

May 8, 2024
StarTree Finds Apache Pinot the Right Vintage for IT Observability

(CoreDESIGN/Shutterstock)
Apache Pinot grew popular among companies like Uber for its capability to serve SQL queries to thousands of external users with sub-second latency. Now the commercial open-source vendor backing Pinot, StarTree, announced that it’s expanding the database into its first internal use case, analyzing observability data. StarTree also announced launch of an automated anomaly detection application called ThirdEye, and unveiled the addition of vector support in the open source project.
Apache Pinot is a distributed columnar database that was developed at LinkedIn in 2015 to serve the social media company’s vast appetite for real-time queries on data flowing through Apache Kafka, which it also created. The open-source product uses a variety of indexing techniques to enable it to process large amounts SQL queries against petabytes of data without doing full table scans, which are time-consuming and expensive.
“The whole principle of Pinot is to do the least work possible,” says Chinmay Soman, head of product at StarTree, which is based in Mountain View, California. “Many systems tend to scan a lot of data and then try to figure out how to scan faster or how to process all that data faster right. We don’t do that. Our philosophy is don’t scan at all for the queries that you need to run.”
Customers up to this point have used Pinot to solve some of their hardest big data challenges for external users. For instance, LinkedIn uses Pinot to serve canned queries, such as how many users have viewed your profile and how many impressions has your post garnered. Uber has several use cases for Pinot, including using Pinot to power dashboards for its UberEats operation.
External use cases are the hardest problem to solve because they entail serving data to millions of users with a sub-second query latencies, Soman says. “And the rewards are higher,” he says. “It grows your retention. The overall growth of the company depends on this.”
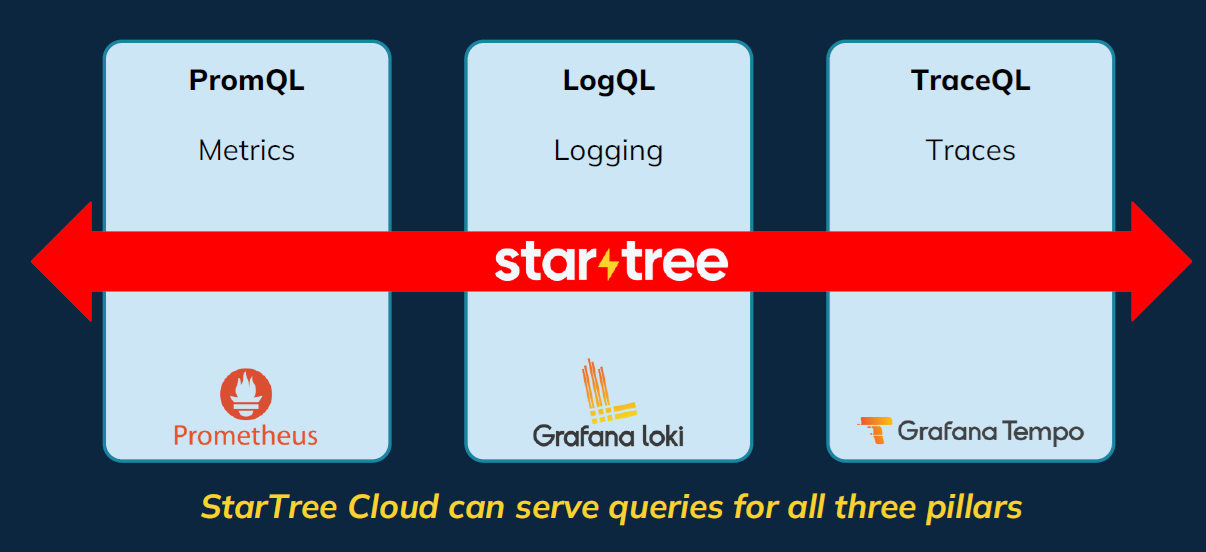
StarTree Cloud Observability covers the three types of observability data: Logs, metrics, and traces (Image courtesy StarTree)
At the urging of customers like Uber, which recently replaced a 1,000-node Elastic cluster with a 75-node Pinot system, StarTree is expanding its commercial Pinot offering, called StarTree Cloud, into internal real-time analytics use cases. The first internal use case is analyzing observability data, including logs, metrics, and traces.
StarTree Cloud Observability will bring several advantages over incumbent observability stacks, according to Soman. For instance, the Pinot-based offering will be open, enabling users to pick and choose what other components they want to use, such as BI tools and collection agents.
