


January 24, 2022
The Search for Better COVID Data Is Not Over

(Vitalii-Stock/Shutterstock)
From a public health perspective, the past 23 months have been, shall we say, eventful in the United States. More than 70 million Americans have contracted COVID-19, according to the Johns Hopkins coronavirus tracker, and nearly 900,000 have died of it. As the Omicron variant peaks and begins to wane, epidemiologists are taking stock of our current ability to track this virus, and determine what new tools and data we’ll need to stop the next one.
When it comes to data and the COVID-19 pandemic, SAS epidemiologist Meghan Schaeffer is conflicted. The public health veteran is encouraged by some things, but the presence of large gaps in our understanding of the virus’s spread have been hard to stomach.
“It was absolutely astounding to see how much information was shared in the beginning and has been shared throughout the pandemic, and how much data people could access and interpret, mostly correctly,” says Schaeffer, who has an advanced degree in public health and epidemiology and also runs Aperio Statistical Consulting. “That was really tremendous for science as a whole. We shared not just data, but research information, sample sizes. We started to see into research in a way that we’ve never seen before. So those are all good things.”
But the COVID-19 pandemic has also expose big gaps remain in the way we collect, process, and analyze data about infectious diseases. One of the biggest problems is the disconnected nature of how information trickles up from hospitals to state departments of public health to the federal government and the Centers for Disease Control and Prevention (CDC).
“1,000%, yes,” Schaeffer says when asked about the difficulties in data integration stemming from the various disjointed processes that hospitals and other healthcare providers use to report case counts and other data. “This this to me is one of the biggest pain points of the pandemic, and we cannot enter another situation like this with the current state of health care and public health not interacting with each other in a productive way.”

A lack of standardized data collection has hamstrung public health officials throughout the COVID-19 pandemic (SOMKID THONGDEE/Shutterstock)
Because of a lack of a standardized data collection methods in hospitals, which typically report to state health departments before its rolled up by the feds, the COVID-19 case count data has been anything but tidy. The editors at The Atlantic, when they cataloged the state of COVID-19 data, dubbed it a “messy patchwork.”
What’s more, sharing case data has also been hampered by privacy protection laws, Schaeffer says. “We have hospitals that are using Google Docs or shared drives, or other ways to disseminate information,” says Schaeffer, who is also a National Public Health Advisor with SAS. “There are major, major clinical decisions being made on the basis of these paper and pencil counts, things like distribution of PPE, allocations of medications and vaccination resources.
“That can be improved. It absolutely can be,” she continues. “We have the data and health information exchanges, in electronic medical records. We have the extraction protocols to do this. We just now have to push healthcare to make those connections to public health. And we also have to equip public help with the information and the capabilities to receive it.”
The shoddy state of COVID data prompted analytics expert Tom Davenport to co-author a August 2020 MIT Sloan Management Review story, which found a dismal state of data. “One is forced to conclude that the data needed to manage the COVID-19 pandemic is effectively unmanaged,” Davenport and his co-authors wrote. “This is an acute problem, demanding urgent, professional attention.”
Things haven’t gotten much better since that report was written. Schaeffer, who previously worked as an epidemiologist for the state of Iowa, says we need major investments in IT infrastructure to bring state and federal systems up to speed.

