

January 23, 2024
Data Engineering in 2024: Predictions For Data Lakes and The Serving Layer

(MeSSrro/Shutterstock)
The data landscape experienced significant changes in 2023, presenting new opportunities (and potential challenges) for data engineering teams.
I believe we will see the following this year in the areas of analytics, OLAP, data engineering, and the serving layer, empowering teams with better protocols and more choices amongst a sea of tools.
Data Lake Predictions
Moving on from Hadoop: In 2023, tools such as DuckDB (C++), Polars (Rust) and Apache Arrow (Go, Rust, Javascript, …) became very popular, starting to show cracks in the complete dominance of the JVM and C/Python in the analytics space.
I believe the pace of innovation outside the JVM will accelerate, sending the existing Hadoop-based architectures into the legacy drawer.
While most companies already aren’t using Hadoop directly, much of the current state of the art is still built on Hadoop’s scaffolding: Apache Spark completely relies on Hadoop’s I/O implementation to access its underlying data. Many lakehouse architectures are based either on Apache Hive-style tables, or even more directly, on the Hive Metastore and its interface to create a tabular abstraction on top of its storage layer.

Source: XKCD, under Creative Commons Attribution-NonCommercial 2.5 License.
Slightly modified by Oz Katz. Cloudera’s logo is trademarked to Cloudera Inc.
While Hadoop and Hive aren’t inherently bad, they no longer represent the state of the art. For once, they are completely based on the JVM, which is incredibly performant nowadays, but still not the best choice if you’re looking to get the absolute best out of CPUs that are simply not getting any faster.
Additionally, Apache Hive, which marked a huge step forward in big data processing by abstracting away the underlying distributed nature of Hadoop and exposing a familiar SQL(-ish) table abstraction on top of a distributed file system, is starting to show its age and limitations: lack of transactionality and concurrency control, lack of separation between metadata and data, and other lessons we’ve learned over the 15+ years of its existence.
I believe this year we’ll see Apache Spark moving on from these roots: Databricks already has a JVM-free implementation of Apache Spark (Photon), while new table formats such as Apache Iceberg are also stepping away from our collective Hive roots by implementing an open specification for table catalogs, as well as providing a more modern approach to the I/O layer.
Battle of the Meta-Stores
With Hive slowly but steadily becoming a thing of the past and Open Table formats such as Delta Lake and Iceberg becoming ubiquitous, a central component in any data architecture is also being displaced – the “meta-store”. That layer of indirection between files on an object store or filesystem – and the tables and entities that they represent.
While the table formats are open, it seems that their meta-stores are growing increasingly proprietary and locked down.
Databricks is aggressively pushing users to its Unity Catalog, AWS has Glue, and Snowflake has its own catalog implementation, too. These are not interoperable, and in many ways become a means of vendor lock-in for users looking to leverage the openness afforded by the new table formats. I believe that at some point, the pendulum will swing back – as users will push towards more standardization and flexibility.
Big Data Engineering as a Practice Will Mature
As analytics and data engineering become more prevalent, the mass body of collective knowledge is growing and best practices are beginning to emerge.

