


April 5, 2022
Databricks Ships New ETL Data Pipeline Solution

Databricks today announced the general availability (GA) of Delta Live Tables (DLT), a new offering designed to simplify the building and maintenance of data pipelines for extract, transform, and load (ETL) processes using Structured Query Language (SQL) and Python. The cloud services company also announced support for change data capture (CDC), an upgraded graphical user interface (GUI), as well as the fact that 400 customers are already using DLT, including ADP, Shell, and H&R Block.
DLT was originally unveiled last May during Databricks’ Data + AI Summit 2021. The goal was to turn the development of ETL data pipelines–which today can be an excruciating process rife with frustration and failure–into more of a declarative process that users can more easily interact with.
After 10 months in preview, DLT is now ready for primetime for production workloads. According to Databricks, the new service will enable data engineers and analysts to easily create batch and real-time streaming pipelines using SQL and Python.
“Unlike solutions that require you to manually hand-stitch fragments of code to build end-to-end pipelines, DLT makes it possible to declaratively express entire data flows in SQL and Python,” Databricks writes in a blog post today.
Besides the simplified development, DLT brings other benefits, the company says. Chief among those is the capability to work in a modern DevOps environment, which will streamline the process of taking a pipeline from development to testing to deployment using best practices like CI/CD and SLA constructs.
Observability is another core component of DLT, according to Databricks. “We also learned from our customers that observability and governance were extremely difficult to implement,” Databricks employees wrote in the blog, “and, as a result, often left out of the solution entirely.”
DLT addresses observability in part through a feature called Expectations. According to Databricks, Expectations “help prevent bad data from flowing into tables, track data quality over time, and provide tools to troubleshoot bad data with granular pipeline observability so you get a high-fidelity lineage diagram of your pipeline, track dependencies, and aggregate data quality metrics across all of your pipelines,” the company says.
DLT runs on the Databricks cloud, so customers don’t have to worry about sizing the cluster underpinning the ELT data pipeline. The company says DLT “automatically scales compute to meet performance SLAs” within cluster size limits set by the customer.
There’s no need to manage batch and real-time data pipelines differently, as they can both be handled in DLT from a single API, the company says. That allows customer to “build cloud-scale data pipelines faster…without needing to have advanced data engineering skills,” Fatbacks says.
The new offering also brings advanced ETL features like orchestration, error handling and recovery, and performance optimization. These features collectively allow customers to “focus on data transformation instead of operations,” the company says.
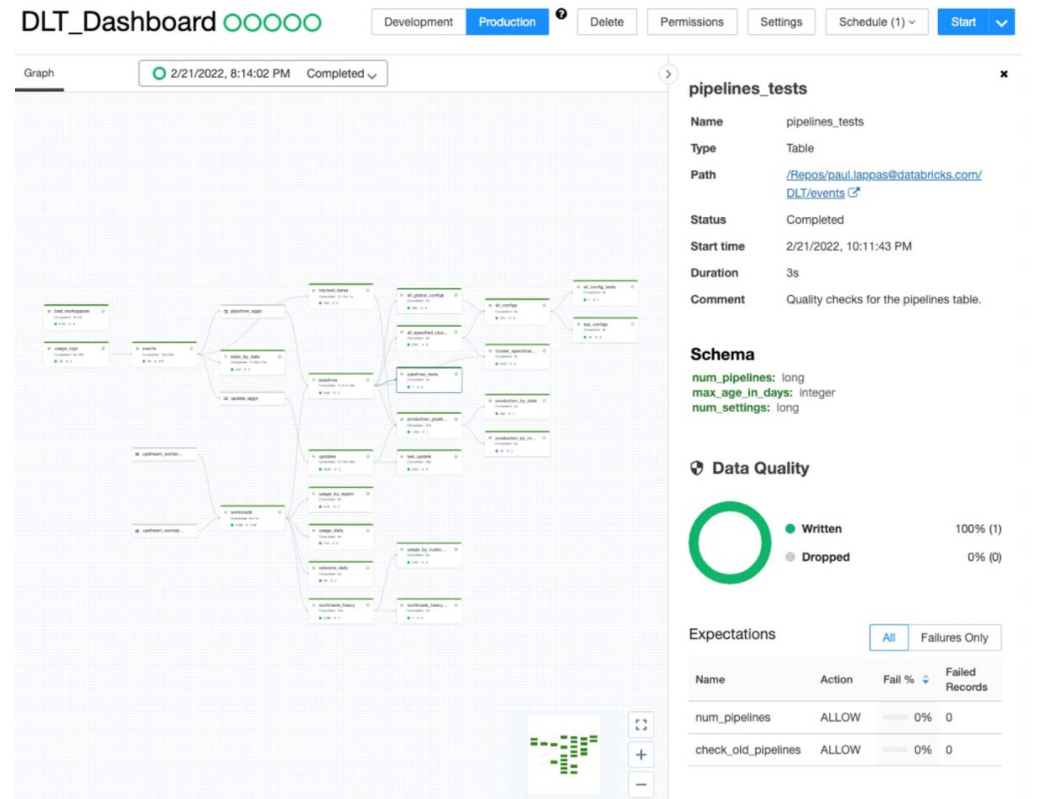
DLT provides a GUI for monitoring data pipelines
Since unveiling DLT last spring, Databricks has added a CDC capability, which will enable customers to extract data from production databases and feed it directly into data pipelines. The company is also rolling out a preview of Enhanced Auto Scaling, which the company says will provide “superior performance for streaming workloads.”
The company has also bolstered its GUI in several ways, including the addition of new capabilities for scheduling DLT pipelines, viewing errors, managing access control lists (ACLs), and better visuals for monitoring the lineage of tables. It also added a new GUI for data quality observability metrics.
Several early DLT users shared their experiences with Databricks. Jack Berkowitz, the chief data officer at ADP, says DLT has helped with the migration of human resources data into its cloud data lakehouse.
“Delta Live Tables has helped our team build in quality controls, and because of the declarative APIs, support for batch and real-time using only SQL, it has enabled our team to save time and effort in managing our data,” Berkowitz said in a press release.
DLT has also helped Shell, which is aggregating trillions of pieces of sensor data into an integrated data store, save time and effort in the process.
“With this capability augmenting the existing lakehouse architecture, Databricks is disrupting the ETL and data warehouse markets, which is important for companies like ours,” said Dan Jeavons, the general manager of data science at Shell. “We are excited to continue to work with Databricks as an innovation partner.”
For more info on DLT, read the Databricks blog.
Related Items:
All Eyes on Snowflake and Databricks in 2022
Databricks Unveils Data Sharing, ETL, and Governance Solutions
Applications:
Enterprise Analytics
Vendors:
Databricks
Leading Solution Providers
















