


June 2, 2022
Big Graph Workloads Need Big Cloud Hardware, Katana Graph Says

According to Gartner, graph technologies will be used in 80% of data and analytics innovations by 2025, a significant increase from the 10% used in 2021. One of the companies hoping to capture a piece of this booming market is Katana Graph, which is carving a spot for itself by developing a graph database platform that can leverage advances in distributed hardware to crunch big graph workloads.
Katana Graph was co-founded in 2020 by two computer science professors at the University of Texas at Austin, CTO Chris Rossbach and CEO Keshav Pingali. Rossbach, who previously was a member of the VMware Research Group, has focused his academic research on areas like virtualization, accelerators, and parallel architectures. Pingali, meanwhile, specializes in parallel programming and distributed computing, according to his cv.
While the Austin-based company is fairly young, the technology underlying the Katana Graph’s property graph database has its roots in its co-founders’ research going back decades, says Farshid Sabet, the company’s chief business officer.
“The value of the company is when the data is larger, when you have to do very deep analysis, as you go through the nodes and you do deeper hops, the computational intensity grows exponentially,” Sabet says.
Distributed Graphs
Katana Graph’s distributed parallel computing framework is composed of three parts, including a streaming partitioner, a graph compute engine, and a communication engine. The partitioner is responsible for distributing the data to various nodes of the cluster, while the compute engine orchestrates and schedules the work across the nodes. The communication engine, meanwhile, enable the nodes to complete work efficiently.
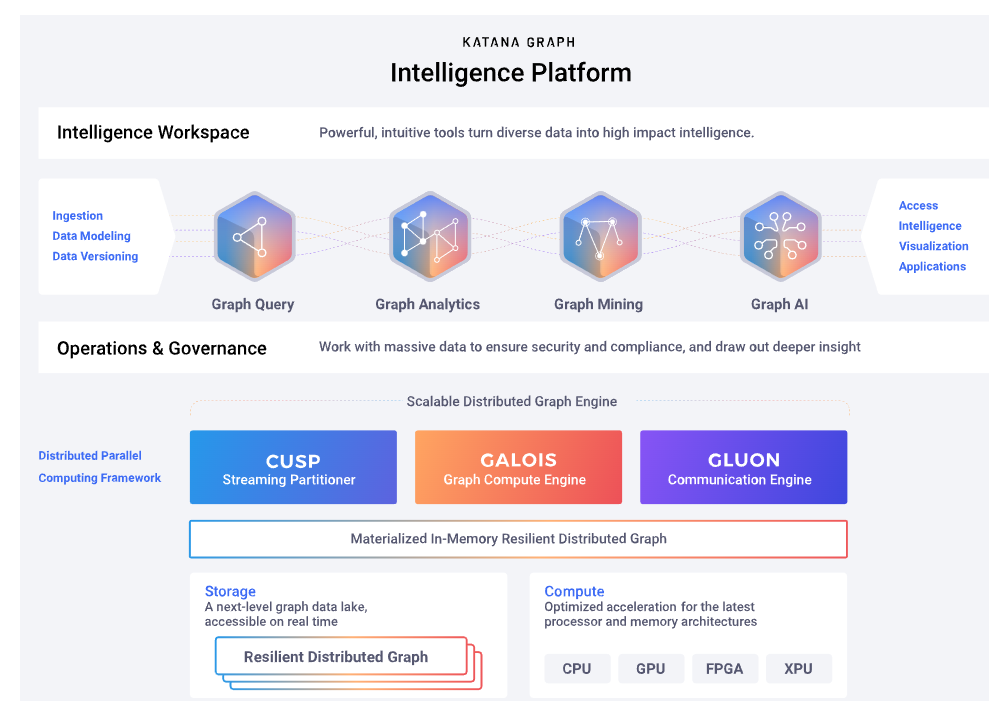
Katana Graph brings multiple engines to bear on graph data (Image source: Katana Graph)
The company takes a fresh look at the problem of how to best build a distribute graph database, says Sabet, who previously worked at Movidius and Intel before joining Katana Graph. That enables Katana Graph to work at a scale and at speeds that can’t be matched by graph competitors, he claims.
“A lot of people take a simplistic [approach] in terms of partitioning the graphs,” Sabet tells Datanami. “But as the graph sizes grow larger and new cases are coming, some of those assumptions are not holding true.”
The core IP of the company resides in the graph communications element of the framework, Sabet says. Advances at this level enable Katana Graph to run very large graph workloads at high speed. They also enable the platform to run different workloads together at the same time in a dataflow style, similar to how Databricks operates, Sabet says.
Katana Graph provides four ways of querying data in the graph, including Graph Queries (contextual search); Graph Analytics (path finding, centrality, and community detection); Graph Mining (pattern discovery); and Graph AI (prediction).
Developers can program workflows in Katana Graph using Cypher, the graph programming language originally developed by Neo4j and subsequently open sourced. Many graph databases vendors support Cypher. Katana Graph also supports Python and C++, Sabet says.
Hardware Boosting
Katana Graph can leverage different types of hardware, including CPUs, GPUs, FPGAs, and ARM chips. The software can also support Intel’s Optane memory and accelerators. But it’s the distributed nature of Katana Graph that sets it apart, Sabet says.

