

April 8, 2024
Cohere Introduces Command R+: A Scalable LLM Built for Business
April 8, 2024 — Cohere recently announced the launch of Command R+, a cutting-edge addition to its R-series of large language models (LLMs). In this blog post, Cohere CEO Aidan Gomez delves into how this new model is poised to enhance enterprise-grade AI applications through enhanced efficiency, accuracy, and a robust partnership with Microsoft Azure.
 Today, we’re introducing Command R+, our most powerful, scalable large language model (LLM) purpose-built to excel at real-world enterprise use cases. Command R+ joins our R-series of LLMs focused on balancing high efficiency with strong accuracy, enabling businesses to move beyond proof-of-concept, and into production with AI.
Today, we’re introducing Command R+, our most powerful, scalable large language model (LLM) purpose-built to excel at real-world enterprise use cases. Command R+ joins our R-series of LLMs focused on balancing high efficiency with strong accuracy, enabling businesses to move beyond proof-of-concept, and into production with AI.
Command R+, like our recently launched Command R model, features a 128k-token context window and is designed to offer best-in-class:
- Advanced Retrieval Augmented Generation (RAG) with citation to reduce hallucinations
- Multilingual coverage in 10 key languages to support global business operations
- Tool Use to automate sophisticated business processes
Our latest model builds on the key strengths of Command R and further improves performance across the board. Command R+ outperforms similar models in the scalable market category, and is competitive with significantly more expensive models on key business-critical capabilities. We achieve this while providing the same commitment to data privacy and security that we’re known for.
As we continue to serve the global enterprise community, we are proud to announce a new collaboration with Microsoft Azure to accelerate enterprise AI adoption.
“The collaboration with Cohere underscores our dedication to leading the charge in the AI revolution, bringing the innovative Command R+ model to Azure AI,” said John Montgomery, CVP of Azure AI Platform at Microsoft. “This partnership exemplifies our commitment to providing a comprehensive suite of AI tools that empower businesses to achieve more while adhering to the highest standards of security and compliance. Together, we’re setting new benchmarks for what’s possible in enterprise AI, fostering a future where technology amplifies human capability and innovation.”
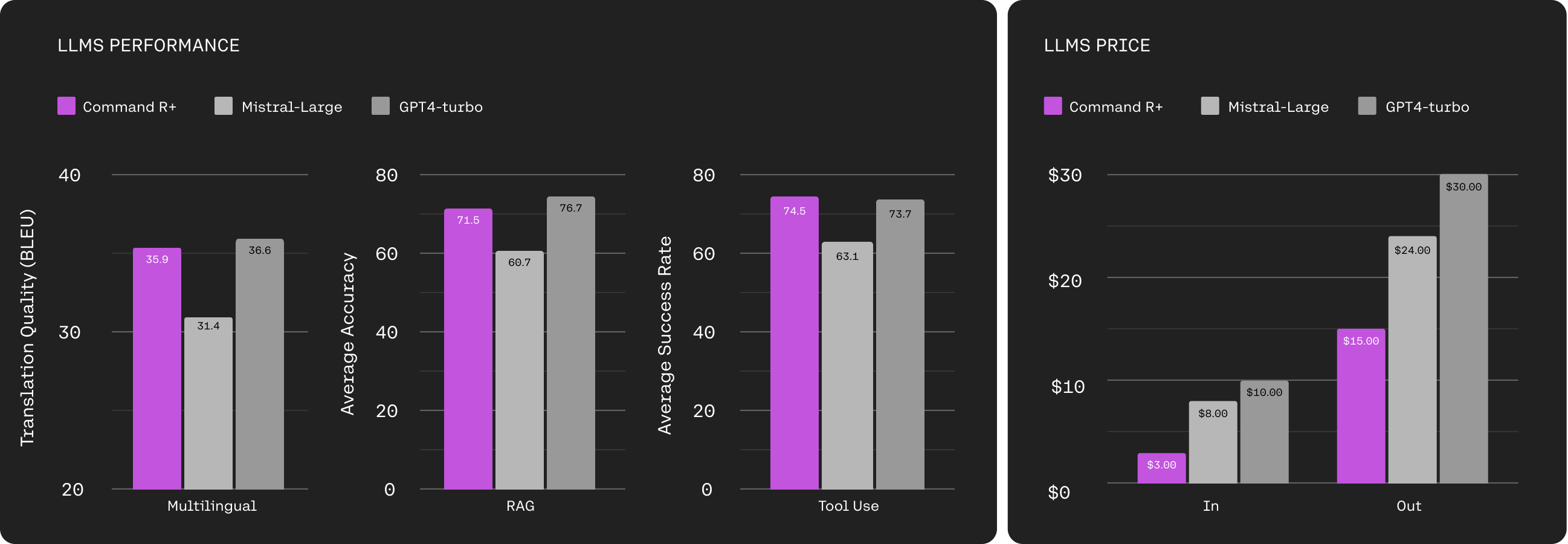
(Left) Performance comparison of models available on Azure across three key capabilities: Multilingual, RAG, and Tool Use. Performance is an average of model scores on benchmarks listed in subsequent figures below. (Right) Comparison input and output token costs per million for models available on Azure.
