


June 21, 2022
The Mystery of Predictions in AIOps

(metamorworks/Shutterstock)
The main promise of AIOps (Artificial Intelligence for IT Operations) is to predict issues that could be major incidents and resolve it before it happens with Machine Learning and AI algorithms. How can such predictions be made for IT Operations Management? Can we really separate the signal from the noise and produce accurate alerts that can prevent major incidents?
A Shift to Proactive IT Operations Management
The current discourse on AIOps misses the essential dynamics of AIOps. IT in the traditional sense is mainly concerned with monitoring the IT infrastructure and business applications, and responding to alerts once an incident has already occurred. AIOps does not wait but predict the problems in advance, just on time to take measures to prevent any service outage or major disruptive incidents. The approach is more proactive than reactive. However, making predictions involves lots of uncertainty and risks. How is it then done, since major vendors are betting on AIOps to automate IT Operations and are growing their revenue rapidly with it?
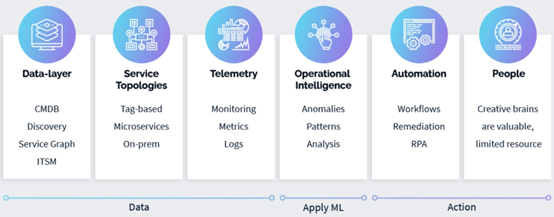
Main principles of AIOps
An Intelligent, Predictive Approach to IT Operations Management
We can define AIOps as the use of artificial intelligence, machine learning, and automation in IT operations and transform the way IT operations are managed by minimizing manual intervention of human operators. The goal is not to take the human out of the loop, on the contrary, it is there to help the human operators to manage the ever-increasing complexity in IT operations. We can characterize AIOps solutions at different platforms with these four principles:
- Advanced data processing and predictive analytics: ingestion of big data for real-time analysis of streams of data and historical analysis of stored data for training AI and ML models to make predictions.
- Topological data analysis: mapping and discovering all the IT assets and applications across the IT landscape.
- Correlating events and other relevant data: mapping time and IT network topology to cluster related events. Additionally, discovering patterns and predicting events or incidents by continuously learning how the data behaves. The correlation is important to automate effective, efficient root cause analysis for IT service issues and incidents.
- Automated remediation: while monitoring the IT landscape continuously with AI and ML, in case an anomalous behavior occurs, AIOps recommends a certain course of action for the human operator, or if enabled, triggers automated remediation to resolve the issue instantly.
The Puzzle and the Mystery in Predictions
Amid large amounts of data from business applications and IT systems, and our ability to collect or generate large volumes of data, we are sometimes surprised by unexpected events that makes us wonder whether we could have prevented this from happening. When we try to understand why a problem occurred, we can trace back to the source of the problem. Try to identify its primary cause. Ask ourselves how this could have happened while the monitoring teams were continuously monitoring and tracking.
We can mainly create a logical story of the events that have occurred. However, that is mostly after an incident happens. An answer to the moral of this story is that the world offers us much more mysteries than puzzles. Making predictions involves working with these mysteries; events that are not predictable while having large volumes of data and knowledge at hand: ‘Mysteries grow out of too much information’. Large parts of making predictions in AIOps have been described as a puzzle solving method with advanced data analytics tools. With these tools we can solve the puzzle by finding recurring patterns in the data. Because there is an answer and we can find it. But intelligence is not about puzzle solving. It is about framing the mysteries.
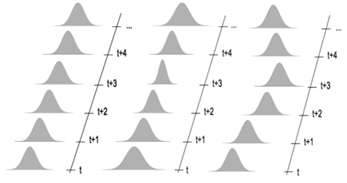
We ideally want stationary data like at the most left part, but we mostly get data that behaves randomly like on the most right part
As real-time data is non-linear and non-stationary, and not entirely predictable because it is contingent on ‘future interaction of many factors, known and unknown’; it can only be framed by identifying the critical factors and applying some sense of how they have interacted in the past and might interact in the future’. The framing is necessary for prevention. In the context of AIOps, this would mean prevention of major incidents and service outages. In other words, managing IT operations with predictions.
