

January 3, 2024
Postgres Rolls Into 2024 with Massive Momentum. Can It Keep It Up?

(monticello/Shutterstock)
If you deployed a new database in 2023, chances are good that it was Postgres or one of Postgres’ many derivatives for analytics and transactional workloads. There’s no denying the huge popularity of the database, which Michael Stonebraker started developing as a successor to Ingres more than 35 years ago. But can the good times last? The latest release, Postgres version 16, provides some clues.
Instead of a midlife crisis, Postgres currently is experiencing a midlife renaissance. At an age when most technologies have been given the dreaded “legacy” tag that signals something to be moved away from, organizations instead are gravitating to Postgres, which has discovered new life as the data-serving backbone for thousands of new applications.
The open source database had quite a year in 2023. It emerged as the number one database in Stack Overflow’s 2023 Developer Survey, besting database stalwarts MySQL, SQL Server, and MongoDB. More than 70% of the 76,000-plus developers who took the survey said they used Postgres, which is mind blowing when you think about it.
Tuesday, DB-Engines.com named Postgres (also called PostgreSQL) as the DBMS of the year for 2023, beating out Databricks and Google Cloud’s BigQuery. It was the fourth time winning the honor from DB-Engines, which uses a number of methods to track the popularity of various databases, and the first victory since 2020 (Snowflake went back-to-back in 2021 and 2022).
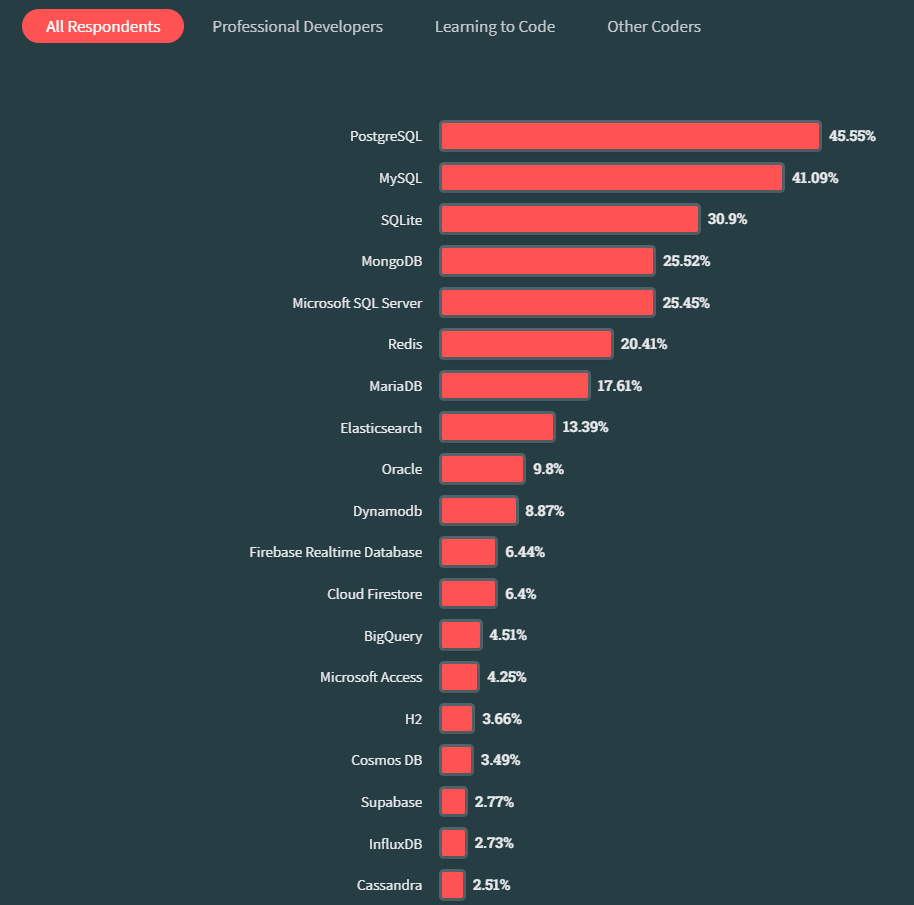
Postgres was the top database in Stack Overflow’s 2023 Developer survey
Why is Postgres so popular now, after so many years of mediocre uptake? By all accounts, there are multiple reasons for the popularity.
DB-Engines.com attributes Postgres’ long winning streak to “high pace of steady improvements…that keep the system at the forefront of DBMS technology, while providing a reliable and stable platform at the same time.” It added that Postgres is “one of the most successful open source projects ever.” To that list, one might add a history of stability, adherence to standards, extensibility, broad support for data types, and price tag (it’s free).
Adoption by cloud giants has also played a big role in Postgres’ sudden popularity. Amazon Web Services, Microsoft Azure, and Google Cloud have each rolled out hosted Postgres services that reduce the time and expense of implementing and running a database. In fact, back in 2021, AWS said that Amazon Aurora, its Postgres-compatible database service, was its fastest growing service ever.
Another factor was the acquisition of rival database MySQL by Oracle. That event drove many would-be open source database users away from MySQL and into the Postgres camp, Stonebaker said in a recent interview.
So what does the future hold for Postgres? Can the database maintain the popularity of the last few years amid ferocious competition? The Postgres community is betting on the recent release of version 16 to help the database maintain the high level of adoption in 2024 and the years to come.
Postgres 16 for Big Data
The new database, which was made generally available in October 2023, features a number of new features aimed at helping analytics as well as transactional workloads, according to Charly Batista, the PostgreSQL tech lead at Percona, which sells tech support and maintenance plans to Postgres users.
One of the big sources of performance enhancements in V16 comes from the vacuum process. Postgres uses the vacuum to clean up old records that have been marked for deletion. When updating a database file, Postgres saves a copy of the old record, and marks it for deletion, which occurs when the vacuum process runs.
The problem is that the vacuum process was computationally expensive, and required a freeze of the entire table being cleaned up. With v16, the performance of the vacuum process has been improved, eliminating the need for full-table freezes, Batista said.