Distributed memory communication is a big factor in the efficiency of scale-out graph data environments, Katana Graph says (Gorodenkoff/Shutterstock)
“We’ve done a lot of work over the past nine years…to be able to take advantage of the distributed memories, even some of the memories of different types,” Sabet says. “Most of these [graph] environments run only on a CPU in this memory. Nvidia has something that runs in one GPU and one machine. If you want to combine this together [for scalability] the only game in town is to not only support multiple hardware, but also distributed hardware that uniformly addresses the graph.”
The core technologies underlying Katana Graph was originally developed and tested on high performance computing (HPC) infrastructure at the UT-Austin, according to Sabet. Those machines had gobs of memory, which was very expensive a decade ago but was necessary to solve high-end scientific and technical problems.
As the cost of memory has come down, especially in public cloud environments, it has opened up new possibilities for users to run analytic and AI workloads that were previously cost-prohibitive in the commercial space. That works in the favor of Katana Graph, which has been proven to scale out to 256 nodes and graphs with more than 3.5 billion nodes and 128 billion edges (it was designed to scale past 1 trillion edges, the company says).
“Graph is really compute- and memory-intensive,” Sabet says. “The supercomputers of 10 years ago, 12 years ago, are the servers we have today. That’s why the company is doing very well in this.”
A dozen years ago, many developers were looking at how to fit their applications into one CPU with the lowest amount of memory possible. “That was the right decision 12 years ago,” Sabet says. “But these guys [Rossbach and Pingali] didn’t have that limitation. They were thinking about what do we need to be able to solve this problem.”
Growth in GNNs
One of the benefits of Katana Graph is that developers are able to incorporate machine learning and AI models they have already built using frameworks like XG Boost and PyTorch into the Katana Graph platform, Sabet says.
“We can combine all of those without you have to change anything or remodify the algorithm. You use those existing frameworks, existing libraries, and add on top of [your] machine learning,” he says. “You want to make sure that developers are comfortable with the environments that they have.”![]()
Graph neural networks, or GNNs, combine the power of deep learning and graph databases, and are an area of particular interest at the moment. Instead of training a convolutional or recurrent neural network to identify patterns in an image or in a string of words, GNNs can recognize and exploit patterns in the connectiveness of the data elements that make up the graph.
The accuracy, performance, and cost benefits of GNNs are gaining a lot of followers at the moment, he says. For example, a biomedical researcher could use GNNs running in Katana Graph to identify novel proteins that are expressed as a convoluted collection of molecules in a graph database. “You train it to look for that protein group,” Sabet says.
In addition to biomedical researchers, Katana Graph has attracted interest from the financial services field. Fraud detection is a classic graph database use case, and Katana Graph has its share of those customers and prospects, Sabet says.
“There are a lot of technologies available for fraud detection. But this one can predict the fraud that could happen with a higher level of accuracy,” he says. “They want the updated version of machine learning algorithms, like XGBoost and other techniques.” GNN provides that updated version, he says.
The third area of focus for Katana Graph is cybersecurity. With so many cyber signals flying around the Internet, graph analytics brings a potent tool to help the good guys connect the dots and keep the bad guys on their toes. The company was started in part with its work with DARPA to bring those signals together, Sabet says.
Katana Graph has a handful of paying customers and has an active pipeline for many more. The company completed a Series A round of funding in 2021 that was worth $28.5 million. That has enabled the company to grow from less than 20 employees to nearly 100 over the course of a year, according to Sabet.
“We have experts from various different fields that are [joining the company],” he says. “Most of the employees are on engineering side, but also the business side has been growing. We have been able to hire very capable people from our competitors [like] TigerGraph, Neo, Google, and Microsoft.”
The company’s software is cloud-only at this point, and it plans to launch a managed offering in the cloud soon.
Related Items:
Can Streaming Graphs Clean Up the Data Pipeline Mess?
AWS Unveils Graph Database, Called Neptune
Graph Databases Everywhere by 2020, Says Neo4j Chief
Applications:
Artificial Intelligence, Data Mining, Enterprise Analytics, Predictive Analytics, Research Analytics, Security
Vendors:
AWS, big data, Gartner, Google Cloud, intel, Katana Graph, Neo4j, NVIDIA, property graph, TigerGraph
Leading Solution Providers
















