


October 26, 2021
Spark Gets Closer Hooks to Pandas, SQL with Version 3.2
The Apache Spark community last week announced Spark 3.2, a significant new release of the distributed computing framework. Among the more exciting features are deeper support for the Python data ecosystem, including the addition of the pandas API; completion of its ASNI SQL support mode; and the addition of RocksDB to store state.
Python is the most popular language for Apache Spark, which is not surprising, considering the explosion in Python usage in the data science and engineering community. So over the past three years, the Apache Spark community has been working to make the two environments work better together.
That started in 2019 with Databricks’ Koalas project, which implemented the pandas DataFrame API on Spark. That Python effort carried into January 2020 with the launch of Spark 3.0 and Project Zen, so-named after the Zen of Python guide of Python principles. That Zen-like effort yielded a redesigned pandas UDF and better error reporting in Spark 3.0, while in 3.1, it focused on making PySpark “more Pythonic and user-friendly,” the Spark engineers at Databricks write. (Koalas has since been merged into PySpark.)![]()
With Spark 3.2, the integration with pandas goes up a notch. Folks working in pandas can now scale out their pandas application with a single line change, enabling that app to take advantage of multi-node Spark clusters, a capability the Databricks folks attribute to “sophisticated optimizations in the Spark engine.”
“One of the known limitations in pandas is that it does not scale with your data volume linearly due to single-machine processing,” Databricks engineers wrote in an October 4 blog post. “For example, pandas fails with out-of-memory if it attempts to read a dataset that is larger than the memory available in a single machine.”
In tests, the new pandas API in Spark 3.2 showed that pandas applications can scale almost linearly up to 256 nodes, the engineers showed. It also boosted single-machine performance.
Spark 3.2 also enables Python users to the “unified analytics” functionality provided in Spark, including querying data via SQL, streaming processing, and machine learning (ML). This will enable data scientists who work in pandas to move beyond the library’s original focus on batch analytics.

Spark 3.2 adds default support for plotly
Finally, the new pandas API also provides interactive data visualization powered by plotly, as an alternative to the pandas default matplotlib, Databricks says. The use of plotly supports interactive charts.
Spark’s SQL support also gets better in 3.2. Specifically, support for lateral joins, a feature in the ANSI SQL specification, was added. The ANSI SQL mode is generally available now, Databricks says. But it’s not enabled by default to avoid “massive behavior-breaking changes,” it writes.
An implementation of the RocksDB has also been added to Spark with version 3.2. RocksDB is a database for key-value data that’s been embedded in a variety of projects, including Apache Kafka, where it helps maintain stateful data. The use case appears to be similar in Spark, as Databricks has positioned RocksDB to replace the existing state store in Structured Streaming, which it says currently is not sufficiently scalable due to the limited heap size of the executors.
Databricks has used RocksDB for four years in its in-house implementation of Spark, and now it has contributed that code back to the Apache Spark community so everybody can avail themselves of the benefits of retaining stateful data no matter how big the Spark streaming app gets. “This state store can avoid full scans by sorting keys, and serve data from the disk without relying on the heap size of executors,” Databricks writes.
Spark 3.2 gets more efficient at processing smaller data sets (Image source: Databricks)
The final big improvement in Spark 3.2 is the enablement Adaptive Query Execution (AQE) by default. AQE, which was introduced with Spark 3.0, used several technical to boost performance of Spark workloads, including dynamically coalescing shuffle partitions to limit the need to tune the number of shuffle partitions; dynamically switching join strategies to avoid executing suboptimal plans due to missing statistics; and dynamically optimizing skew joins to help avoid extreme imbalances of work.
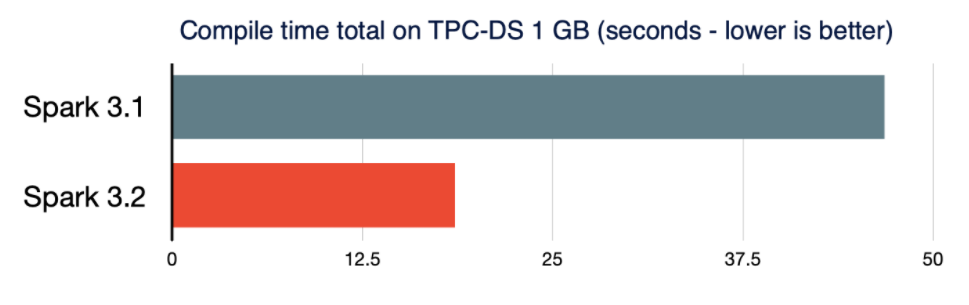
Spark 3.2 also brings better performance for small data environments. The overhead of Spark query compilation can hurt performance when the volume of processed data is considerably small, Databricks says. To further reduce the query compilation latency, Spark now prunes unnecessary query plan traversals in analyzer/optimizer rules and speeds up the construction of new query plans, the company says. “As a result, the compile time of TPC-DS queries is reduced by 61%, compared to Spark 3.1.2,” the engineers write.
Spark is open source and can be downloaded for free at spark.apache.org/.
Related Items:
What’s Driving Python’s Massive Popularity?
Databricks Sees Lakehouse Validation in $1.6 Billion Round
Spark 3.0 Brings Big SQL Speed-Up, Better Python Hooks
Technologies:
Frameworks
Vendors:
Databricks
Leading Solution Providers
