Developers and businesses can access Cohere’s latest model first on Azure, starting today, and soon to be available on Oracle Cloud Infrastructure (OCI), as well as additional cloud platforms in the coming weeks. Command R+ will also be available immediately on Cohere’s hosted API.
“Enterprises are clearly looking for highly accurate and efficient AI models like Cohere’s latest Command R+ to move into production,” said Miranda Nash, group vice president, Applications Development & Strategy, Oracle. “Models from Cohere, integrated in Oracle NetSuite and Oracle Fusion Cloud Applications, are helping customers address real-world business problems and improve productivity across areas such as finance, HR, and marketing.”
Industry Leading RAG Solution
RAG has become a foundational building block for enterprises adopting LLMs and customizing them with their own proprietary data. Command R+ builds upon Command R’s exceptional performance at RAG use cases.
Command R+ is optimized for advanced RAG to provide enterprise-ready, highly reliable, and verifiable solutions. The new model improves response accuracy and provides in-line citations that mitigate hallucinations. This capability helps enterprises scale with AI to quickly find the most relevant information to support tasks across business functions like finance, HR, sales, marketing, and customer support, among others, in a range of sectors.
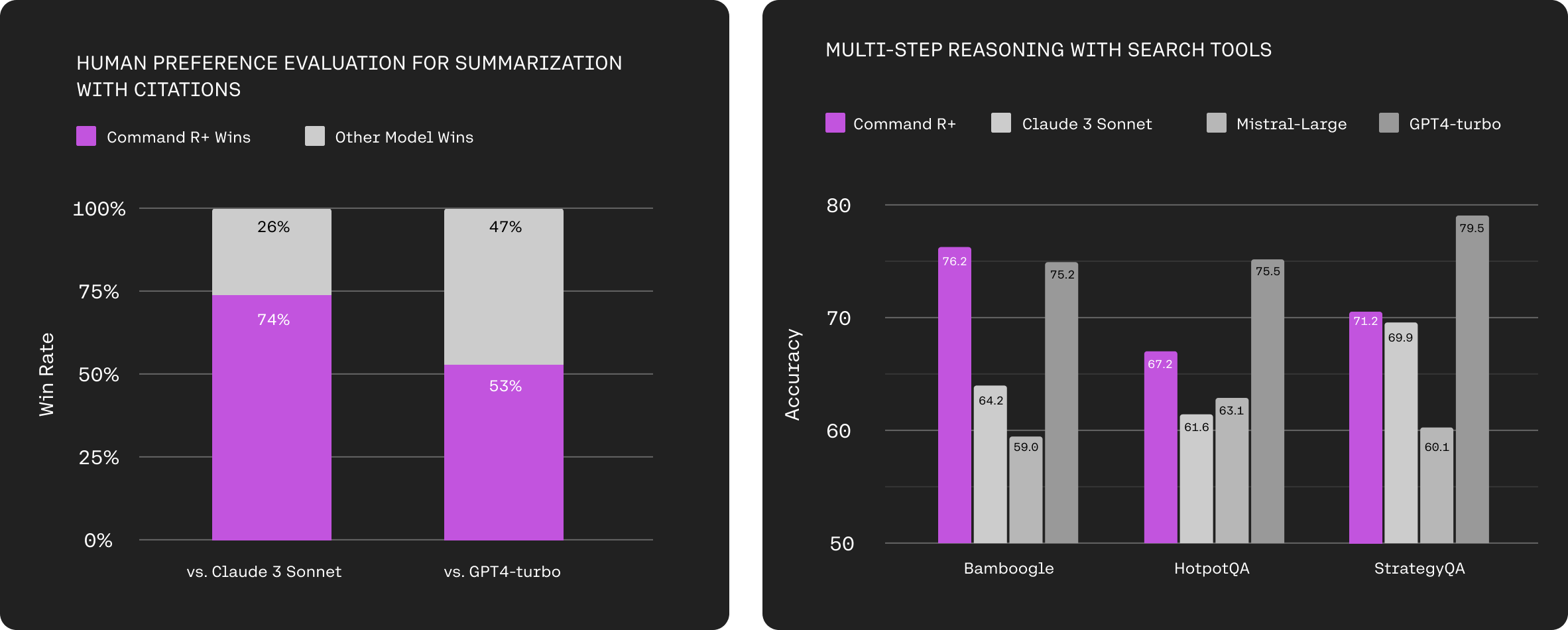
(Left) Human head-to-head preference results using a holistic grading scheme combining text fluency, citation quality, and overall utility. Citations are measured on a sentence level inside the summary connected to a chunk of a source document. We used a proprietary test set of 250 highly diverse documents and summarization requests with