

July 8, 2020
Is Zero Closer to Eight or to One?
Is zero closer to eight or to one? Is this a three or a five? This was the type of question we were pondering a few weeks ago when we examined the results of an image classification application.
Yes, indeed, a zero is closer to an eight than to a one and a two is closer to a five than to a three — of course, from an image recognition point of view rather than in a strictly mathematical sense. In the last data science example that we were preparing, we trained a machine learning model to recognize images of hand-written digits. In the end, while checking the results, we realized how sloppy people’s handwriting is and how hard it is sometimes to distinguish an eight from a zero, a two from a five, a one from a seven, a zero from a three, and other, sometimes unexpected, similar digits.
For obvious reasons involving time and other obligations, we could not go through all digit images and their misclassifications, one by one. Nevertheless, it would have been interesting to have had an overview of the most confusable overlapping digits in the dataset. That is easier said than done. Each data row is an image, described through 784 input features. Try to visualize that!
We needed a massive reduction of the input dimensionality from 784 to two or maximum three so that data visualization via a 2D or a 3D plot becomes possible and yet also still informative. It would be great indeed if we could understand from a plot or a chart where the biggest confusion lies and which digits have the largest stretch in handwriting styles.
t-distributed Stochastic Neighbor Embedding (t-SNE)

Figure 1. Example of visualization after the application of the t-SNE projection
In the first step, the data points are modeled through a multivariate normal distribution of the numeric attributes. A probability distribution is created for pairs of objects in the high-dimensional space. Similar objects have a high probability of being picked together while dissimilar objects have a low probability.t-distributed Stochastic Neighbor Embedding (t-SNE) is a relatively recent technique, often used to graphically represent a complex and multidimensional dataset on a two- or three-dimensional space. t-SNE is a nonlinear dimensionality reduction technique that transforms the original n coordinates of a dataset into a new set of m=2-3 coordinates, based on nonlinear local relationships among the data points. Specifically, it models each high-dimensional object as a two- or three-dimensional point, in such a way that similar objects are modeled by nearby points and dissimilar objects are modeled by distant points in the new lower dimensional space.
In the second step, this distribution is replaced by a t-distribution in a lower dimensional space, which must follow the original multivariate normal distribution as closely as possible. The goal of this second step is to find the low-dimensional space with as similar a t-distribution as possible — by minimizing the Kullback-Leibler divergence — and then to project the objects in the newly found low-dimensional space. This second t-distribution must model the probability of picking another point in the dataset as a neighbor to the current point in the lower dimensional space, as it was in the high-dimensional space.
The perplexity parameter controls the shape of the t-distribution as the “effective number of neighbors for any point.” A low perplexity value (~2) finds cluster shapes that are dominated by local variations in the data. A higher perplexity value (~30) leads to more stable clusters over multiple iterations. That is, the greater the value of the perplexity, the more global structure is considered in the data.
This technique is primarily used for visualization. Indeed, the aggressive reduction of the dataset dimensionality to just two or three coordinates, the transformation of the likelihood of pairs of data points into a visual neighborhood property, and the capability to represent strange shapes of the data groups thanks to the nonlinearity of the projection make the t-SNE particularly suitable for most data visualization techniques.
Notice that the t-SNE technique works only for the current dataset. It is not possible to export the model and apply it to new data. Indeed, all available data have to be used to find the new low-dimensional space. That is, new data can’t be projected.
The MNIST Digits Dataset
Often when working with images, it is possible to read them directly from

