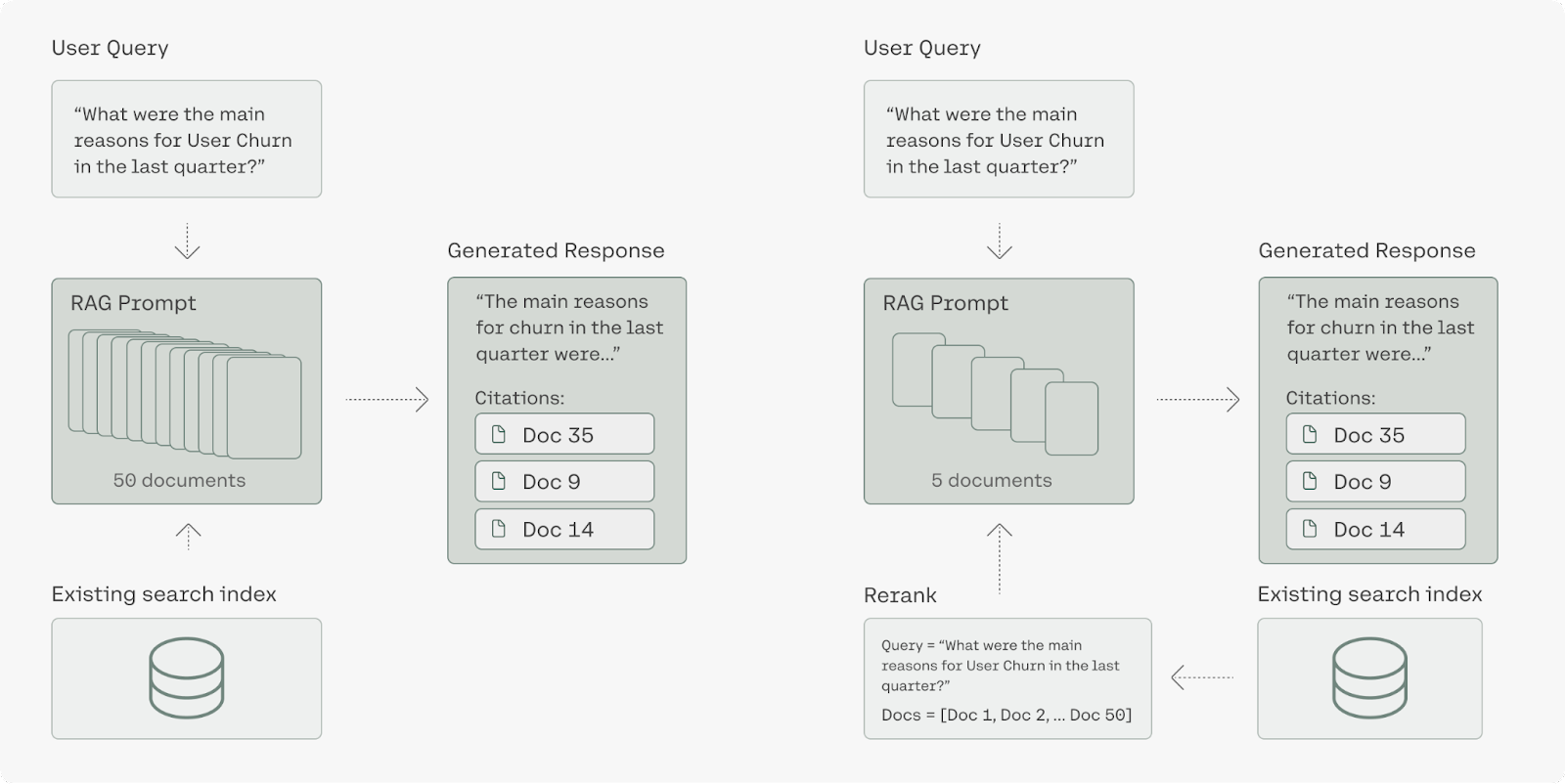
When combined with our highly efficient Command R family of models for RAG, Rerank 3 further reduces total cost of ownership (TCO) for customers. Adding Rerank into a RAG system allows users to pass fewer, more relevant documents to the LLM for grounded generation while maintaining overall accuracy and without adding latency. The net effect makes running RAG with Rerank on Command R+ 80-93% less expensive than other generative LLMs in the market, and with Rerank and Command R savings can top 98%.
