


February 3, 2023
Like ChatGPT? You Haven’t Seen Anything Yet

(CKA/Shutterstock)
ChatGPT is taking the world by storm, thanks to its uncanny capability to generate useful text. But as the large language models (LLMs) at the heart of services like ChatGPT get bigger, so too do the odds of seeing even more remarkable AI capabilities emerge, according to AI researchers.
The arms race around LLM was heating up long before OpenAI released ChatGPT to the world on November 30, 2022. Tech giants like Google, Facebook, and Microsoft (which partners with OpenAI) have been pushing the boundaries of deep learning and natural language processing (NLP) for years, cramming more and more layers into the neural networks, training them on ever-bigger sets of data, resulting in an ever-increasing number of parameters that determine the models’ ability to accurately detect patterns in speech.
In early 2020, Microsoft Research took the wraps off Turing Natural Language Generation (T-NLG), an LLM with 17 billion parameters, which was the largest model of its kind at that time. A few months later, OpenAI pushed the bar higher with the debut of GPT-3, which sported 175 billion parameters.
In February of 2021, Google tweaked its T5 models that it introduced in 2019 with the launch of its Switch Transformer, which weighed in at a whopping 1.6 trillion parameters. Google launched its Pathways Language Model (PaLM), sporting 540 billion parameters, in April 2022. Facebook has also been a player in this game, and in May 2022, it launched OPT-175B, a transformer based large language model with up to 175 billion parameters, matching GPT-3. Facebook’s parent company, Meta, made OPT-175B available to the public.
We’re possibly just weeks away from the debut of GPT-4. While OpenAI has been mum on the details of this much-anticipated release, it has been rumored that GPT-4 will contain 100 trillion parameters, which would make it the largest LLM in the world.
While it’s been fashionable to downplay the importance of big data in recent years, the “bigness” of the LLMs is the precise source of all the new capabilities and the excitement. In fact, researchers are eagerly awaiting what new capabilities they might squeeze out of LLMs as they crank the size even higher.
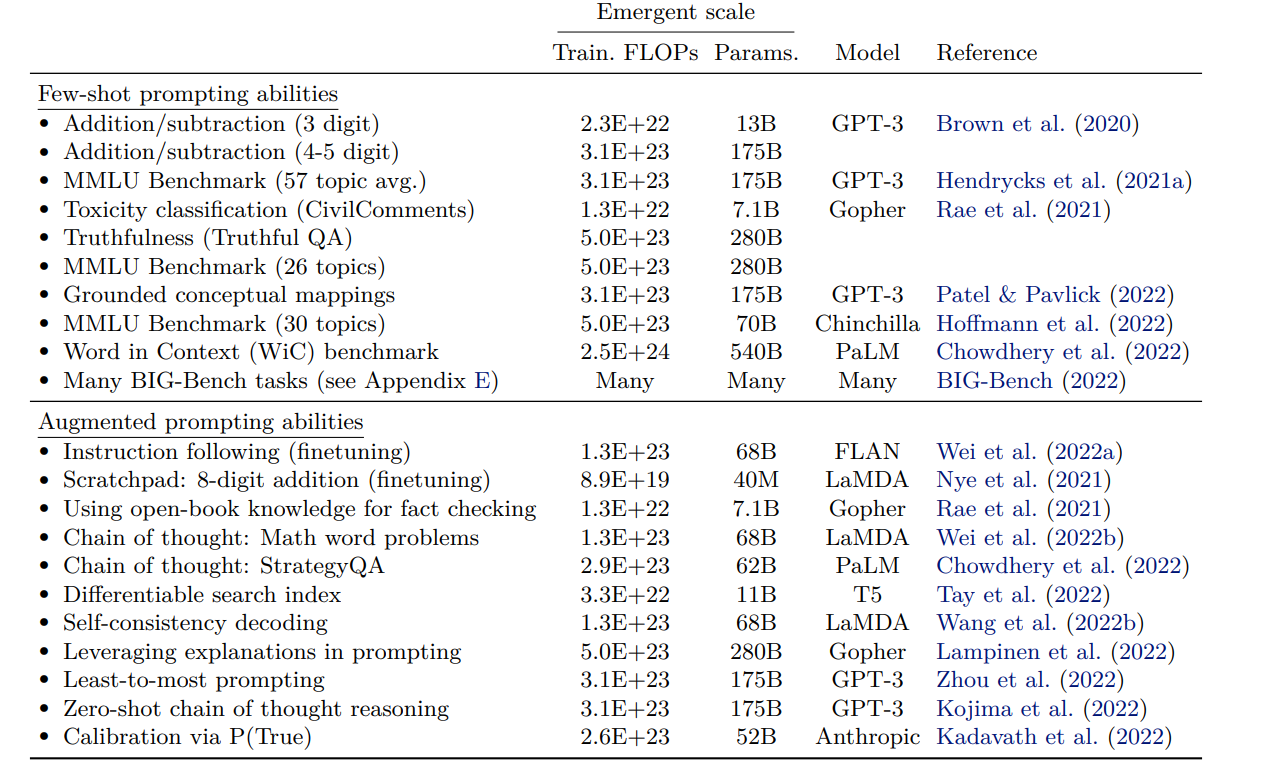
List of emergent abilities of LLMs and the scale at which the abilities emerge (Source: “Emergent Abilities of Large Language Models”)
This phenomenon was laid out in an August 2022 paper titled “Emergent Abilities of Large Language Models.” Researchers from Google Brain, DeepMind, Stanford University, and University of North Carolina discussed seeing unexpected “emergent” capabilities coming out of their super-sized language models.
