

April 16, 2024
Vectara Spies RAG As Solution to LLM Fibs and Shannon Theorem Limitations

(issaro prakalung/Shutterstock)
Large language models (LLMs) hallucinate. There’s just no way around that, thanks to how they’re designed and fundamental limitations on data compression as expressed in the Shannon Information Theorem, says Vectara CEO Amr Awadallah. But there are ways around the LLM hallucination problem, including one by Vectara that uses retrieval-augmented generation (RAG), among other methods.
MIT professor Claude Shannon, who died in 2001, is known as the Father of Information Theory thanks to his extensive contributions to the fields of mathematics, computer science, electrical engineering, and cryptography. One of his observations, published in his seminal paper “A Mathematical Theory of Communication” (often called the “Magna Carta of the Information Age”) was there are inherent limits to how much data can be compressed before it begins to lose its meaning.
Awadallah explains:
“The Shannon Information Theorem proves without a doubt that the maximum you can compress text, the maximum, is 12.5%,” he says. “If you compress it beyond 12.5%, then you’re now in what’s called lossy compression zone, as opposed to lossless zone.”

MIT Professor Claude Shannon is known as the Father of Information Theory (Photo courtesy Tekniska Museet/Wikipedia)
The thing is, LLMs go way beyond that 12.5%, or compressing eight words into storage designed to fit one uncompressed word. That leads LLMs into the lossy compression zone and, thus, imperfect recall.
“In a nutshell, they hallucinate because we compress data too much when we stuff data inside of them,” Awadallah says.
Some of today’s LLMs take about one trillion words and stuff it into a space with a billion parameters, which represents a 1,000x compression rate, Awadallah says. Some of the biggest ones, such as GPT-4, do somewhat better and are compressing rates at about 100x, he says.
One simple method to reduce hallucinations is just cram less data into LLMs–effectively train the LLMs on smaller data sets–and get the compression rate above that 12.5% needed for text, Awadallah says.
But if we did that, the LLMs wouldn’t be as useful. That’s because we’re not training LLMs to have perfect recall of information, but to understand the underlying concepts reflected in the words, he says.
It’s a bit like educating a physicist, the Cloudera co-founder says. As a college student, the student is exposed to scientific formulas, but he isn’t drilled endlessly with rote memorization. The most important element of the physicist’s education is grasping the key concepts of the physical world. During tests, the physics student will have open-book access to scientific formulas because the physics teacher understands that a student may occasionally forget a formula even while demonstrating understanding of key physics concepts.
