

December 15, 2023
What’s the Vector, Victor?

(Titima-Ongkantong/Shutterstock)
Depending on your age, and perhaps your sense of humor, you may get that reference from the movie “Airplane.” Regardless, it’s quite likely you’ve seen the topic of vector databases mentioned thanks, in part, to the explosion of Large Language Models (LLMs). The increasing buzz around vector databases in recent months has led to many questions, including: What are they? How do they compare to knowledge graph databases? Why, and when, should one be used one over the other?
Both are valuable tools in the world of data management and analysis, but serve different purposes and excel in different scenarios. While both are powerful databases designed to store and query data more efficiently and flexibly than relational databases, deciding which one to use–or when to use both–requires an understanding of what the business is hoping to accomplish.
Knowledge Graphs vs. Vector DBs: Similarities and Differences
To help understand both the technology and the business impact, it’s important to understand what each of them do.
Starting with the similarities, both are designed to represent and manage the complex structured and unstructured data critical to support the growing need for deeper analytics, and for breaking down data silos. Each can store and query complicated data, such as graphs and networks, making them useful for a number of applications. They can also be used to implement a variety of machine learning and artificial intelligence applications, such as ecommerce, text analytics, recommender systems, search engines, NLP, and many others.
However, all of these initiatives require a significant amount of data as well as being able to connect those systems to ensure collaboration. With a recent report saying that 86% of companies are dealing with data silos, bringing all this data together has become even more critical to ensure business objectives.
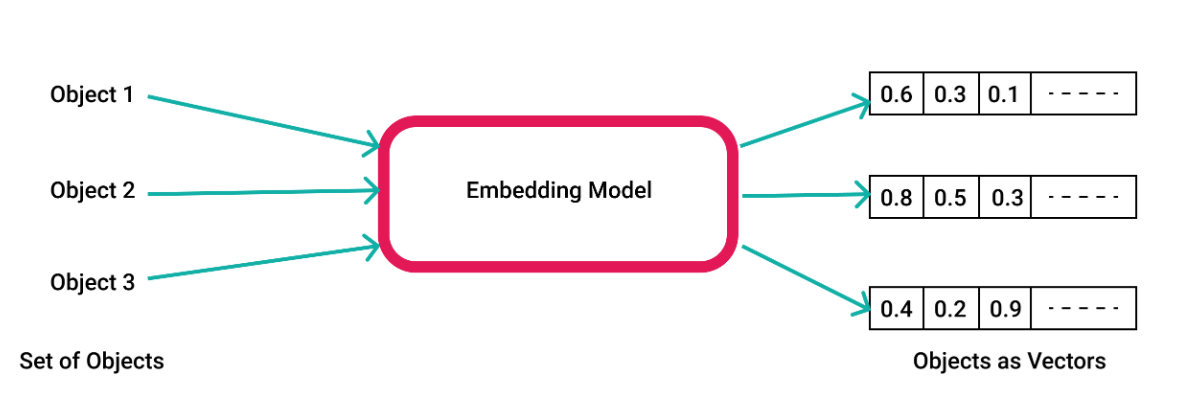
Vector embeddings are numerical representations of an object (Image courtesy Pinecone)
Where they differ from each other is as much about functionality and capabilities as it is about what a business needs from their data. Vector databases are well optimized for applications such as image retrieval, natural language processing, recommendation systems, and retrieval augmented generation. For example, they can store and search image and word embeddings (known as high-dimensional vectors) that represent the visual features of an image and the semantics of a word, respectively. The first allows quick and efficient searching of similar images in a large dataset where natural language processing activities such as sentiment analysis and text summarization are driven by word embeddings.
To put this conceptually, imagine a company with a large selection of products which requires them to have the ability to find any item quickly and easily, no matter what they are looking for. Acting like a giant search engine, a vector database can help the business find similar products, even if they are not categorized in the same way. For example, if looking for an aluminum ladder, a vector database could support locating all of the aluminum ladders offered, even if they are different brands, sizes, or styles. That same vector database could help query all the images of aluminum ladders and get a summary of the related text or descriptions for each. They are also gaining a lot of traction when LLMs need to be used for private data and/or to reduce hallucinations. This use of vector databases is known as Retrieval Augmented Generation (RAG).
Knowledge graph databases differ in many ways, including being optimized for querying complex relationships between pieces of data and semantic meanings between entities. They represent data as entities (nodes) and their relationships (edges). Knowledge graphs excel at modeling complex, interconnected data, such as semantic relationships between concepts, entities, and their attributes. They’re also great for representing intricate relationships between pieces of data, almost like connecting the dots in an information system’s puzzle. Think of them as developing an interconnected web of information, where relationships between things are core to the access, sharing, and use of the data. When enhanced using semantic standards, organizations gain a common, shared data language across their various systems.

Knowledge graphs allow users to query complex relationships between pieces of data (Image courtesy Ontotext)
Knowledge graph databases are like multi-dimensional maps of the example mentioned earlier. They show the relationships between different products and can help provide connections that an individual may not be aware of. Here, the knowledge graph database could be used to power question answering systems using natural language. In this way, a user could ask how an aluminum ladder is related to other aluminum construction related items, such as gutters, siding, paint, heating and cooling ducts, etc. Thanks in part to its inferencing capability, a knowledge graph could also present items such as cosmetics, cellphones and even rubies and sapphires that utilize aluminum. From a practical sense, this could enable a user to ask for all instances of items using aluminum that might be included in a typical building, using a knowledge graph powered Building Information Management system.
Because of the reasoning capability in knowledge graph databases, using the Resource Description Format (RDF), inferences can be identified using AI. Once complete, that emergent knowledge can then be used to discover new insights and patterns that would be difficult or impossible to find using traditional methods, sometimes referred to as the “unknown unknowns.” This makes them well-suited for solutions such as knowledge organization and discovery, semantic search, and advanced, multi-level queries and question answering. When the goal is to understand how different pieces of information relate to each other, such as building sophisticated recommendation systems where relationships are important, analyzing networks, or organizing structured knowledge, RDF is a solid choice. This is because they emphasize modeling relationships, entities and their attributes in a graph structure, allowing for rich semantic representation.
So Victor, What’ll It Be?
When deciding which type of database is better for your business, it comes down to what needs to be done with the data. If the business needs to be able to find similar products quickly and easily, then a vector database may be the best choice. If additional analytic power is required to do things such as uncovering and understanding the relationships between different products, then a knowledge graph database would create the right foundation for the organization’s data and business strategy.
Vector databases are more suitable for tasks involving similarity and machine learning, while knowledge graph databases excel in modeling and querying interconnected, complex, semantically rich data. Knowledge graph databases work great for applications that need to represent and reason about knowledge in a domain-specific context, such as healthcare, finance, and customer relationship management (CRM) applications.
Deciding between the two ultimately depends on what you want to achieve. The key is to create a clear, enterprise wide data strategy, and keep semantics in mind, as this will ensure clarity of language, promote sharing, and properly enable the businesses to deliver the optimal results from their data.
About the author: Doug Kimball is CMO of Ontotext, the leading global provider of enterprise knowledge graph (EKG) technology, and semantic database engines. To learn more visit the company or follow on LinkedIn or Twitter.
Related Items:
Retool’s State of AI Report Highlights the Rise of Vector Databases
Vector Databases Emerge to Fill Critical Role in AI
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States