When combined with our highly efficient Command R family of models for RAG, Rerank 3 further reduces total cost of ownership (TCO) for customers. Adding Rerank into a RAG system allows users to pass fewer, more relevant documents to the LLM for grounded generation while maintaining overall accuracy and without adding latency. The net effect makes running RAG with Rerank on Command R+ 80-93% less expensive than other generative LLMs in the market, and with Rerank and Command R savings can top 98%.
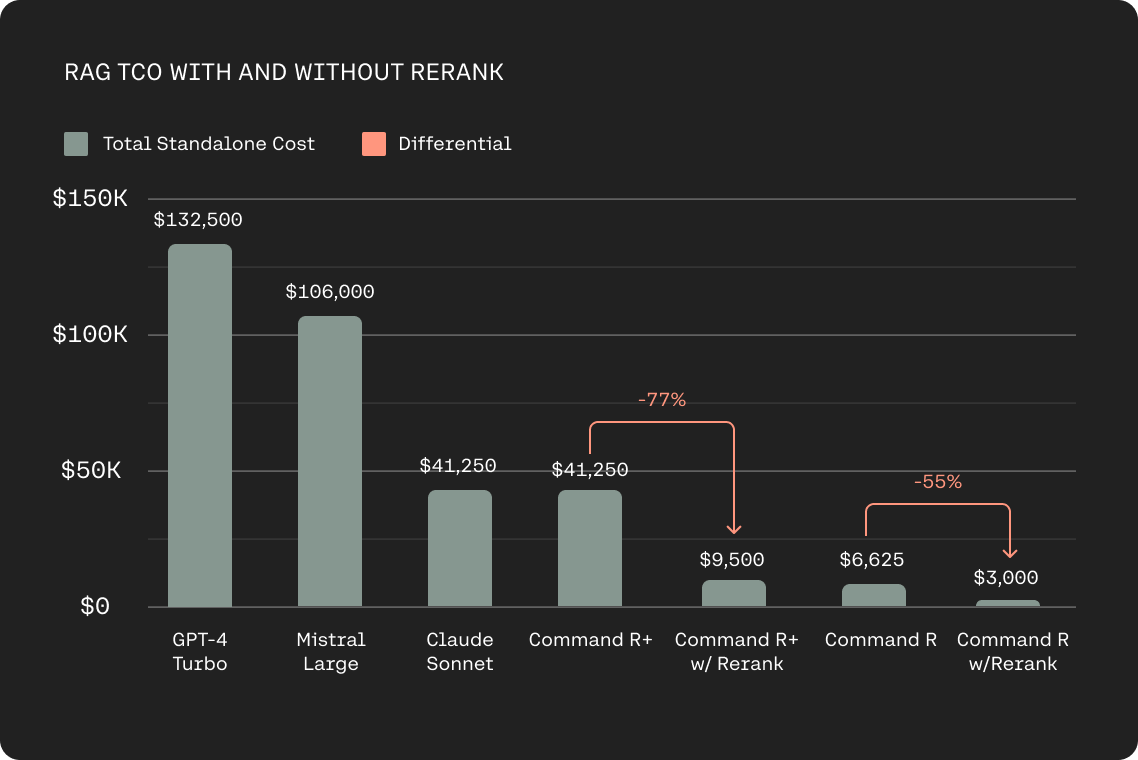
Standalone cost is based on inference costs for 1M RAG prompts with 50 docs containing 250 tokens each, and 250 output tokens. Cost with Rerank is based on inference costs for 1M RAG prompts with 5 docs @ 250 tokens each, and 250 output tokens.
An increasingly common approach for RAG is using LLMs as rerankers for document retrieval. Rerank 3 outperforms industry leading LLMs on ranking accuracy while being between 90-98% less expensive.