Can We Manage IT Complexity with Predictions?
Imagine you are driving a car at night in the countryside. It is dark and there is no light outside. You can only observe what the lights of your car illuminate, otherwise there is complete darkness all around you. A lot of things can happen, depending on many factors like speed, road quality, presence of wilderness in the area or a mountainous area where a rock could fall on the road.
There is a high chance nothing might happen and driving would be safe. However, there is still some risk (known unknowns) and uncertainty (unknown unknowns) on the road. A deer can unexpectedly come up the road, hit your car, or a reckless driver might cut you off and cause an accident.
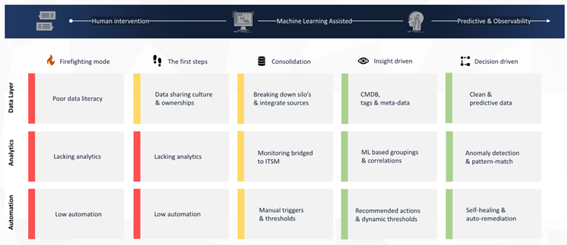
AIOps maturity model
AIOps Maturity Model
In IT operations, the spotlights are how much data/metrics you can collect of your IT infrastructure and business applications/services. It depends on to what extent you can deploy machine learning, artificial intelligence and statistical models to automate parts of your monitoring and IT operations. To observe and have real-time, deep visibility on the health of your IT system.
The major difference between driving a car by a human driver and running IT operations is that the human driver must spot an anomaly in advance to stop the car or deflect on time to not crash and have an accident, while in IT operations we use advanced machine learning algorithms to detect and predict anomalous behavior and patterns in the data before it becomes an issue. However, there are some common factors that influence your anomaly prediction. Like speed, observability and data/road quality. There may not be a deer jumping on the road and hitting your car, but there can be a sudden overload on your CPU power and servers because a pandemic hit the business and suddenly everyone must work online because of a general lockdown.
Accepting the Limits: Black Swan Events and Creating Antifragile Systems
Assuming that more data (metrics, log, trace) from your IT system and business applications would produce accurate predictions and prevent incidents is a fallacy. Collecting and processing more and more data creates its own limits. Just like the stretched limits of the spotlight of a car driving through the darkness, only observing parts of the road each time, we are observing parts of the IT infrastructure and applications each second. Unexpected, low risk high impact black swan events could still crash your system. But what is AIOps then good for? Well, one sure benefit of AIOps is that it contextualizes data and anomalous behavior accurately enough to take preventive actions (even in an automated, self-healing way). The monitoring teams would not be overwhelmed with noisy alerts. AIOps will filter the signal from the noise much more accurately.
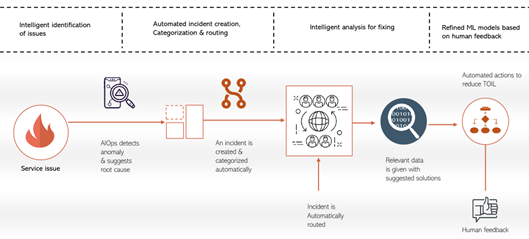
An Example of a Workflow of AIOps
Furthermore, the machine learning part makes the approach antifragile: systems that gain from shocks or incidents. Dynamic, statistical models and thresholds are built based on the behavior of the data. Therefore, by combining powerful predictive statistical models with machine learning and AI (automating inference and decision making), we are able to algorithmically create adaptive systems that learn and push the limits further. This is the essence of having AIOps for IT operations management.
About the author: Akif Baser is R&D lead for AIOps and data science at Einar & Partners. in Amsterdam, the Netherlands. Baser has in-depth experience with machine learning and AI for IT infrastructure, predictive modelling, metric-time series, ML-based operating models, and data strategy around AI. ‘
Related Items:
The True Cost of IT Ops, The Added Value of AIOps
AIOps: Beat the DevOps Arms Race
Leading Solution Providers
