complex instructions resembling API data. Baseline models have been extensively prompt engineered with few shot prompts (Sonnet) and 2 step summarization first and citation insertion second (GPT4), while Command R+ uses our RAG-API. (Right) Accuracy of multi-hop REACT agents powered by various models with access to the same search tools retrieving from wikipedia (HotpotQA) and the internet (Bamboogle and StrategyQA). Accuracy for HotpotQA and Bamboogle is judged by three-way majority vote from prompted evaluators (Command R, GPT3.5, and Claude3-Haiku to reduce known intra-model bias), which we verified using human annotation on a one thousand example subset. Accuracy for StrategyQA is judged using a long form answer that ends in a yes/no judgement.
Automating Complex Business Workflows With Tool Use
A major promise of large language models is their ability to not only ingest and produce text, but to act as core reasoning engines: capable of making decisions and using tools to automate difficult tasks that demand intelligence to solve. To deliver this capability, Command R+ comes with Tool Use capabilities, accessible through our API and LangChain to seamlessly automate complex business workflows.
Our family of models combined with Tools can be used to address important enterprise use cases like keeping your customer relationship management (CRM) tasks, activities, and records up-to-date automatically. This capability helps upgrade our model applications from simple chatbots to powerful agents and research tools for increased productivity.
New in Command R+, we now support Multi-Step Tool Use which allows the model to combine multiple tools over multiple steps to accomplish difficult tasks. Command R+ can even correct itself when it tries to use a tool and fails, for instance when encountering a bug or failure in a tool, enabling the model to make multiple attempts at accomplishing the task and increasing the success rate.
