

March 18, 2024
Nvidia Looks to Accelerate GenAI Adoption with NIM

Today at the GPU Technology Conference, Nvidia launched a new offering aimed at helping customers quickly deploy their generative AI applications in a secure, stable, and scalable manner. Dubbed Nvidia Inference Microservice, or NIM, the new Nvidia AI Enterprise component bundles everything a user needs, including AI models and integration code, all running in a preconfigured Kubernetes Helm chart that can be deployed anywhere.
As companies move from testing large language models (LLM) to actually deploying them in a production setting, they’re running into a host of challenges, from sizing the hardware for inference workloads to integrating outside data as part of a retrieval augmented generation (RAG) workflow to performing prompt engineering using a tool like LlamaIndex or LangChain.
The goal with NIM is to reduce the amount of integration and development work companies must perform to bring all of these moving parts together into a deployable entity. This will let companies move their GenAI applications from the proof of concept (POC) stage to production, or “zero to inference in just a few minutes,” said Manuvir Das, the vice president of enterprise computing at Nvidia.
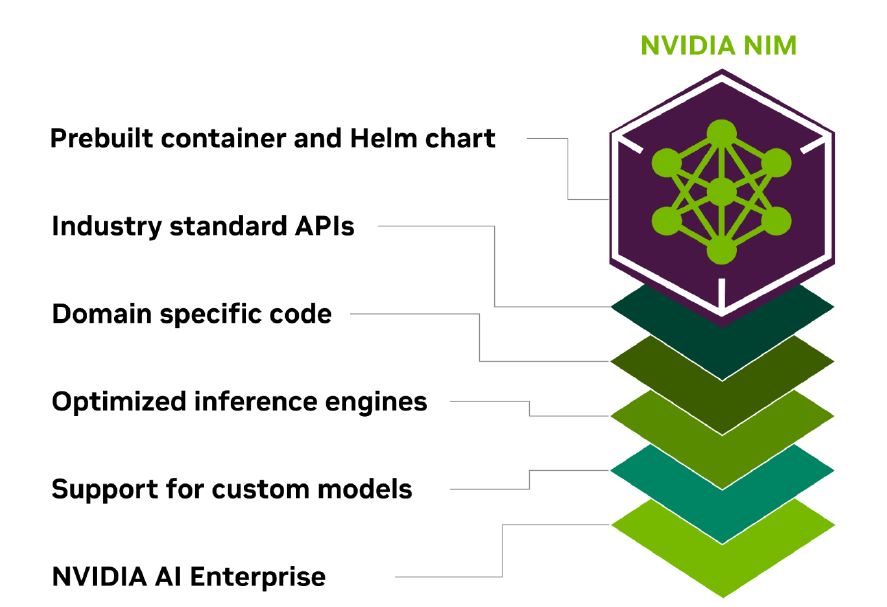
Nvidia NIM streamlines the deployment of GenAI apps (Image courtesy Nvidia)
“What this really does is it takes all of the software work that we’ve done over the last few years and puts it together in a package where we take a model and we put the model in a container as a microservice,” Das said during a press briefing last week. “We package it together with the optimized inference engines that we produce every night at Nvidia across a range of GPUs.”
Accessible from within the Enterprise AI software, NIM gives customers access to a range of proprietary and open source LLMs from providers like OpenAI, Meta, Mistral, Nvidia itself, and more. Nvidia engineers are constantly working to patch security issues and optimize performance of these models running across various Nvidia GPUs, from large H100s running in the cloud to smaller offerings like Jetson running on the edge. This work accrues to customers with a minimum of effort when they deploy a GenAI app using NIM.
“NIM leverages optimized inference engines for each model and hardware setup, providing the best possible latency and throughput on accelerated infrastructure,” Nvidia says in a blog post. “In addition to supporting optimized community models, developers can achieve even more accuracy and performance by aligning and fine-tuning models with proprietary data sources that never leave the boundaries of their data center.”
NIM leverages industry standard APIs and microservices, both to integrate the various components that make up a GenAI app (model, RAG, data, etc.) as well as to expose and integrate the final GenAI application with their business applications. When they’re ready to deploy the NIM, they have a choice of platforms to automatically deploy to.

Nvidia is aiming to accelerate AI deployment
It’s all about eliminating as much of the tedious integration and deployment work so customers can get their GenAI into operation as quickly as possible, Das said.
“We take the model and we package it together with the engines that are optimized for these models to run as efficiently as possible across the range of Nvidia GPUs that you can find in laptops or workstations in data centers and clouds,” Das said. “We put industry standard APIs on them so that they’re compatible with cloud endpoints like Open AI, for example. And then we put it into a container as a microservice so it can be deployed anywhere. You can deploy it on top of Kubernetes using Helm charts, you can deploy it just on legacy infrastructure without Kubernetes as a container.”
In the recent past, data scientists were needed to build and deploy these types of GenAI apps, Das said. But with NIM, any developer now has the ability to build things like chatbots and deploy them to their customers, he said.
“As a developer, you can access [AI models] through the API keys and then, best of all you can click the download and you can put them on the NIM and put it in a briefcase and take it with you,” Das continued. “You can procure Nvidia AI Enterprise. We made that very simple to do. And you’re off and running and you can go to production.”
NIM is a part of the new release of Nvidia AI Enterprise, version 5.0, whi ch is available now. In addition to NIM, 5.0 brings other new features, including better support in RAPIDS for some of the leading data analytic and machine learning frameworks, like Spark and Pandas.
ch is available now. In addition to NIM, 5.0 brings other new features, including better support in RAPIDS for some of the leading data analytic and machine learning frameworks, like Spark and Pandas.
Nvidia and Databricks have been partners for some time. With AI Enterprise 5.0, Nvidia is adding support for Photon, the optimized C++-based version of Spark developed by Databricks, enabling users to run Photon on GPUs.
“[W]e are working together with Databricks,” Das said. “They’re the leading Spark company. They’re the home of Spark, and with them we are accelerating their flagship data intelligence engine powered by Photon to run on GPUs. So you can have the best of both worlds. All of the innovation that Databricks has done making data processing run faster on Spark, and the world that we’ve done to accelerate GPU’s for Spark.”
The integration work Nvidia has done with pandas may reach an even bigger potential user base, as Das points out that there are 9.6 million pandas users. With the enhancements in cuDF, pandas workloads can now run on GPUs, Das said.
“What we’ve done is we’ve taken our RAPIDS libraries and we have now made them seamless so you can get the benefit of GPU acceleration–150 times faster for the common operations, which is join and group by, which is really behind most queries that you do, with zero code change,” Das said. “It’s a complete, seamless drop in replacement. You just replace one package with another. one line of code, and you’re off and running and you get this benefit.”
Nvidia AI Enterprise costs $4,500 per GPU per year. Customers can also use it in the cloud for $1 per GPU per hour.
Related Items:
Nvidia Bolsters RAPIDS Graph Analytics with NetworkX Expansion
NVIDIA CEO Jensen Huang to Deliver Keynote at GTC 2024
Nvidia CEO Calls for Sovereign AI Infrastructure
Applications:
Artificial Intelligence
Vendors:
NVIDIA
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States