Throwing more hardware and data at a problem has been a reliable method of getting better answer for decades. This has been a go-to technique utilized by the high performance computing (HPC) community to solve tough challenges in science and engineering, and one that the hackers in Silicon Valley have been trying to replicate on industry-standard servers for the past two decades.
But what the folks at Google, DeepMind, Stanford, and UNC are describing is something much different.
“Scaling up language models has been shown to predictably improve performance and sample efficiency on a wide range of downstream tasks,” the authors write. “This paper instead discusses an unpredictable phenomenon that we refer to as emergent abilities of large language models.”
The idea of emergence has been well-documented in the scientific literature. A little bit of uranium doesn’t do much, Jacob Steinhart, an assistant professor in the Department of Statistics at UC Berkeley, observed in “Future ML Systems Will Be Qualitatively Different.” But when you pack it densely enough, you get a nuclear reaction. The same occurs with other substances and phenomena, such as DNA, water, traffic, and specialization.
We’re now seeing unexpected capabilities emerging from LLMs. The researchers from Google, DeepMind, Stanford, and UNC documented more than 20 emergent capabilities in a range of LLMs they tested, including GPT-3, LaMDA, PaLM, T5, Chinchilla, Gopher, and Anthropic.
The size of the LLM wasn’t a 100% predictor of seeing an emergent capability across the various benchmark tests that the researchers ran. In fact, some emergent properties were observed in some LLMs that were smaller than others. But the researchers say the emergent capabilities are a characteristic of these large models, as well as the way they’re trained and prompted to generate a response.
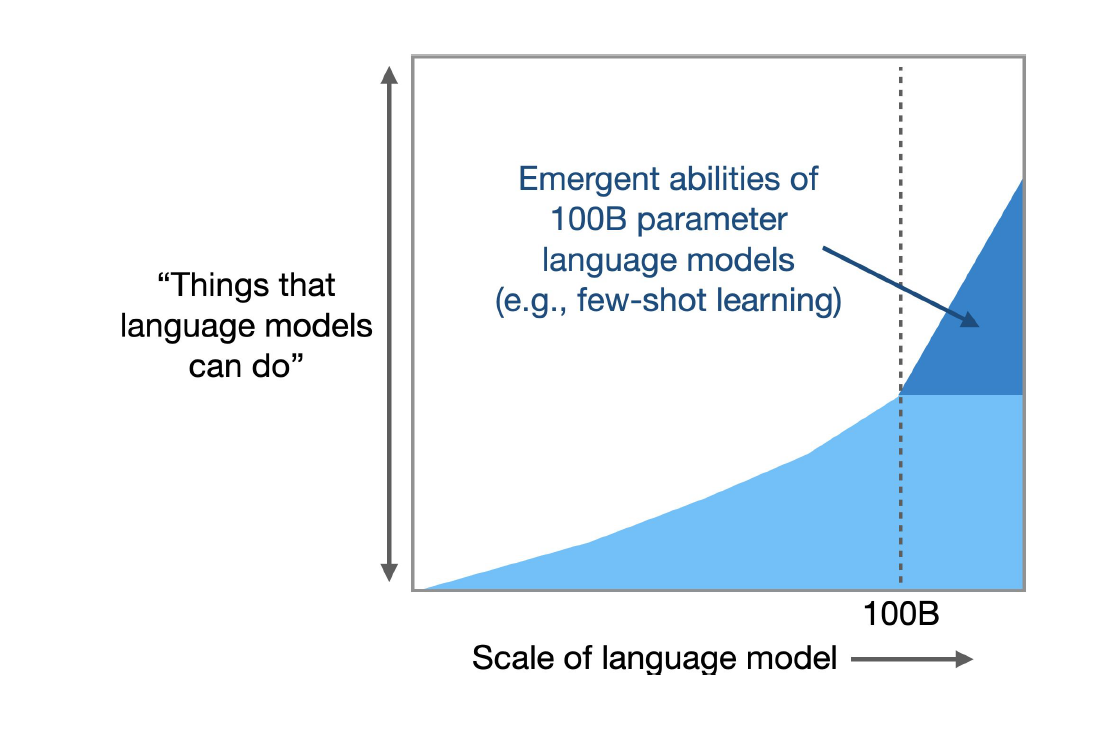
Will more capabilities emerge as models get bigger? (Source: “Scaling unlocks emergent abilities in language models” paper)
Among the emergent capabilities documented by the researchers are addition/subtraction; Massive Multitask Language Understanding (MMLU); toxicity classification, truthfulness; word in context, instruction following; and others.
What new emergent capabilities will we see as LLMs get bigger? That’s hard to say, since the whole phenomenon was unpredicted. But AI researchers are definitely on the lookout.
One researcher who’s working in the field is Google Brain’s Jason Wei. In his recent Stanford presentation titled “Scaling unlocks emergent abilities in language models,” Wei says a LLM technique called chain-of-thought (COT) prompting will bend the performance curve upward. Specifically, Wei says that LLMs that are designed to be guided with “meta-data” through a reasoning process can generate better results.
The combination of bigger LLMs and COT prompting will allow bigger problems to be tackled, such as math word problems, symbolic reasoning, and challenging commonsense reasoning. These are problems that traditionally trained LLMs using standard prompting methods will struggle to achieve, he says.
“The ability for language models to do multi-step reasoning emerges with scale, unlocking new tasks,” like chain of thought and follow-up work, he says in his presentation. “There are reasons to believe that language models will continue to get bigger and better. Even more new abilities may emerge.”
You can view Wei’s presentation here.
Related Items:
Are We Nearing the End of ML Modeling?
Google’s New Switch Transformer Model Achieves 1.6 Trillion Parameters, Efficiency Gains
Microsoft Details Massive, 17-Billion Parameter Language Model
Leading Solution Providers
