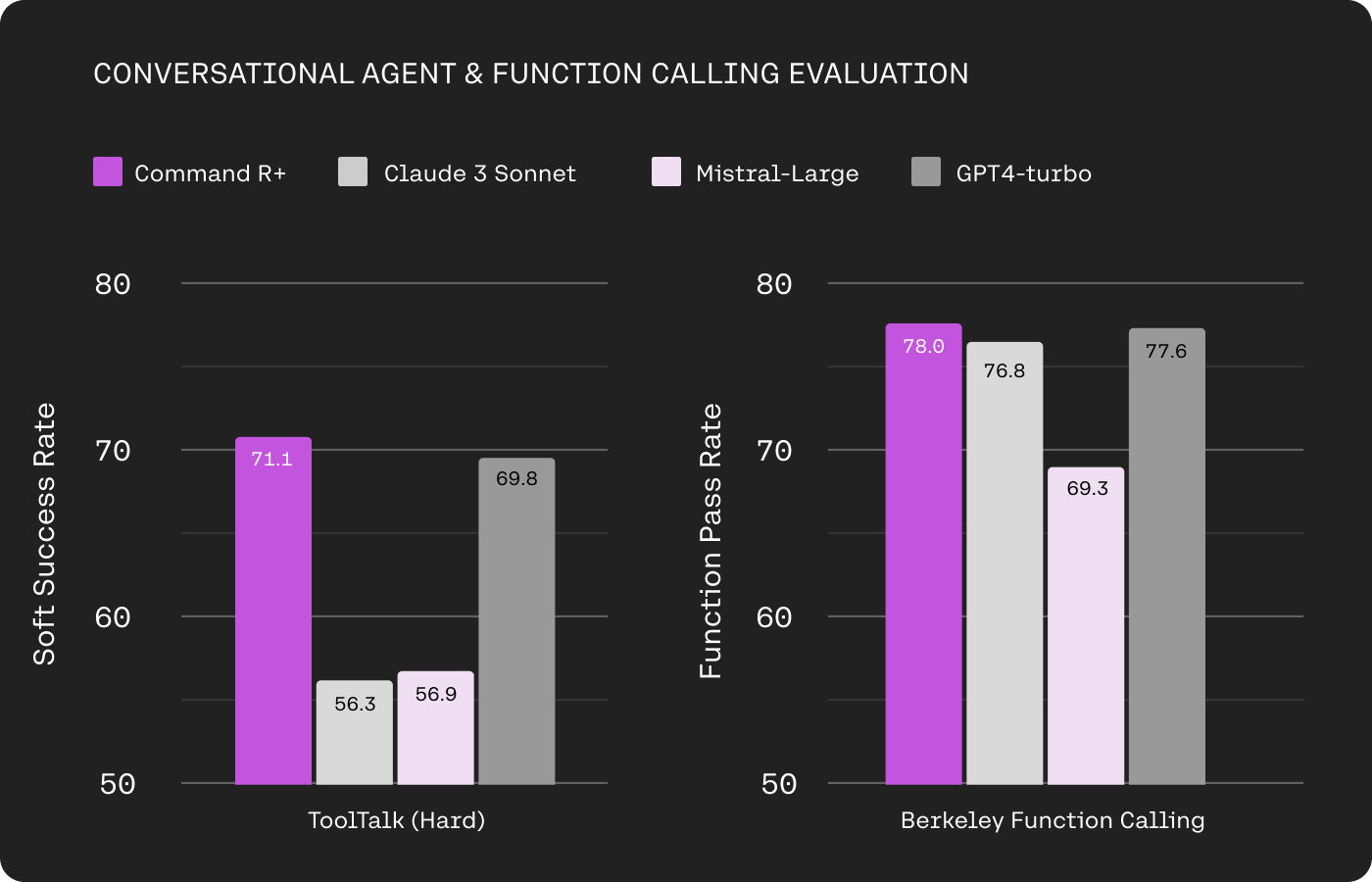
We evaluate both conversational tool-use and single-turn function-calling capabilities, using Microsoft’s ToolTalk (Hard) benchmark (Farn & Shin 2023) and Berkeley’s Function Calling Leaderboard (BFCL) (Yan et al. 2024). For ToolTalk predicted tool calls are evaluated against the ground-truth, with overall conversation success metrics deemed on how likely the model recalls all tool calls and avoids bad actions (i.e. a tool call that has unwanted side effects). For BFCL we included bug fixes in the evaluation – from which all models profited – and report an average function success rate score over all subcategories. We verified our bug fixes with an additional human evaluation cleaning step to prevent false negatives.
Multilingual Support for Global Business Operations
Command R+ is designed to serve as many people, organizations, and markets as possible. During our discussions with companies, we’re met with a huge demand for multilingual capabilities that helps organizations more seamlessly work across regions and cultures. That’s why we built Command R+ to excel at 10 key languages of global business: English, French, Spanish, Italian, German, Portuguese, Japanese, Korean, Arabic, and Chinese.
This multilingual capability enables users to generate accurate responses from a vast set of data sources, regardless of their native language, helping us to power product features and tools for geographically diverse global companies. We look forward to seeing businesses around the world try our Command R model family to power their business operations and products.