Data concerns have hampered the COVID-19 response from the CDC and other public health institutions
“The US response has been difficult. It’s been difficult to be a part of it. It’s been difficult to watch,” Schaeffer tells Datanami. “As someone who’s worked in public health for a long time, I remember the plans that we created when the first SARS came out post 9/11. We had response plans for all of this–all of these scenarios, even biological weapons.
“When COVID came around, those plans were nowhere to be found and it wasn’t one administration or politicians fault,” she continues. “There were multiple successive administrations that reduced the funding in public health reduced workforce, took away software and training, and that’s resulted in where we are now.”
Technology has advanced significantly since the public health community’s last major investment in IT nearly two decades ago. We have proven the capability to effectively store tens of petabytes in distributed clusters, maintaining lineage and governance. We can analyze huge amounts of data while protecting privacy, and build huge AI models to predict the future with sometimes astonishing accuracy.
The CDC is working to update its data estate. Currently, it has more than 700 databases, Schaeffer says, and is implementing a data lake. It’s also working with several academic partners to build a new forecasting center. It’s a good start, but more needs to be done, she says.
“Common data lakes have been around in commercial industry and private sector for decades,” she says. “So yes, they need actual physical infrastructure, but they also need analytic tools and functions and abilities and staff to be able to structure those systems and extract the data in a meaningful way.”
Other types of data collection have been a mixed bag. The US was behind the eight-ball almost from the get-go when the CDC’s first COVID-19 test failed. Lately, we have seen a surge in the availability of fairly accurate COVID-19 test kits, but that isn’t enough.
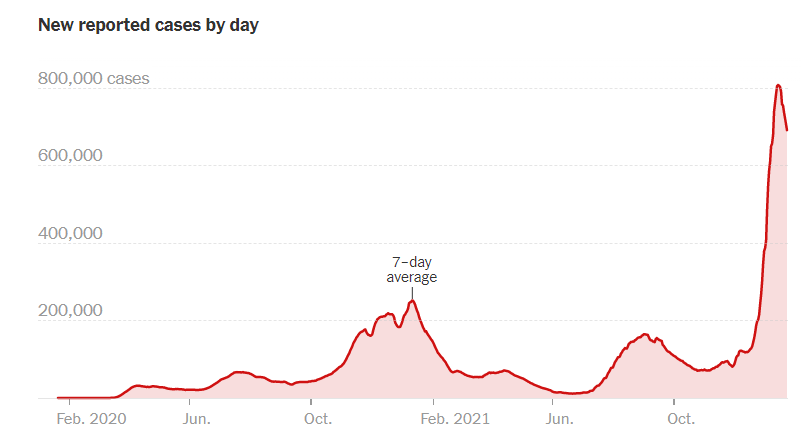
COVID-19 cases reported by day (Image source: New York Times)
“From an epidemiological standpoint and having worked in public health for 20 years, mainly in influenza, I was always stunned by the amount of information that you could get real time, but [also the scarcity] of the big pieces of information that we critically needed that we couldn’t get, and I really, I feel that way now too,” Schaeffer says.
The US response could have benefited from more sentinel reporting to COVID-19, which would provide a more objective view into the level of viral spread in a region compared to voluntary testing, which is subject to the whims of people and therefore moves up and down based on public sentiment.
“As far as what is still missing in my opinion, what we need to start moving into is how do we survey in a sentinel manner,” she says. “How do we set up key markers to where we’re not testing millions and millions of people every single day to assess this situation.”
One data collection effort that has borne fruit during the COVID-19 pandemic is wastewater testing. Because the level of viral shed in sewage is largely proportional to the amount of virus in humans, wastewater monitoring has been a go-to source for more accurate views of the pandemics peaks and valleys, particularly during the latest surge.
“Wastewater surveillance is a really powerful tool, and we’re seeing really a good example of that with Omicron,” Amy Kirby, the program lead for the National Wastewater Surveillance System, told the New York Times. “It’s not just an early warning sign, but it’s also helpful to monitor the full trajectory of a surge.”
The CDC established the National Wastewater Surveillance System in the fall of 2020, and its ramping up activities through state, local, tribal, and commercial entities. One company that’s at the forefront of wastewater detection is Biobot Analytics, is a private company based in Cambridge, Massachusetts.
“It’s a type of data that we are all creating, naturally, organically, when we are using the restroom,” Mariana Matus, the chief executive and co-founder of Biobot Analytics, told the NYT.
Rapid COVID-19 test kits have been hard to find during the Omicron wave (Michele Ursi/Shutterstock)
Armed with data from wastewater monitoring, we’ve been able to document the spread of the Omicron variant over the past two months more accurately than previous surges. That data, in addition to data collected by South African researchers, has enable public health officials in the US and other countries to provide fairly accurate forecasts for Omicron’s steep rise and equally steep fall, which we’re now witnessing on the East Coast.
“I think we were able to get a sense of the magnitude of this spread,” Schaeffer says. “We were able to assess its transmissibility, the duration of this peak.”
Like the 10- to 14-day weather forecasts that meteorologists from the United States and Europe generate from ensemble models on supercomputers, the forecasts of Omicron’s spread have held up. But beyond that, the view remains hazy.
Americans may feel blindsided by COVID-19, but we’ve benefited from several near-misses when it comes to respiratory viruses with the potential to become global pandemics. Two other novel coronaviruses, SARS and MERS, largely avoided the US, while the swine flu (H1N1) epidemic of 2009 also (thankfully) petered out before becoming a global pandemic.
As COVID-19 (hopefully) retreats into an endemic state, Schaeffer encourages us to keep our guard up. There is currently a looming threat of avian influenza that threatens to grow, not to mention all sorts of mosquito-born illnesses from the tropics ready to move north and cause trouble.
“The more people interact with each other and have international travel and interact with animals too, and the more we disrupt the ecosystems that animals live in, the more those viruses and bacteria are going to change, emerge, and affect human health,” she says. “So we just we need to prepare for it. Because it’s just a matter of time.”
Related Items:
Still Wanted: (Much) Better COVID Data
How the Lack of Good Data Is Hampering the COVID-19 Response
COVID Data Report Card: Mixed Results for Public Health
Applications:
Enterprise Analytics
Leading Solution Providers
