Having open book tests, as opposed to requiring perfect recall, is part of the solution to LLM hallucinations, Awadallah says. An open book test, as implemented with RAG techniques that bring additional data to the LLM, provides one check against an LLM’s tendency to make things up.
“RAG in a nutshell is about this open book thing,” he says. “We tell [the LLM] ‘Your job now is to answer this question, but only use these facts.’”
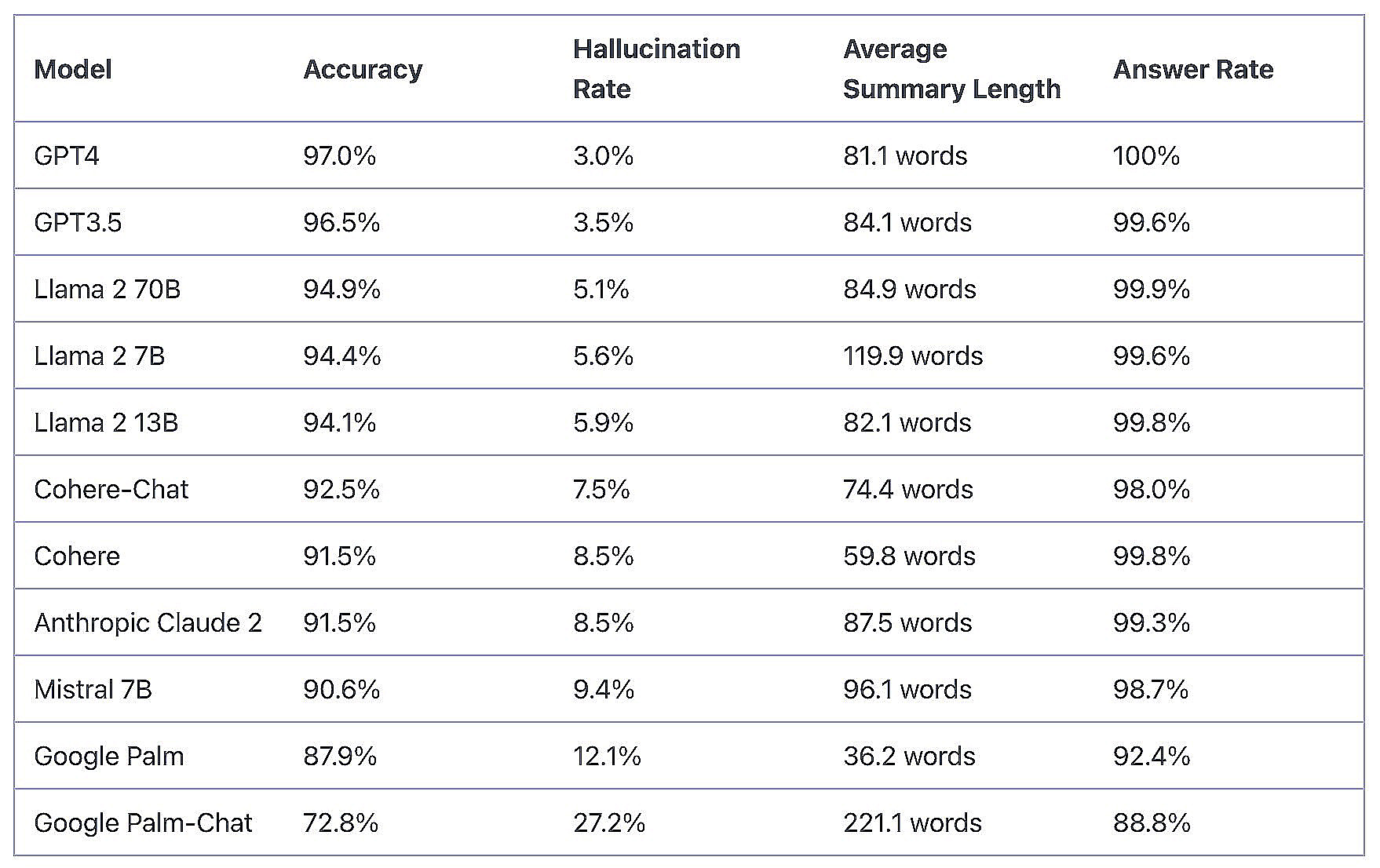
Vectara Hallucination Leaderboard (image courtesy Vectara)
The folks at Vectara hoped this “sandboxing” technique would be enough to bring the hallucination rate to zero. They soon learned that, while it reduced the hallucination rate somewhat, it didn’t entirely eliminate hallucinations. Using Vectara’s RAG solution, the hallucination rate for GPT-4, for example, dropped to 3%, which is better but still not sufficient for production. Llama-2 70B had a 5.1% hallucination rate, while Google Palm made stuff up about 12% of the time, according to Vectara’s Hallucination Leaderboard.
“They still can interject,” Awadallah says. “While all of these facts are correct, uncompressed, highly [relevant] facts, they can still make up something.”
Eliminating the remaining fib rate required another technique: the creation of a novel LLM designed specifically to detect hallucinations.
Like a human fact-checker, the Vectara LLM, dubbed Boomerang, generates a score that corresponds with the likelihood that an LLM’s answer is made up.
“It gives you a score that says ‘This response is 100% factual. It did not go beyond what the facts were’ versus ‘This response is a bit off. A human should read it’ versus ‘This response is completely bad, you should throw this away. This is completely a fabrication,’” Awadallah says.
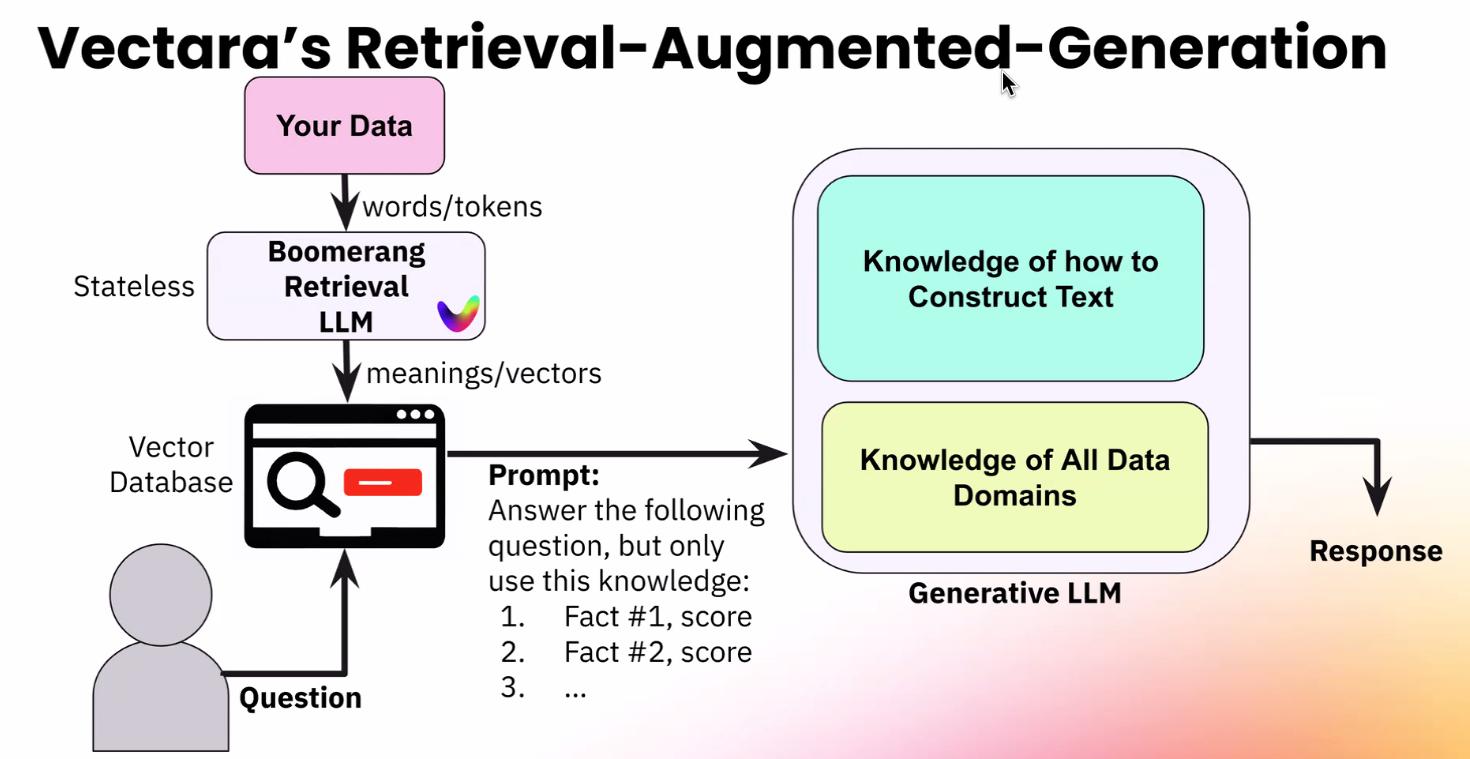
Vectara’s GenAI stack (Image courtesy Vectara)
One reason that Boomerang is better at fact checking than, say GPT-4 itself, is that it was designed specifically to be a fact-checking LLM. Another reason is that it’s trained on a company’s own data. The customer gets to define the facts that the model uses to determine truthfulness. This data is then stored in another compoent of Vectara’s solutoin: a homegrown vector database.
“What that vector database is doing is it’s storing your original content–the text you had–but it’s also storing the meanings behind the content” as vector embeddings, Awadallah says. “We’re very specialized for you in context, and what you have in an organization that runs a business.”