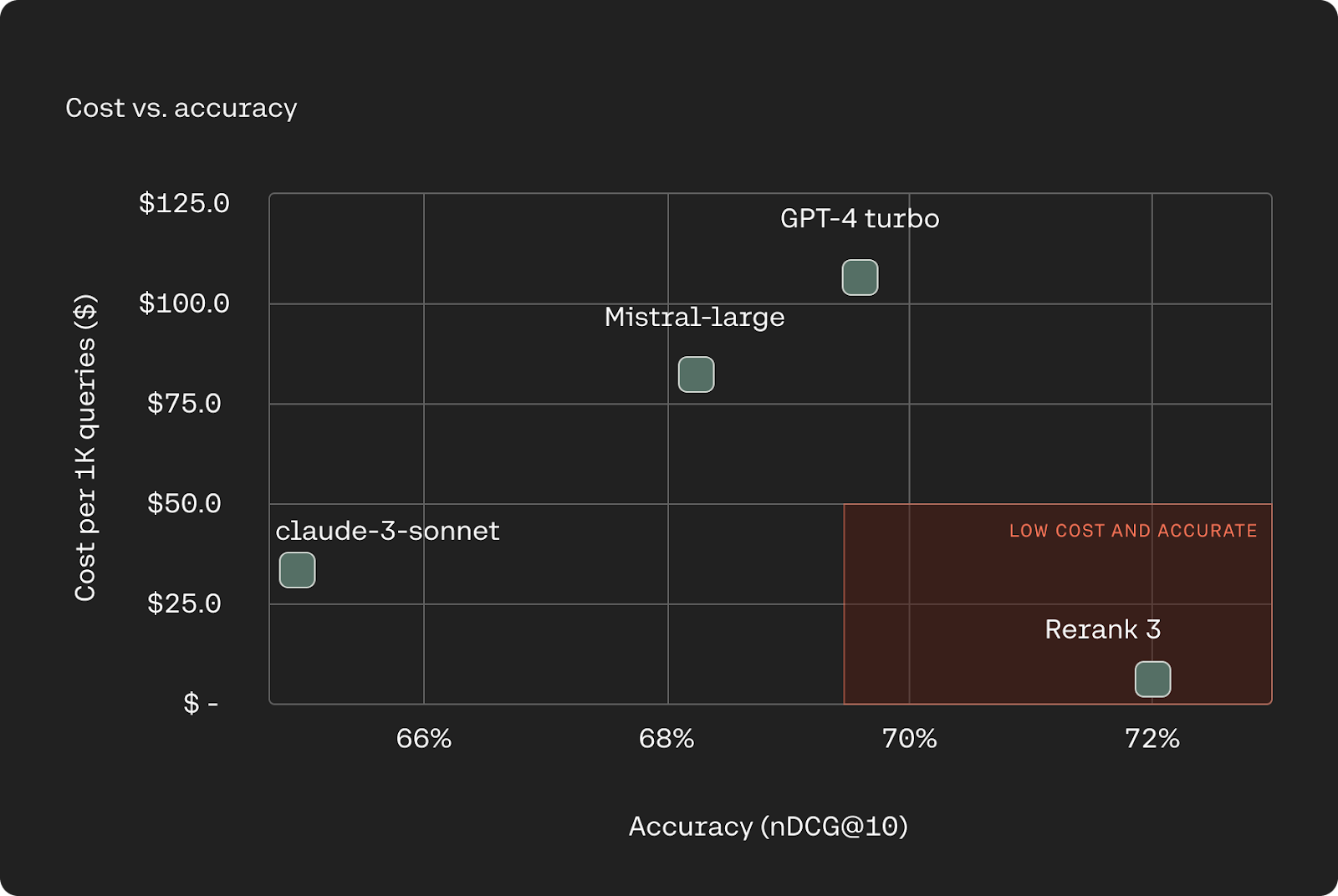
Accuracy based on nDCG@10 on TREC 2020 dataset (higher is better). LLMs are evaluated in a list-wise fashion following the approach used in RankGPT (Sun et al. 2023).
Rerank 3 not only helps reduce end-to-end TCO but also boosts the quality of the LLM response. Rerank achieves this by weeding out less relevant documents, and only sorting through the small subset of pertinent ones to draw answers.
How to Get Started
Starting today developers and businesses can access Rerank 3 on both Cohere’s hosted API and AWS Sagemaker. You can also access our model directly through the inference API in Elasticsearch to perform semantic reranking on your existing Elasticsearch index.
To understand how your company can start deploying with Rerank 3 at production-scale, reach out to our sales team.
Learn More
We have an upcoming webinar with AWS focused on building enterprise search apps powered by Rerank if you would like to register and learn more.
Source: Sylvie Shi and Nils Reimers, Cohere
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States