The new cloud offering will support OpenTelemetry, the emerging open standard for logs, metrics, and traces, as well as Prometheus for metrics, Grafana Loki for logs, and Grafana Tempo for traces. StarTree Cloud Observability also won’t bring any lock-in for observability data the way some vendors have built their solutions to do, Soman says.
“StarTree will become the storage and query layer in the stack and then companies are free to choose other their own components for the other rest of the stack,” he says. “The differentiator here is the core engine. StarTree is a distributed database which is easy to scale out. It’s super fast using all the various indexing technologies that we have. And it’s cost efficient, so we have a way to store historical data in deep cloud storage while still maintaining sub-second latencies.”
Uber and Cisco, another Pinot customer, have already adopted Pinot for observability use cases, and now regular StarTree Cloud customers can do observability too, says Peter Corless, StarTree director of product marketing. “We’re basically offering this as a service so that people don’t have to be able to be Cisco-sized to be able to do this,” he says.
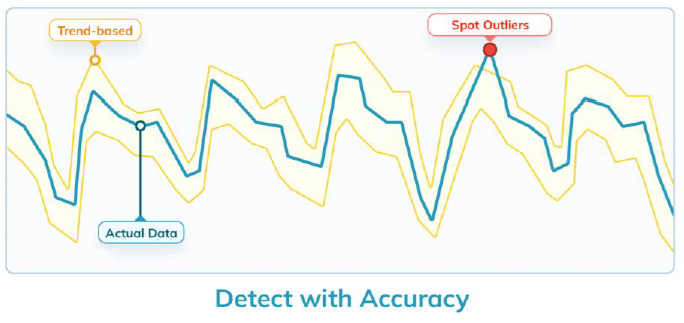
ThirdEye automatically detects anomalies and root-cause analysis (Image courtesy StarTree)
StarTree also announced the general availability of ThirdEye, an automated anomaly detection and root cause analysis tool designed specifically for business metrics.
ThirdEye leverages StarTree’s capability to partition time-series data and perform aggregate functions on that data, such as rollups. The software then uses machine learning techniques to detect patterns in the data that would probably escape the eyes of human analysts.
“Traditional solutions don’t work. They’re not capable of learning the historical pattern of data,” Soman says. “ThirdEye is able to learn that, to do a week-over-week or month-or-month analysis and then detect accurate outliers in your time-series data.”
Once ThirdEye detects an anomaly, it also performs an automated root-cause analysis that involves analyzing hundreds of dimensions associated with the metric to determine the likely cause of the anomaly.
“For example, for LinkedIn page views, dimensions could be geolocation or a type of device, Android or iOS. Or it could be a particular version of the software that’s running,” Soman says. “It’ll go through all of those and see which dimension caused this metric to go up or down.”![]()
StarTree also announced the private preview of StarTree Cloud Write API, a new “push” data integration system that will enable users to connect their Pinot cluster directly to ETL data pipelines managed by systems like Debezium, Fivetran, or dbt.
While Pinot was originally to work with an Apache Kafka message bus to “pull” data into the database, some customers didn’t want to hassle and expense of running a Kafka cluster, and so now they have other options, according to Soman.
StarTree is also launching a “free forever tier” for its StarTree Cloud, which gives customers an unlimited storage option for their cloud version of Pinot. While some customers are storing multiple petabytes of data in Pinot, that’s probably not a good option for the free forever tier, which does bring some usage restrictions.
Finally, StarTree announced that it’s adding vector storage and vector search capabilities to the open source Apache Pinot project. This will allow developers store vector embeddings in Pinot cluster and then be able to do similarity search queries directly within Pinot, Soman says.
“So essentially we are placing ourselves as a scalable vector DB,” he says. “You can build all kinds of GenAI applications. This will become one of the infrastructure pieces for building those applications.”
StarTree made these announcements amidst the Real-Time Analytics Summit, which it is hosting this week in San Jose. You can find more information about the event here.
Related Items:
Apache Pinot Uncorks Real-Time Data for Ad-Tech Firm
StarTree Keeps Real-Time Analytics Fresh with New Options for Pinot
StarTree Uncorks $47 Million for Pinot
Editor’s note: This article has been corrected. StarTree is based in Mountain View, not San Jose, California. Datanami regrets the error.
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States -
SC24
 November 17 - November 22
November 17 - November 22