Figure 2. A few digit images from the MNIST digit dataset
standard formats like PNG, JPG and TIFF. Unfortunately for us, the MNIST dataset is only available in a non-standard binary format. Luckily, it is straightforward to download the dataset and convert the files to a CSV format that can then be easily read. I described this in the “Learning Deep Learning” blog post.The MNIST database of handwritten digits — hosted on the LeCun website — contains 70,000 examples of 28×28 B/W images of handwritten digits (according to LeCun, et al’s “Gradient-based learning applied to document recognition” in the Proceedings of the IEEE). We used a subset of 10,000 such images for this example.
After converting the digit images into numerical vectors, each image was represented by a vector of 784 levels of grey, that is by 784 input features.
Applying t-SNE to Visualize the MNIST Dataset in a 2D Plot
On one side, we have a high-dimensional dataset we would like to visualize on a 2D scatter plot; on the other side, a technique to reduce the dimensionality from a high n to a low m (m=2 for example). We then applied the t-SNE transformation to the MNIST dataset and plotted the results on a 2D scatter plot (Fig. 3).
This is an example of how the t-SNE transformation can help visualize high-dimensional datasets on a two-dimensional plot. The original dimensions 28×28=784 pixels of each image were reduced to two dimensions only with t-SNE, and the resulting data points were plotted on a scatter plot, where data points representing similar images are closely located. 784 input features come from an image 28×28 pixels “unrolled” into a single array or sequence of values.
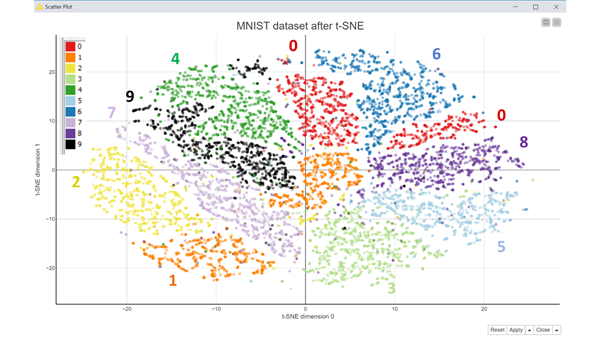
Figure 3. The MNIST dataset on a scatter plot after t-SNE transformation.
The “6” for example are located in between two different types of “0.” Digits “4” and “9” are close and partially overlapping in shape, stretching into shapes similar to “1.” “0” and “8” digits are also closely located since they are often similar in shape; same for “3” and “5.” So, the scatter plot in Figure 3 is a topological map of the different shapes of every digit.
Now let’s have a quick look at the workflow implementing the t-SNE transformation on the MNIST dataset and plotting the results on a 2D scatter plot, available on the KNIME Hub as “t-SNE on MNIST dataset.”
The Workflow
The metanode named “Read MNIST data” lists and reads 10,000 MNIST files, each one containing an image of a handwritten digit. Images are then converted into a collection of numbers (the levels of gray) via the “Image to DataRow” node in the “Pre-process images” metanode. The numerical vectors are then fed into the “t-SNE (L. Jonsson)” node to calculate the two t-SNE components. In the parallel branch, the digit classes are extracted and used to color-code the different digit images.

Figure 5. The workflow “t-SNE on MNIST dataset” implementing the t-SNE transformation of the MNIST digit data and plotting the results on a scatter plot.
Finally, the color-coded t-SNE transformed bi-dimensional vectors are plotted on a classic traditional scatter plot using the “Scatter Plot (Plotly)” node.
Conclusions
t-SNE is a really powerful transformation to project data from whatever dimensional space into a two-dimensional space and to display how close the data groups in the dataset are.
In this example, we have transformed the MNIST digit dataset from a 784-dimensional space into a two-dimensional space, and yet we could still inspect which digits where the most easily confused with other digits, like “8” with “0” or “7” with “1.”
Bottomline, one node alone implements the t-SNE transformation, and it is quite straightforward to use. In fact, in this example, most of the data preparation consisted of reading image files and converting them into numerical vectors, while the t-SNE transformation itself was handled by that one node alone.
About the author: Rosaria Silipo, Ph.D., principal data scientist at KNIME, is the author of 50+ technical publications, including her most recent book “Practicing Data Science: A Collection of Case Studies.” She holds a doctorate degree in bioengineering and has spent more than 25 years working on data science projects for companies in a broad range of fields, including IoT, customer intelligence, the financial industry, and cybersecurity. Follow Rosaria on Twitter and LinkedIn.
Mischa Lisovyi, Ph.D., is a data scientist in the customer care team at KNIME. He has an academic background in particle physics — the scientific field in which data is so big that processing has to be distributed around the globe. Analysis of data is his passion, and his range of experience spans from identification of the hardest elementary particles in the known universe through assessing poverty levels in Costa Rica to adding an artistic touch to selfies of KNIMEers. Follow Mischa on LinkedIn.
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States