


March 21, 2022
WhyLabs Goes In Search of AI Observability

(PureSolution/Shutterstock)
Data observability is one of the hottest sectors of the market, and numerous startups have attracted big investments in their offerings. But when it comes to the impact of data on AI, data observability only gets you so far. Now a startup called WhyLabs is developing an AI observability platform that keeps an eye on the state of data as well as machine learning models.
WhyLabs was founded to combine elements of data observability with machine learning operations (MLOps) into a single platform that minimizes the work required in keeping AI applications running smoothly, according to Andy Dang, the head of engineering and a co-founder of Whylabs.
“The goal of the company is to first build a data observability platform for data and machine learning,” he says. “The second part we want to solve is end-to-end monitoring with regard to data health and model health when it comes to real-world operations.”
As data pipelines get bigger, companies find they need to devote more of their data engineer’s time to manually monitor them, manage them, and fix the little issues that life throws at you in the world of big data. The company estimates data engineers spend 40% of their time in these tasks, if required to do them manually.
Engineers need to be on the lookout for things that can cause a hiccup in the machine learning system. For example, a seemingly innocuous change to a minor piece of business logic can have a fairly big impact down the line.
One WhyLabs customer had their ML system rendered inoperable because an upstream data supplier had switched from a five-digit Zip Code to a nine-digit Zip code. COVID also threw many ML systems for a loop, although much of that was due to fundamental changes in human behavior and not some data or coding error. No matter how they arise, these can wreak havoc on applications that use ML.
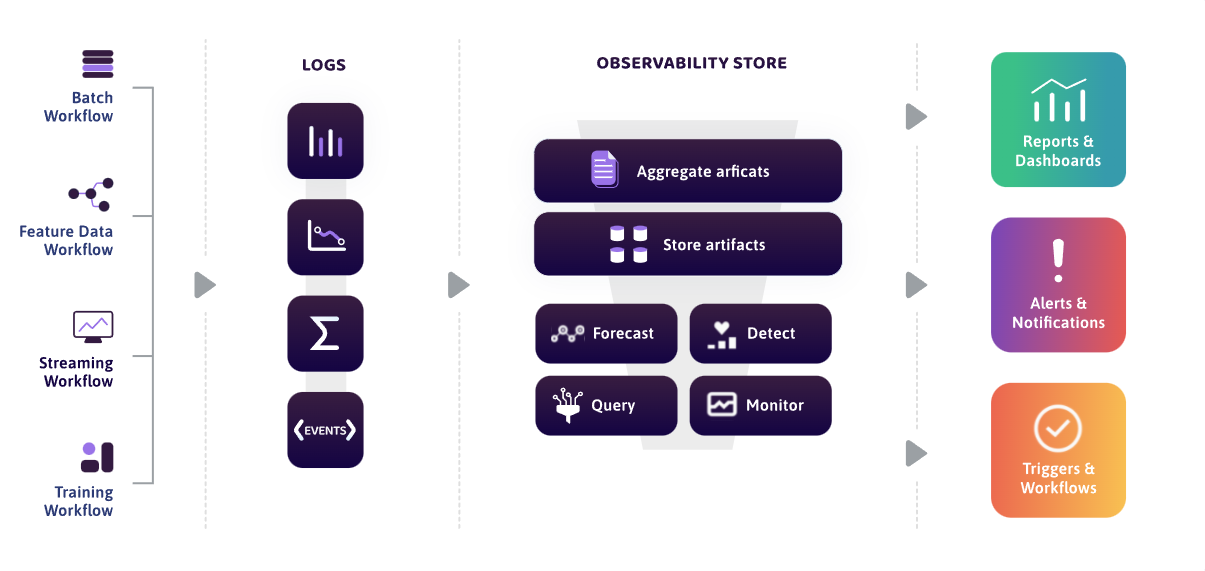
WhyLabs aims to fill the gap in the market for AI observability solutions (Image courtesy WhyLabs)
“What you end up with is data changing either significantly in shape or form or just the distribution of data shifts significantly,” Dang says. “The challenge for that is when you have hundreds of features, it becomes very onerous to do that [manually]. So what we solve is scaling out those very simple checks, very basic fundamental check at the data quality level, but at scale for users and then surfacing them.”
Sketching Data
WhyLabs has two main offerings: an open source data observability and monitoring component, as well as an enterprise offering that provides a long-term store for data observability metrics as well as sophisticated visualization. Some of WhyLabs customers just use this component, such as Yahoo Japan and Stitch Fix, Dang says, while others use the full system.
The open source offering, called whylogs, is designed to create a data profile of the data in a customers’ ML system. It works largely by relying on the statistical properties of data under the hood, which allows it to detect data drift, stale models, or other changes in data quality that could impact the performance of the AI application.
WhyLabs relies on a wide mix of largely open source technologies to develop its software, including Apache Spark, Apache Druid, and others. The whylogs tool, which is available in Java and Python versions, is based on Apache DataSketches to create what are essentially fingerprints of the data, Dang says.
“[Apache DataSketches] was designed for Web log analysis by Yahoo, and it has this technique called sketching where basically it builds a bunch of bitmap operations, like bitmaps underneath the hood, and then you can take a look at those graph data structure to estimate, approximate the shape of the data,” he says.![]()
These data sketches give WhyLabs statistical insight into unique values contained in the data as it flows through a customers’ systems. These data flows could be a series of SQL queries running against a database in batch orientation; JSON data being passed via APIs or REST services; image data being ferried by Apache Kafka; or anything in between, Dang says.