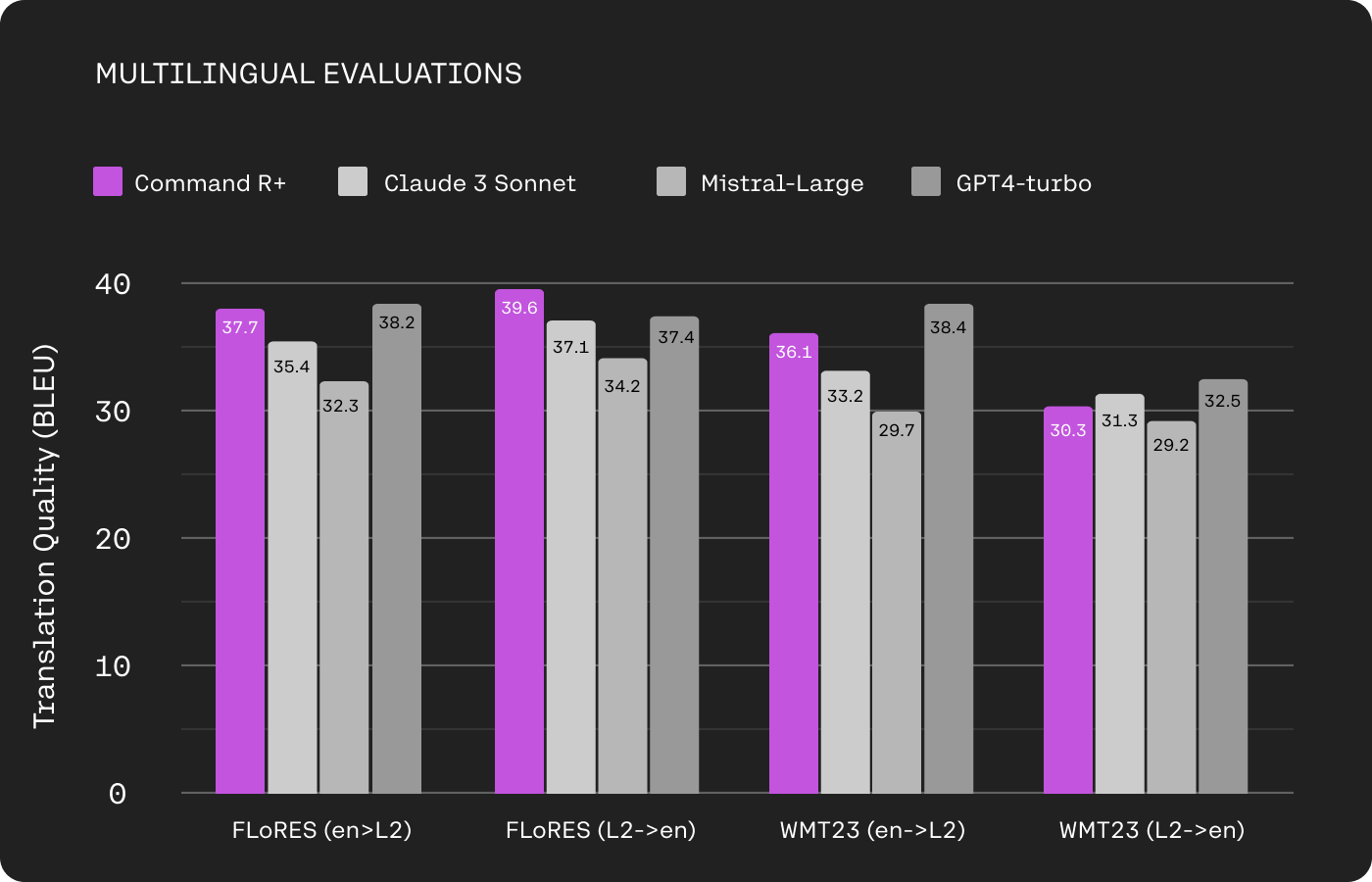
Comparison of models on FLoRES (in French, Spanish, Italian, German, Portuguese, Japanese, Korean, Arabic, and Chinese) and WMT23 (in German, Japanese, and Chinese) translation tasks.
Not only is Command R+ a strong multilingual model, but the R-series of models features a tokenizer that compresses non-English text much better than the tokenizer used for other models in the market, capable of achieving up to a 57% reduction in cost.
