

August 26, 2013
Reducing Suicide Rates with Predictive Analytics
In 1897 French sociologist Émile Durkheim published his seminal monograph Le Suicide, a study of suicide rates in Catholic and Protestant populations. An important point he raised was that it should be possible to analyze the writings of patients to gain insight into whether they have suicidal tendencies.
 So why does this matter, and what has it got to do with big data? There are three things most people probably don’t know about suicides:
So why does this matter, and what has it got to do with big data? There are three things most people probably don’t know about suicides:
- In the US military, there are more deaths from suicides than combat.
- Suicide rates have been increasing steadily, especially in the military.
- Early intervention is critical, but usually the first sign of real trouble occurs too late.
And that means it’s both important and hard for military physicians to know who’s got the highest suicide risk. Which is why DARPA funded a project (appropriately named “The Durkheim Project”) to see if it was possible, by analyzing social media, to accurately predict suicide risk among military personnel. This was led by Chris Poulin at Patterns and Predictions, along with other partners including the U.S. Department of Veterans Affairs (VERRANE), The Geisel School of Medicine at Dartmouth, and my firm Scale Unlimited.
The Durkheim Project uses predictive analytics to calculate a person’s suicide risk level using both demographics and what they’ve said or written as the key signals or features. The results are displayed via a Clinician Dashboard that shows the estimated risk rating (green, yellow, red) and a confidence level (probability), along with details on what keywords contributed to the results.
Predictive Analytics
So what is the predictive analytics? If you take text that people write, and you do some natural language processing on it to break it up into terms, then you can build statistical models that try and predict things from that text. Most people intuitively sense that “there are very few people in the world that know the real me,” is something most teenagers might utter at some point, whereas “when I lay down to go to sleep, all I do is stare at the blackness” is a red flag.
The challenge is how to train a computer to discriminate between these two types of text. This is a classic machine learning problem, and the key is that you need labeled training data, with sets of data from people who didn’t try to commit suicide and people who did. From this you can generate a predictive analytics model which, when given unlabeled data, will assign it a label and a probability.
Scaling Out
The training of models is something that doesn’t typically have scaling issues – the amount of labeled training data is usually small enough to be processed on a single server in a reasonable amount of time. In this regard The Durkheim Project was a bit unusual; the cohesive semantic models are actually so large that they’d benefit from more memory than is available on a single server, but that’s not typical.
The primary big data challenges come from having lots of text. In Émile Durheim’s time the majority of this would be based on transcriptions of patient sessions, so it would clearly be “small data”. But with the advent of social media we’ve got a lot of text to analyze from tweets and posts, and this has to be stored and analyzed.
Fundamentally the question is if you had a billion pieces of text, where would you put them? For a system that continuously monitors social media and just saves the results away, you could write that out to a (really big) file. But what happens when you want to access that data (typically by one user) or if you need to take sets of data and run them through a workflow? Just storing it in a file that you shove somewhere isn’t going to work.
This is the part where we (Scale Unlimited) got involved. The project needed a data storage system that could start small, without a lot of operational overhead, but scale up to virtually any size. And it needed to both support accessing data on individuals, and also let us do bulk analysis of the data using a Hadoop workflow (more on that in a bit).
We decided to use Cassandra, which is a NoSQL database that satisfies the above requirements. We set up a three server Cassandra cluster in Amazon’s cloud in a few hours, and then connected it up to a custom application that handles requests coming from the Durkheim Facebook app. The remaining piece is a separate data collector daemon that uses the Gigya service to continuous fetch new tweets from Twitter and posts from Facebook, and then stores them in Cassandra. The resulting two tables (Users and Activity) contain all of the data needed for subsequent analysis.