Postgres 16 supports CPU acceleration using SIMD in both x86 and ARM architectures (emp-64GTX/Shutterstock)
Sharding has also been improved, which is important for storing large data sets. The Postgres community has been working on sharding for the past three or four releases, Batista said. And while v16 doesn’t mark a huge improvement in that category, it does bring some enhancements, he said.
“It’s now a lot easier to do sharding with Postgres,” he said. “Those improvements, they help. If you ask me, if Postgres would be the best choice for big data, I will tell you the answer that everybody hates: It highly depends.”
While it can shard data across multiple nodes, Postgres isn’t a fully distributed database. Postgres users that need a fully distributed database should probably look to something like CockroachDB or Yugabyte, which are distributed database that are wire-compatible with Postgres.
With that said, Postgres does support parallelized operations. With version 16, the Postgres query planner now supports the parallelized execution of FULL and RIGHT JOINs, which will be beneficial for running complicated aggregation and windowing queries.
Version 16 also brings several new logical replication capabilities that will improve how users architect their database workloads. For example, it now supports bidirectional replication, which allows data to be replicated from multiple tables simultaneously. Users can also now apply large transactions using parallel workers.
Another replication features Postgres brings is support for cascading replication. In previous releases, it was only feasible to replicate data from the primary, Batista said.

New parallelization capabilities will help Postgres process analytic queries faster (MZinchenko/Shutterstock)
“If you wanted to have a cascading replication…let’s say from a primary to a replica and another replica…it was not possible,” he said. “On v16, they made it possible, so you’re not overloading your primary too much anymore.”
The sprawling Postgres community also delivered improvements for bulk loading, using the COPY command for both single and concurrent operations. According to the Postgres community, tests show up to a 300% performance improvement using the new bulk load command.
Postgres 16 also supports CPU acceleration using SIMD in both x86 and ARM architectures, the group adds, “resulting in performance gains when processing ASCII and JSON strings, and performing array and subtransaction searches.”
Postgres 16 also starts to lay the groundwork for supporting direct I/O, whereby the data path bypasses the operating system, providing a big speedup, said Batista, who is active in the Postgres community.
“Postgres has a huge overhead when you’re writing a data point,” he said. “If you bypass the operational system with direct I/O, that’s something huge. So that can give a lot for performance and give a lot of freedom to developer.”
Postgres doesn’t yet support direct I/O, as MySQL does. But Postgres users can utilize extensions, such as PG-Strom, to accelerate workloads using GPUs and SSDs, Batista pointed out.
Related Items:
Microsoft Benchmarks Distributed PostgreSQL DBs
Google Cloud Launches New Postgres-Compatible Database, AlloyDB
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States