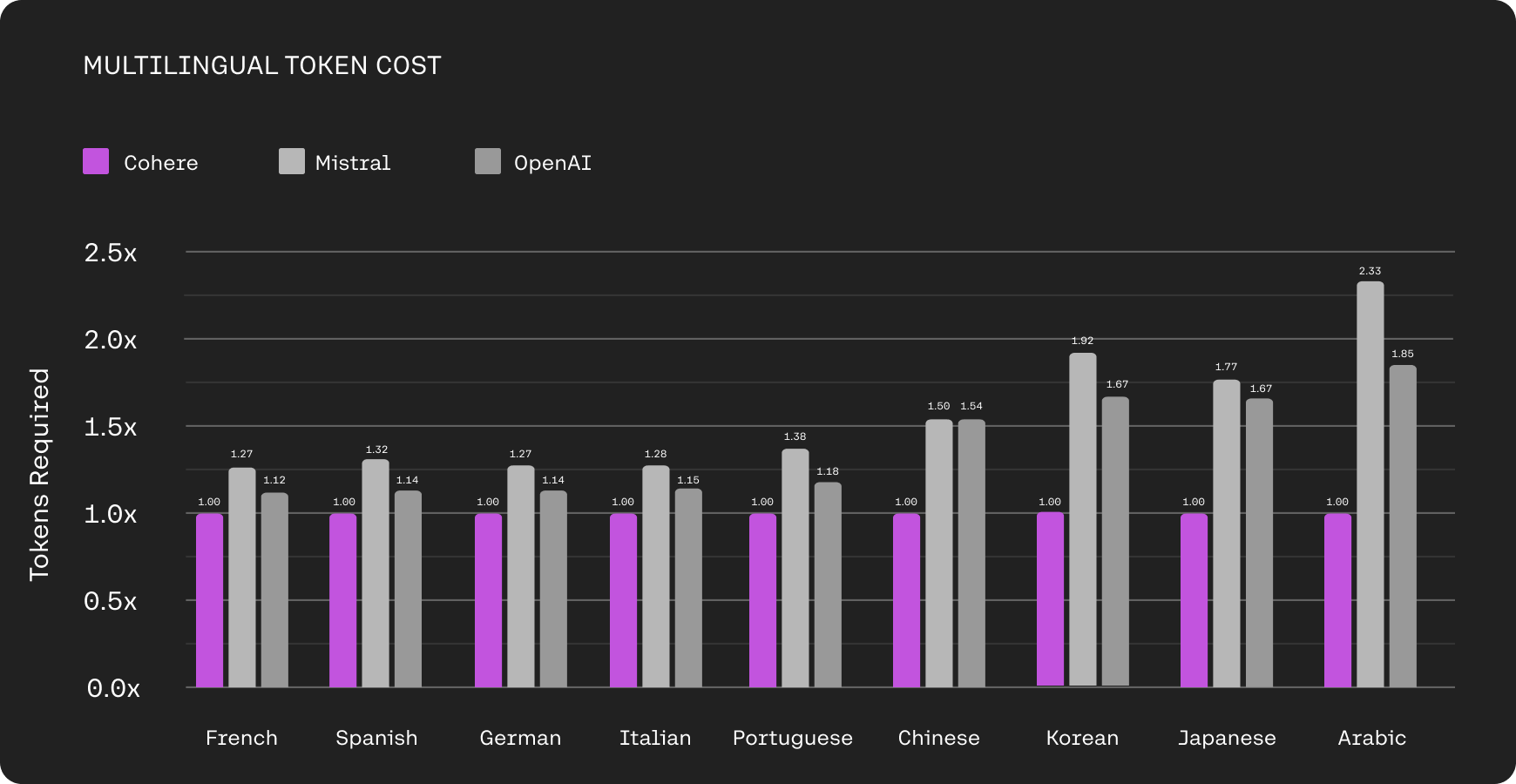
Comparison of the number of tokens produced by the Cohere, Mistral (Mixtral), and OpenAI tokenizers for different languages (as a multiple of the number of tokens produced by the Cohere tokenizer). The Cohere tokenizer produces much fewer tokens to represent the same text, with particularly large reductions on non-Latin script languages. For instance, in Japanese, the OpenAI tokenizer outputs 1.67x as many tokens as the Cohere tokenizer.
Availability & Pricing
Cohere works with all major cloud providers as well as on-prem for regulated industries and privacy-sensitive use cases, to make our models universally available.
To understand how your company can start deploying with Command R+ at production-scale, reach out to our sales team.
Our Commitment to Data Privacy and Security
With our Command R model family we remain committed to protecting customer data, privacy, and safety to help enterprises use our AI with peace of mind. We’ve always built products with data privacy at the core and provide customers additional protections with copyright assurance against infringement claims. We don’t access customers’ data unless they want us to. We offer private LLM deployments and the option to opt out of data sharing.
Source: Aidan Gomez, Cohere
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States