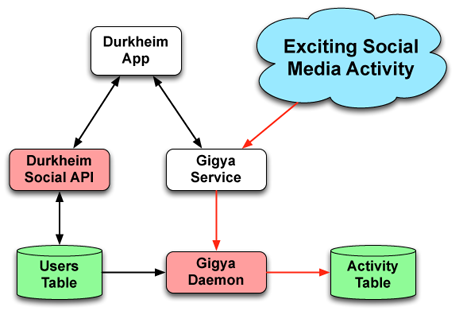 |
|
| Data Collector | |
Hadoop Workflow
What we’ve been talking about is a system that stores the data coming in, and that was relatively simple to implement. Predictive analytics at scale is a little bit trickier. What we have for each user is demographic data like their age and gender, plus all of this social media activity. What’s missing is a way of processing all that data with multiple predictive analytic models that are defined and stored elsewhere.
If you just had a single user, and you’re applying a single model to their data, then you don’t have a scaling issue. If you have five models, and you’re running it on a single user, then you’re still probably OK. But what happens when a model is added or changed, and this model is being used on a bunch of different users? Now you’ve got to reprocess the data for all of those users with that model. This is happening all the time because these models are in a constant evolution.
So when that happens, you’ve got a bulk data processing problem. It’s okay to do at batch, but you don’t want it to take forever, and you want to be able to count on the quality (completeness) of the results. This winds up being a very good fit for Hadoop. We can use Hadoop because the latency of a batch processing system is OK; there’s no strict requirement such as “in 30 seconds, you’ve got to get results from this new model”. So we can use Hadoop because it makes it easy to scale, and it makes it easy to have reliable results. If you need continuous processing, then you need to be looking at something else, like maybe Storm.
When we do Hadoop workflows, we don’t write Java code at the Hadoop API level because if you do that, you’re making a mistake. It’s like writing micro code; nobody writes micro code or machine language anymore; you use a higher level language. So we use something called Cascading which is an open source project that provides a Java API on top of Hadoop for building workflows. We then process data from the Users and Activity table using these Hadoop workflows that we’ve defined using Cascading.
 |
|
| Bulk Classification Workflow | |
Here’s a visualization of a simplified version of this workflow. On the left side we’ve got information about the individual coming from the Users table, things like their age, their rank, and other static data. Then on the right side we’ve got social media events coming from the Activity table.
This joining of two datasets is a really common thing if you’re doing machine learning because typically you have these same two types of data. For example, any time you go to a shopping site and they know something about you as a customer, what they’re doing is taking your (small) static data along with the clickstream data which is typically a larger dataset, and they’re joining those datasets together because machine learning wants to get these really wide records that contain both the static and the dynamic data.
Once the join has happened, we have these “wide records”. Then we run the predictive analytics models against that data, and we write the results out to the User table. So the workflow itself is pretty straightforward.
Summary
At the end of this project, there were three key points that stood out for me:
- It is possible to use predictive analytics to estimate suicide risk – results from a smaller phase 1 using a non-scalable system based on MySQL achieved 65% accuracy in prediction of suicide risk on an estimated 30,000 linguistic features (keywords).
- The combination of Cassandra & Hadoop for scalable predictive analytics works. You can access individual records easily using each user’s unique ID as the row key, and you can do bulk processing of the data with Hadoop. We didn’t have space to talk about how we can leverage Solr-based search to help refine and assess the analysis, but that’s another useful aspect to the commercial version of Cassandra from DataStax.
- And finally, it’s possible to do good with big data. Working on a project like this is a refreshing change from trying to sell more stuff to more people, which is probably the most common use of Hadoop and big data today.
Author Bio
Ken Krugler is the president of Scale Unlimited, a big data consulting and training company. In 2005 he co-founded Krugle, a code search tool for software developers. In a prior life he worked on internationalization and small memory devices like the original 128K Mac.
For more information please visit http://scaleunlimited.com, and follow the author on Twitter
Disclaimer: This material is based upon work supported by the Defense Advance Research Project Agency (DARPA), and Space Warfare Systems Center Pacific under Contract N66001-11-4006. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors(s) and do not necessarily reflect the views of the Defense Advance Research Program Agency (DARPA) and Space and Naval Warfare Systems Center Pacific.
Related items:
Providing Hidden Benefits With Predictive Analytics
Broken Premises: Why Models Fail and What to Do About It
Healthcare Organizations Face Daunting Data Challenges
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States