Vectra’s complete solution, which runs only in the cloud, includes Boomerang, its “RAG in a box,” and a vector database running next to an LLM. Any unstructured text, from Words docs and PDFs to paper-based files run through optical character recognition (OCR), can serve as input for training the model.
Vectara gives customers the choice of using either GPT-4 or Mistral 7B, running in the cloud as a managed service or in the customer’s own VPC. (The solutions are only available in the cloud; Awadallah got his fill of maintaining on-prem software with Cloudera).

Amr Awadallah is the CEO and founder of Vectara
Which LLM a customer chooses depends on what they’re trying to do, and their comfort level with sending data to OpenAI.
“Mistral 7B is of the best models in the world right now. It’s size is small so it’s really fast and it does really well on average,” he says. “We host that model ourselves for our customers. Or if they would like us to call out to GPT-4, we can call out to GPT-4 as well.” Meta’s Llama-2 will be added in the future, he says.
The goal for Vectara, which Awadallah founded in 2020 before the ChatGPT ignited the AI craze, is to enable companies to create their own chatbots and conversational interfaces. Awadallah acknowledges there are hundreds of startups and established tech firms chasing this information goldmine, but insists that Vectara has built a solution that addresses the hallucination concern–as well as other concerns such as defending against prompt injection attacks–in a way that puts the company ahead of the curve.
Since launching its GA product last April, Vectara has received 18,000 signups, a number that’s growing by 500 to 700 per week, Awadallah says. Among the companies that are using Vectara include an ultrasound manufacturer that wanted to automate machine configuration based on the distillation of expert best practices and a wealth advisory firm that wanted to provide non-hallucinated financial advice.
While the GenAI revolution is peeking executives’ interests, it’s also creating a headwind for companies like Vectara, Awadallah says.
“I think ChatGPT helped a lot, but it gives businesses a pause,” he says. “When they saw these hallucinations, they’re not sure they can use this. But now they’re coming back. They’re seeing the solution in the market like ours, they can truly keep that hallucination under control.”
Related Items:
What’s Holding Up the ROI for GenAI?
Why A Bad LLM Is Worse Than No LLM At All
Are We Underestimating GenAI’s Impact?
Applications:
Artificial Intelligence
Technologies:
Middleware
Sectors:
Financial Services
Vendors:
Vectara
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States