“So that’s the first part, statistics collection,” Dang continues. “Once that is done and you do it over time, we can start doing some smart monitoring on top of that.”
Smart Monitoring
In addition to the open source whylogs offering, WhyLabs develops an enterprise offering that takes data and ML observability to the next level, including simplified deployments, collaboration, visualization, and integration with monitoring tools.
WhyLabs uses the concept of “recipes” with its enterprise version, Dang says. “Out of the box, you just select your use cases, what you want to monitor, and you generate tons of monitors based on the use cases,” says Dang, who previously worked on ML systems at AWS along with his two co-founders. “Think about recipes. You select and add them on the menu.”
The second aspect of the enterprise offering is a visualization environment designed to allow teams to collaborate. It also works in real time, as opposed to requiring users to view their whylog reports in a Jupyter notebook, Dang says.
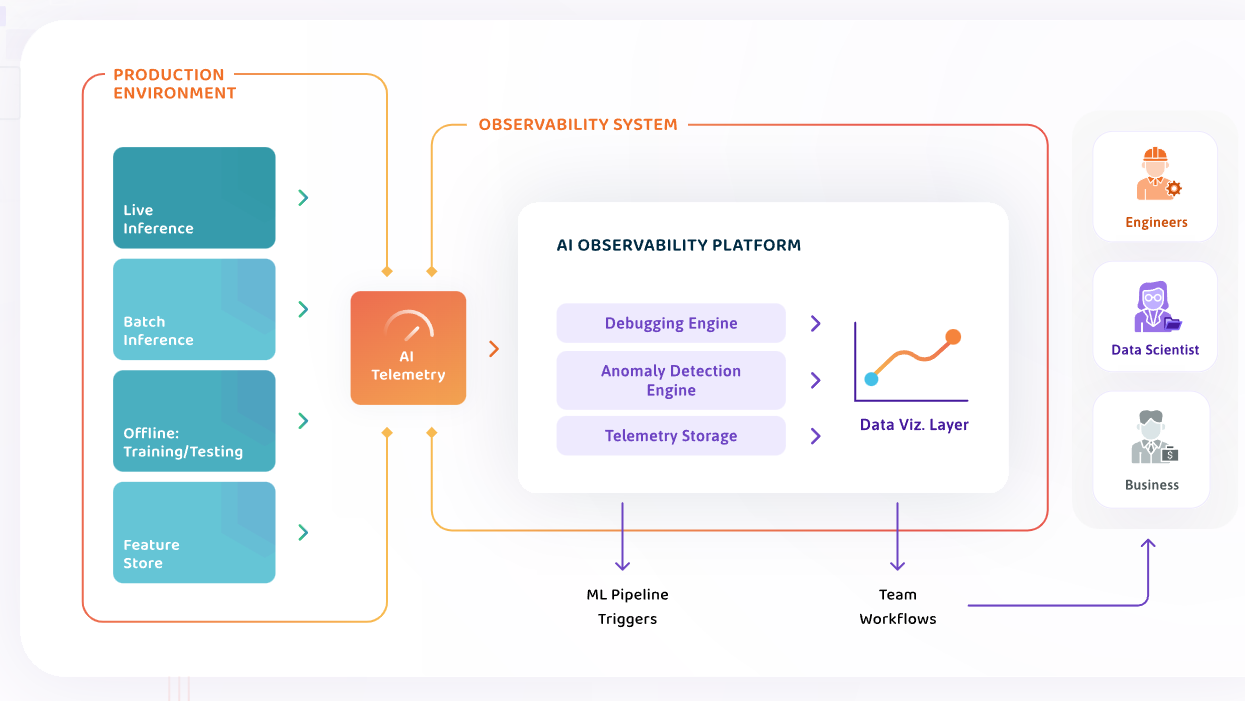
The anatomy of an enterprise AI Observability platform (Image courtesy WhyLabs)
“We can also emit … into downstream systems like PagerDuty or ServiceNow,” he continues. “That allows you to close the loop…with respect to the data health lifecycle.”
One of the characteristics that sets WhyLabs offering apart from other observability tools is it doesn’t store a copy of the data. “Fundamentally, at the philosophical level, I find it wrong,” Dang tells Datanami.
But it does store the sketches–the statistical profile of the customers’ data. To manage this data, it adopted Apache Druid to serve as a time-series repository of this data. This can be implemented alongside whatever other distributed system frameworks are in place in the customers’ environment, which gives WhyLabs a great degree of flexibility, Dang says.
“Our logging is done within the customer infrastructure application, so it’s super performant,” Dang says. “You can run it in various infrastructure like Apache Spark, Apache Flink, Kafka, Python, Jupyter notebook, which is where most people start, or Docker containers. And that part of it is really designed to be super lightweight and scalable.”
WhyLabs so far has attracted $14 million in financing. Last week, the Seattle, Washington company announced that its offering is now available in the AWS Marketplace. Dang says the company had about 10,000 downloads of its Python-based whylogs tool last month. As the word gets out about its unique approach to AI observability, those numbers will likely rise.
Related Items:
Observability and AIOps Tools Rise with Big MELT Data
Companies Drowning in Observability Data, Dynatrace Says
Who’s Winning In the $17B AIOps and Observability Market
Applications:
Artificial Intelligence
Sectors:
Retail
Leading Solution Providers
