Data mesh and data producds will emerge in 2024, the author predicts (Chombosan/Shutterstock)
In 2023 we saw tools that promote a structured dev-test-release approach to data engineering becoming more mainstream. dbt is vastly popular and established. Observability and monitoring are now also seen as more than just nice-to-haves, judging by the success of tools such as Great Expectations, Monte Carlo, and other quality and observability platforms. lakeFS advocates for versioning of the data itself to allow git-like branching and merging, allowing to build robust, repeatable dev-test-release pipelines.
Additionally, we are also now seeing patterns such as the Data Mesh and Data Products being promoted by everyone, from Snowflake and Databricks to startups popping up to fill the gap in tooling that still exists around these patterns.
I believe we’ll see a surge of tools that aim to help us achieve these goals in 2024. From data-centric monitoring and logging to testing harnesses and better CI/CD options – there’s a lot of catching up to do with software engineering practices, and this is the right time to close these gaps.
The Serving Layer Predictions
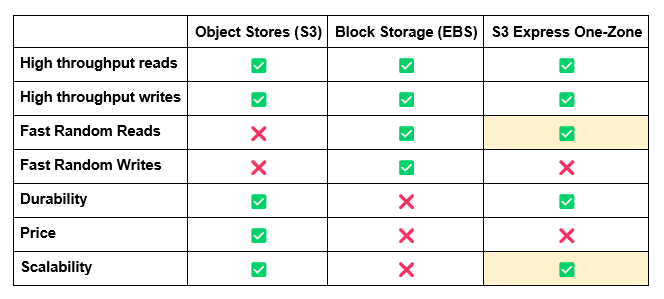
Cloud native applications will move a larger share of their state to object storage: At the end of 2023, AWS announced one of the biggest features since its inception in 2006 coming to S3, its core storage service.
That feature, “S3 Express One-Zone,” allows users to use the same* standard object store API as provided by S3, but with a consistent single-digit millisecond latency to access data. At roughly half the cost for API calls.
This marks a dramatic change. Until now, the use cases for object storage were somewhat narrow: while they allow storing pretty much infinite amounts of data, you’d have to settle with longer access times, even if you’re only looking to read small amounts of data.
This trade-off obviously made them very popular for analytics and big data processing, where latency is often less important than overall throughput, but it meant that low latency systems such as databases, HPC and user-facing applications couldn’t really rely on them as part of their critical path.
If they made any use of the object store, it would typically be in the form of an archival or backup storage tier. If you want fast access, you have to opt for a block device, attached to your instance in some form, and forgo the benefits of scalability and durability that object stores provide.
I believe S3 Express One-Zone is the first step toward changing that.
With consistent, low latency reads, it is now theoretically possible to build fully object-store-backed databases that don’t rely on block storage at all. S3 is the new disk drive.
With that in mind, I predict that in 2024 we will see more operational databases starting to adopt that concept in practice: allowing databases to run on completely ephemeral compute environments, relying solely on the object store for persistence.
(Image source: Oz Katz)
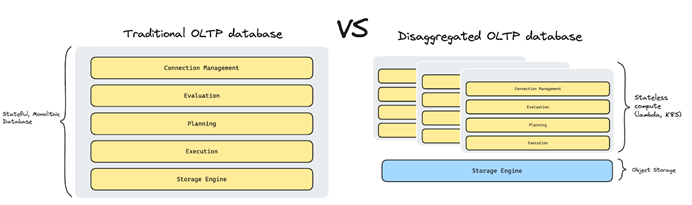
Operational Databases Will Begin to Disaggregate
With the previous prediction in mind, we can take this approach a step further: what if we standardized the storage layer for OLTP the same way we standardized it for OLAP?
One of the biggest promises of the Data Lake is the ability to separate storage and compute, so that data being written by one technology could be read by another.
This gives developers the freedom to choose the best-of-breed stack that best fits their use case. It took us a while to get there, but with technologies such as Apache Parquet, Delta Lake, and Apache Iceberg, this is now doable.
What if we manage to standardize the formats used for operational data access as well? Let’s imagine a key/value abstraction (perhaps similar to LSM sstables?) that allows storing sorted key value pairs, optimally laid out for object storage.
We can deploy a stateless RDBMS to provide query parsing/planning/execution capabilities on top, even as an on-demand lambda function. Another system might use that same storage abstraction to store an inverted index for search, or a vector similarity index for a cool generative AI application.
While I don’t believe a year from now we’ll be running all our databases as lambda functions, I do think we will see a shift from “object stores as an archive tier”, to more “object store as the system of record” happening in operational databases as well.
(Image source: Oz Katz)
Final Thoughts
I’m optimistic that 2024 will continue to evolve the data landscape in mostly the right directions: better abstractions, improved interfaces between different parts of the stack, and new capabilities unlocked by technological evolution.
Yes, it won’t always be perfect, and ease of use will be traded off for less flexibility, but having seen this ecosystem grow over the last two decades, I think we’re in better shape than we’ve ever been.
We have more choice, better protocols and tools – and a lower barrier of entry than ever before. And I don’t think that is likely to change.
About the author: Oz Katz is the co-founder and CTO of Treeverse, the company behind open source lakeFS, which provides version control for data lakes using Git-like operations.
control for data lakes using Git-like operations.
Related Items:
2024 and the Danger of the Logarithmic AI Wave
Data Management Predictions for 2024
Fourteen Big Data Predictions for 2024
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States